 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNirvana: A Specialized Generalist Model With Task-Aware Memory Mechanism
Oct 30, 2025Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($\textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task's requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($\textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana's performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs' backbone, and can also generate accurate preliminary clinical reports accordingly.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
AdsQA: Towards Advertisement Video Understanding
Sep 10, 2025Large language models (LLMs) have taken a great step towards AGI. Meanwhile, an increasing number of domain-specific problems such as math and programming boost these general-purpose models to continuously evolve via learning deeper expertise. Now is thus the time further to extend the diversity of specialized applications for knowledgeable LLMs, though collecting high quality data with unexpected and informative tasks is challenging. In this paper, we propose to use advertisement (ad) videos as a challenging test-bed to probe the ability of LLMs in perceiving beyond the objective physical content of common visual domain. Our motivation is to take full advantage of the clue-rich and information-dense ad videos' traits, e.g., marketing logic, persuasive strategies, and audience engagement. Our contribution is three-fold: (1) To our knowledge, this is the first attempt to use ad videos with well-designed tasks to evaluate LLMs. We contribute AdsQA, a challenging ad Video QA benchmark derived from 1,544 ad videos with 10,962 clips, totaling 22.7 hours, providing 5 challenging tasks. (2) We propose ReAd-R, a Deepseek-R1 styled RL model that reflects on questions, and generates answers via reward-driven optimization. (3) We benchmark 14 top-tier LLMs on AdsQA, and our \texttt{ReAd-R}~achieves the state-of-the-art outperforming strong competitors equipped with long-chain reasoning capabilities by a clear margin.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Context-Aware Autoregressive Models for Multi-Conditional Image Generation
May 18, 2025Autoregressive transformers have recently shown impressive image generation quality and efficiency on par with state-of-the-art diffusion models. Unlike diffusion architectures, autoregressive models can naturally incorporate arbitrary modalities into a single, unified token sequence--offering a concise solution for multi-conditional image generation tasks. In this work, we propose $\textbf{ContextAR}$, a flexible and effective framework for multi-conditional image generation. ContextAR embeds diverse conditions (e.g., canny edges, depth maps, poses) directly into the token sequence, preserving modality-specific semantics. To maintain spatial alignment while enhancing discrimination among different condition types, we introduce hybrid positional encodings that fuse Rotary Position Embedding with Learnable Positional Embedding. We design Conditional Context-aware Attention to reduces computational complexity while preserving effective intra-condition perception. Without any fine-tuning, ContextAR supports arbitrary combinations of conditions during inference time. Experimental results demonstrate the powerful controllability and versatility of our approach, and show that the competitive perpormance than diffusion-based multi-conditional control approaches the existing autoregressive baseline across diverse multi-condition driven scenarios. Project page: $\href{https://context-ar.github.io/}{https://context-ar.github.io/.}$
