 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARD: Defending Harmful Fine-Tuning Attack via Safety Projection with Relevance-Diversity Data Selection
May 27, 2026Fine-tuning large language models often undermines their safety alignment, a problem further amplified by harmful fine-tuning attacks in which adversarial data removes safeguards and induces unsafe behaviors. We propose SPARD, a defense framework that integrates Safety-Projected Alternating optimization with Relevance-Diversity aware data selection. SPARD employs SPAG, which optimizes alternatively between utility updates and explicit safety projections with a set of safe data to enforce safety constraints. To curate safe data, we introduce a Relevance-Diversity Determinantal Point Process to select compact safe data, balancing task relevance and safety coverage. Experiments on GSM8K and OpenBookQA under four harmful fine-tuning attacks demonstrate that SPARD consistently achieves the lowest average attack success rates, substantially outperforming state-of-the-art defense methods, while maintaining high task accuracy. Code is available at https://github.com/shuhao02/SPARD.
Reinforcing 3D Understanding in Point-VLMs via Geometric Reward Credit Assignment
Apr 23, 2026Point-Vision-Language Models promise to empower embodied agents with executable spatial reasoning, yet they frequently succumb to geometric hallucination where predicted 3D structures contradict the observed 2D reality. We identify a key cause of this failure not as a representation bottleneck but as a structural misalignment in reinforcement learning, where sparse geometric tokens are drowned out by noisy and broadcasted sequence-level rewards. To resolve this causal dilution, we propose Geometric Reward Credit Assignment, a framework that disentangles holistic supervision into field-specific signals and routes them exclusively to their responsible token spans. This mechanism transforms vague feedback into precise gradient updates and effectively turns generic policy optimization into targeted structural alignment. Furthermore, we internalize physical constraints via a Reprojection-Consistency term which serves as a cross-modal verifier to penalize physically impossible geometries. Validated on a calibrated benchmark derived from ShapeNetCore, our approach bridges the reliability gap by boosting 3D KPA from 0.64 to 0.93, increasing 3D bounding box intersection over union to 0.686, and raising reprojection consistency scores to 0.852. Crucially, these gains are achieved while maintaining robust 2D localization performance, marking a meaningful step from plausible textual outputs toward physically verifiable spatial predictions.
WorldGenBench: A World-Knowledge-Integrated Benchmark for Reasoning-Driven Text-to-Image Generation
May 02, 2025Recent advances in text-to-image (T2I) generation have achieved impressive results, yet existing models still struggle with prompts that require rich world knowledge and implicit reasoning: both of which are critical for producing semantically accurate, coherent, and contextually appropriate images in real-world scenarios. To address this gap, we introduce \textbf{WorldGenBench}, a benchmark designed to systematically evaluate T2I models' world knowledge grounding and implicit inferential capabilities, covering both the humanities and nature domains. We propose the \textbf{Knowledge Checklist Score}, a structured metric that measures how well generated images satisfy key semantic expectations. Experiments across 21 state-of-the-art models reveal that while diffusion models lead among open-source methods, proprietary auto-regressive models like GPT-4o exhibit significantly stronger reasoning and knowledge integration. Our findings highlight the need for deeper understanding and inference capabilities in next-generation T2I systems. Project Page: \href{https://dwanzhang-ai.github.io/WorldGenBench/}{https://dwanzhang-ai.github.io/WorldGenBench/}
Hengqin-RA-v1: Advanced Large Language Model for Diagnosis and Treatment of Rheumatoid Arthritis with Dataset based Traditional Chinese Medicine
Jan 05, 2025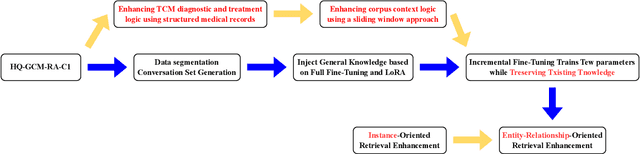
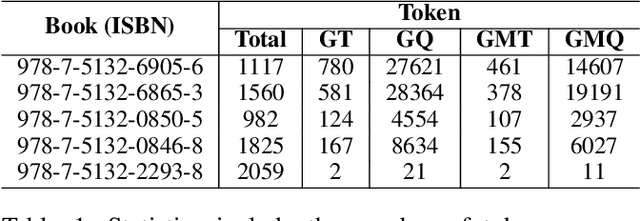
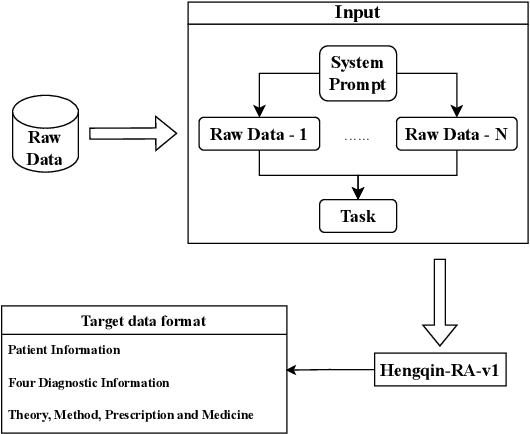
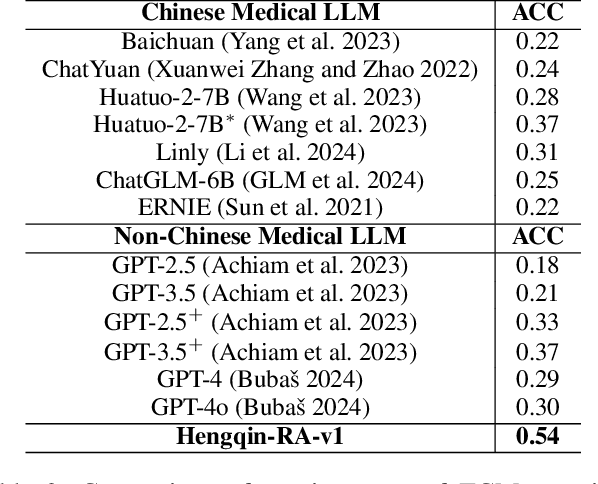
