 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Jan 22, 2026Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/
TidyBot++: An Open-Source Holonomic Mobile Manipulator for Robot Learning
Dec 11, 2024
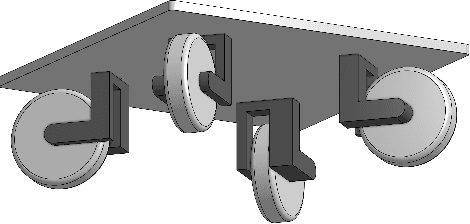

Exploiting the promise of recent advances in imitation learning for mobile manipulation will require the collection of large numbers of human-guided demonstrations. This paper proposes an open-source design for an inexpensive, robust, and flexible mobile manipulator that can support arbitrary arms, enabling a wide range of real-world household mobile manipulation tasks. Crucially, our design uses powered casters to enable the mobile base to be fully holonomic, able to control all planar degrees of freedom independently and simultaneously. This feature makes the base more maneuverable and simplifies many mobile manipulation tasks, eliminating the kinematic constraints that create complex and time-consuming motions in nonholonomic bases. We equip our robot with an intuitive mobile phone teleoperation interface to enable easy data acquisition for imitation learning. In our experiments, we use this interface to collect data and show that the resulting learned policies can successfully perform a variety of common household mobile manipulation tasks.
MSI-Agent: Incorporating Multi-Scale Insight into Embodied Agents for Superior Planning and Decision-Making
Sep 25, 2024



Long-term memory is significant for agents, in which insights play a crucial role. However, the emergence of irrelevant insight and the lack of general insight can greatly undermine the effectiveness of insight. To solve this problem, in this paper, we introduce Multi-Scale Insight Agent (MSI-Agent), an embodied agent designed to improve LLMs' planning and decision-making ability by summarizing and utilizing insight effectively across different scales. MSI achieves this through the experience selector, insight generator, and insight selector. Leveraging a three-part pipeline, MSI can generate task-specific and high-level insight, store it in a database, and then use relevant insight from it to aid in decision-making. Our experiments show that MSI outperforms another insight strategy when planning by GPT3.5. Moreover, We delve into the strategies for selecting seed experience and insight, aiming to provide LLM with more useful and relevant insight for better decision-making. Our observations also indicate that MSI exhibits better robustness when facing domain-shifting scenarios.
UMI on Legs: Making Manipulation Policies Mobile with Manipulation-Centric Whole-body Controllers
Jul 14, 2024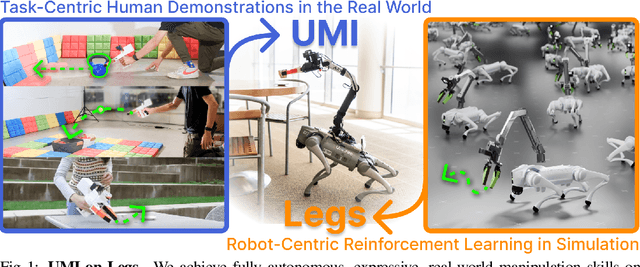
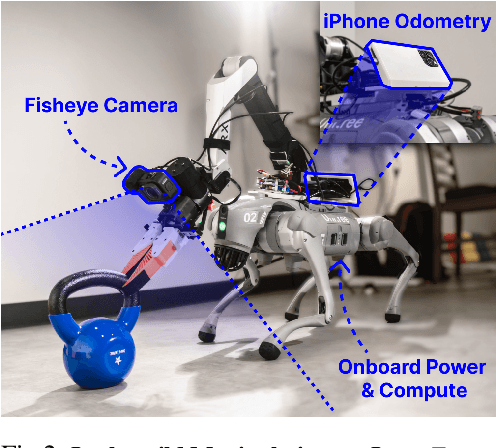