WorldGenBench: A World-Knowledge-Integrated Benchmark for Reasoning-Driven Text-to-Image Generation
May 02, 2025Recent advances in text-to-image (T2I) generation have achieved impressive results, yet existing models still struggle with prompts that require rich world knowledge and implicit reasoning: both of which are critical for producing semantically accurate, coherent, and contextually appropriate images in real-world scenarios. To address this gap, we introduce \textbf{WorldGenBench}, a benchmark designed to systematically evaluate T2I models' world knowledge grounding and implicit inferential capabilities, covering both the humanities and nature domains. We propose the \textbf{Knowledge Checklist Score}, a structured metric that measures how well generated images satisfy key semantic expectations. Experiments across 21 state-of-the-art models reveal that while diffusion models lead among open-source methods, proprietary auto-regressive models like GPT-4o exhibit significantly stronger reasoning and knowledge integration. Our findings highlight the need for deeper understanding and inference capabilities in next-generation T2I systems. Project Page: \href{https://dwanzhang-ai.github.io/WorldGenBench/}{https://dwanzhang-ai.github.io/WorldGenBench/}
Fourier Position Embedding: Enhancing Attention's Periodic Extension for Length Generalization
Dec 23, 2024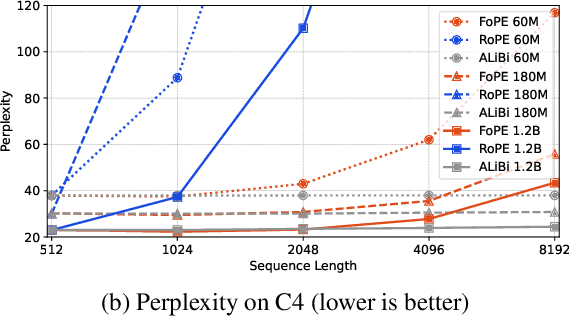
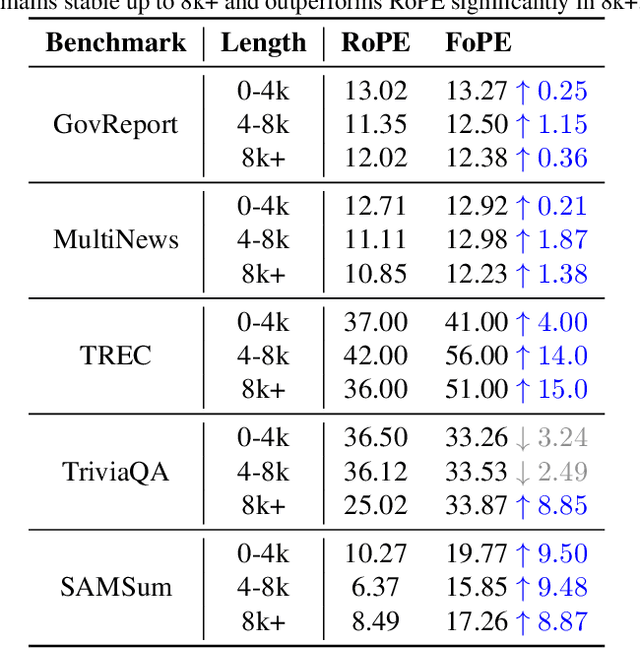
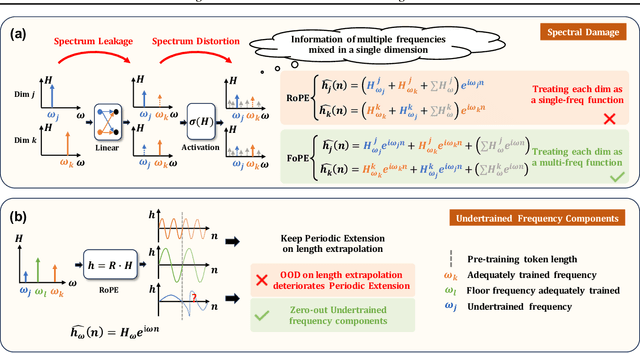
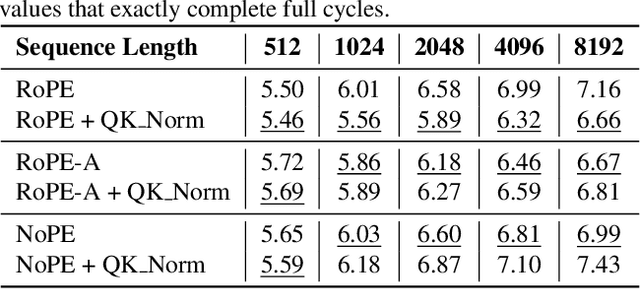
Extending the context length of Language Models (LMs) by improving Rotary Position Embedding (RoPE) has become a trend. While existing works mainly address RoPE's limitations within attention mechanism, this paper provides an analysis across nearly all parts of LMs, uncovering their adverse effects on length generalization for RoPE-based attention. Using Discrete Signal Processing theory, we show that RoPE enables periodic attention by implicitly achieving Non-Uniform Discrete Fourier Transform. However, this periodicity is undermined by the spectral damage caused by: 1) linear layers and activation functions outside of attention; 2) insufficiently trained frequency components brought by time-domain truncation. Building on our observations, we propose Fourier Position Embedding (FoPE), which enhances attention's frequency-domain properties to improve both its periodic extension and length generalization. FoPE constructs Fourier Series and zero-outs the destructive frequency components, increasing model robustness against the spectrum damage. Experiments across various model scales show that, within varying context windows, FoPE can maintain a more stable perplexity and a more consistent accuracy in a needle-in-haystack task compared to RoPE and ALiBi. Several analyses and ablations bring further support to our method and theoretical modeling.