Large language models (LLMs) primarily trained on English texts, often face biases and inaccuracies in Chinese contexts. Their limitations are pronounced in fields like Traditional Chinese Medicine (TCM), where cultural and clinical subtleties are vital, further hindered by a lack of domain-specific data, such as rheumatoid arthritis (RA). To address these issues, this paper introduces Hengqin-RA-v1, the first large language model specifically tailored for TCM with a focus on diagnosing and treating RA. We also present HQ-GCM-RA-C1, a comprehensive RA-specific dataset curated from ancient Chinese medical literature, classical texts, and modern clinical studies. This dataset empowers Hengqin-RA-v1 to deliver accurate and culturally informed responses, effectively bridging the gaps left by general-purpose models. Extensive experiments demonstrate that Hengqin-RA-v1 outperforms state-of-the-art models, even surpassing the diagnostic accuracy of TCM practitioners in certain cases.
Gradient-Guided Modality Decoupling for Missing-Modality Robustness
Feb 26, 2024


Multimodal learning with incomplete input data (missing modality) is practical and challenging. In this work, we conduct an in-depth analysis of this challenge and find that modality dominance has a significant negative impact on the model training, greatly degrading the missing modality performance. Motivated by Grad-CAM, we introduce a novel indicator, gradients, to monitor and reduce modality dominance which widely exists in the missing-modality scenario. In aid of this indicator, we present a novel Gradient-guided Modality Decoupling (GMD) method to decouple the dependency on dominating modalities. Specifically, GMD removes the conflicted gradient components from different modalities to achieve this decoupling, significantly improving the performance. In addition, to flexibly handle modal-incomplete data, we design a parameter-efficient Dynamic Sharing (DS) framework which can adaptively switch on/off the network parameters based on whether one modality is available. We conduct extensive experiments on three popular multimodal benchmarks, including BraTS 2018 for medical segmentation, CMU-MOSI, and CMU-MOSEI for sentiment analysis. The results show that our method can significantly outperform the competitors, showing the effectiveness of the proposed solutions. Our code is released here: https://github.com/HaoWang420/Gradient-guided-Modality-Decoupling.
Strip-MLP: Efficient Token Interaction for Vision MLP
Jul 21, 2023



Token interaction operation is one of the core modules in MLP-based models to exchange and aggregate information between different spatial locations. However, the power of token interaction on the spatial dimension is highly dependent on the spatial resolution of the feature maps, which limits the model's expressive ability, especially in deep layers where the feature are down-sampled to a small spatial size. To address this issue, we present a novel method called \textbf{Strip-MLP} to enrich the token interaction power in three ways. Firstly, we introduce a new MLP paradigm called Strip MLP layer that allows the token to interact with other tokens in a cross-strip manner, enabling the tokens in a row (or column) to contribute to the information aggregations in adjacent but different strips of rows (or columns). Secondly, a \textbf{C}ascade \textbf{G}roup \textbf{S}trip \textbf{M}ixing \textbf{M}odule (CGSMM) is proposed to overcome the performance degradation caused by small spatial feature size. The module allows tokens to interact more effectively in the manners of within-patch and cross-patch, which is independent to the feature spatial size. Finally, based on the Strip MLP layer, we propose a novel \textbf{L}ocal \textbf{S}trip \textbf{M}ixing \textbf{M}odule (LSMM) to boost the token interaction power in the local region. Extensive experiments demonstrate that Strip-MLP significantly improves the performance of MLP-based models on small datasets and obtains comparable or even better results on ImageNet. In particular, Strip-MLP models achieve higher average Top-1 accuracy than existing MLP-based models by +2.44\% on Caltech-101 and +2.16\% on CIFAR-100. The source codes will be available at~\href{https://github.com/Med-Process/Strip_MLP{https://github.com/Med-Process/Strip\_MLP}.