On the token distance modeling ability of higher RoPE attention dimension
Oct 11, 2024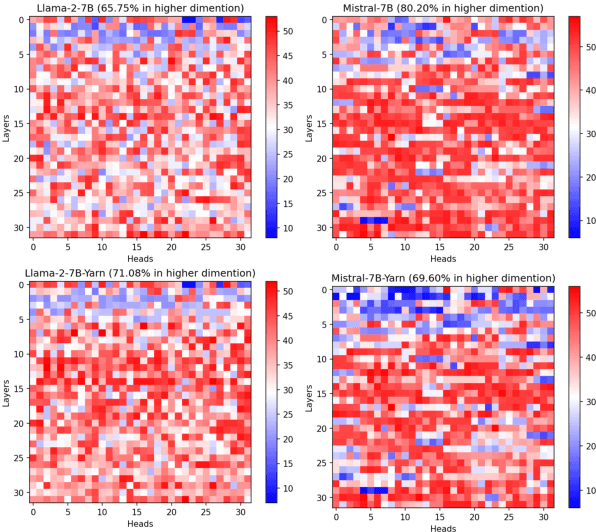
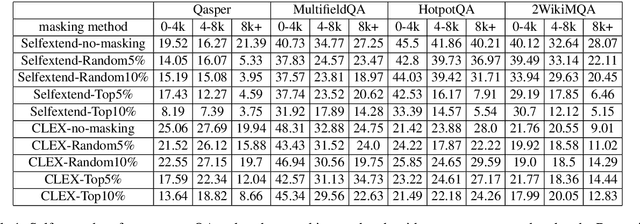
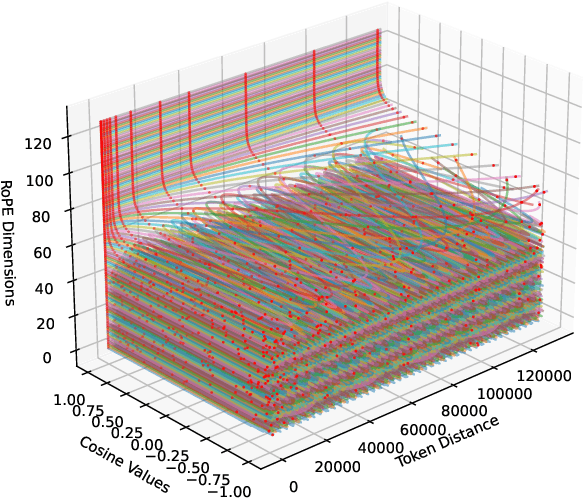
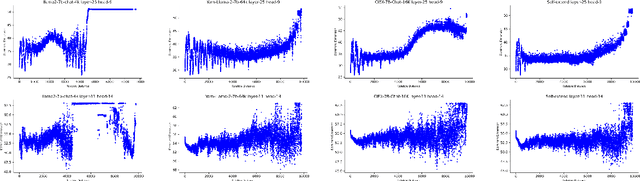
Length extrapolation algorithms based on Rotary position embedding (RoPE) have shown promising results in extending the context length of language models. However, understanding how position embedding can capture longer-range contextual information remains elusive. Based on the intuition that different dimensions correspond to different frequency of changes in RoPE encoding, we conducted a dimension-level analysis to investigate the correlation between a hidden dimension of an attention head and its contribution to capturing long-distance dependencies. Using our correlation metric, we identified a particular type of attention heads, which we named Positional Heads, from various length-extrapolated models. These heads exhibit a strong focus on long-range information interaction and play a pivotal role in long input processing, as evidence by our ablation. We further demonstrate the correlation between the efficiency of length extrapolation and the extension of the high-dimensional attention allocation of these heads. The identification of Positional Heads provides insights for future research in long-text comprehension.
MSI-Agent: Incorporating Multi-Scale Insight into Embodied Agents for Superior Planning and Decision-Making
Sep 25, 2024



Long-term memory is significant for agents, in which insights play a crucial role. However, the emergence of irrelevant insight and the lack of general insight can greatly undermine the effectiveness of insight. To solve this problem, in this paper, we introduce Multi-Scale Insight Agent (MSI-Agent), an embodied agent designed to improve LLMs' planning and decision-making ability by summarizing and utilizing insight effectively across different scales. MSI achieves this through the experience selector, insight generator, and insight selector. Leveraging a three-part pipeline, MSI can generate task-specific and high-level insight, store it in a database, and then use relevant insight from it to aid in decision-making. Our experiments show that MSI outperforms another insight strategy when planning by GPT3.5. Moreover, We delve into the strategies for selecting seed experience and insight, aiming to provide LLM with more useful and relevant insight for better decision-making. Our observations also indicate that MSI exhibits better robustness when facing domain-shifting scenarios.
On Large Language Models' Hallucination with Regard to Known Facts
Mar 29, 2024



Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88\% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.