We introduce UMI-on-Legs, a new framework that combines real-world and simulation data for quadruped manipulation systems. We scale task-centric data collection in the real world using a hand-held gripper (UMI), providing a cheap way to demonstrate task-relevant manipulation skills without a robot. Simultaneously, we scale robot-centric data in simulation by training whole-body controller for task-tracking without task simulation setups. The interface between these two policies is end-effector trajectories in the task frame, inferred by the manipulation policy and passed to the whole-body controller for tracking. We evaluate UMI-on-Legs on prehensile, non-prehensile, and dynamic manipulation tasks, and report over 70% success rate on all tasks. Lastly, we demonstrate the zero-shot cross-embodiment deployment of a pre-trained manipulation policy checkpoint from prior work, originally intended for a fixed-base robot arm, on our quadruped system. We believe this framework provides a scalable path towards learning expressive manipulation skills on dynamic robot embodiments. Please checkout our website for robot videos, code, and data: https://umi-on-legs.github.io
CLOSURE: Fast Quantification of Pose Uncertainty Sets
Mar 15, 2024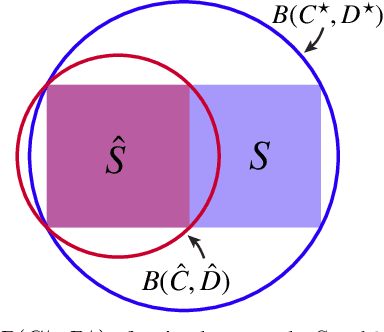
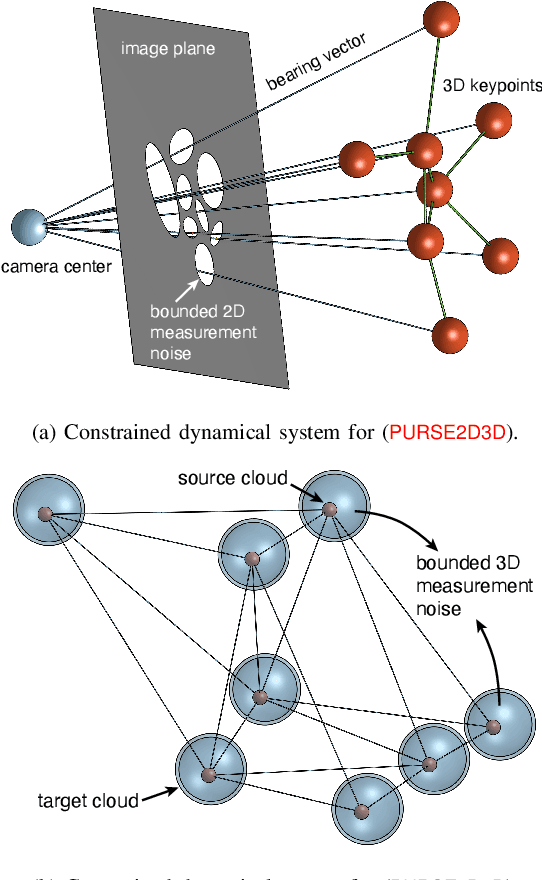
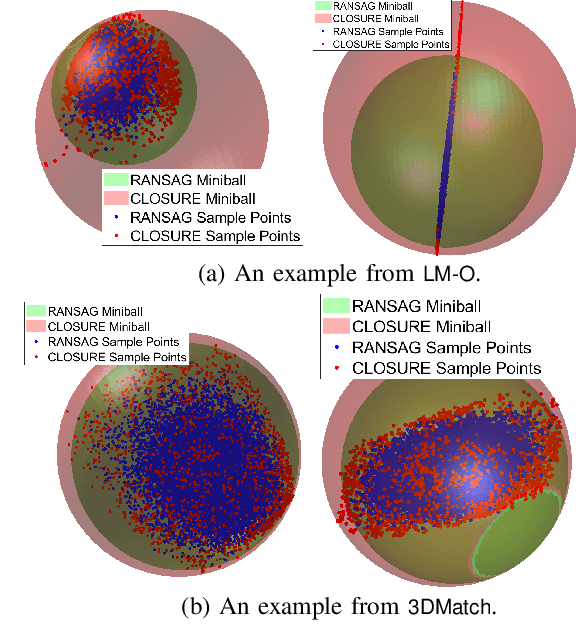
We investigate uncertainty quantification of 6D pose estimation from keypoint measurements. Assuming unknown-but-bounded measurement noises, a pose uncertainty set (PURSE) is a subset of SE(3) that contains all possible 6D poses compatible with the measurements. Despite being simple to formulate and its ability to embed uncertainty, the PURSE is difficult to manipulate and interpret due to the many abstract nonconvex polynomial constraints. An appealing simplification of PURSE is to find its minimum enclosing geodesic ball (MEGB), i.e., a point pose estimation with minimum worst-case error bound. We contribute (i) a dynamical system perspective, and (ii) a fast algorithm to inner approximate the MEGB. Particularly, we show the PURSE corresponds to the feasible set of a constrained dynamical system, and this perspective allows us to design an algorithm to densely sample the boundary of the PURSE through strategic random walks. We then use the miniball algorithm to compute the MEGB of PURSE samples, leading to an inner approximation. Our algorithm is named CLOSURE (enClosing baLl frOm purSe boUndaRy samplEs) and it enables computing a certificate of approximation tightness by calculating the relative size ratio between the inner approximation and the outer approximation. Running on a single RTX 3090 GPU, CLOSURE achieves the relative ratio of 92.8% on the LM-O object pose estimation dataset and 91.4% on the 3DMatch point cloud registration dataset with the average runtime less than 0.2 second. Obtaining comparable worst-case error bound but 398x and 833x faster than the outer approximation GRCC, CLOSURE enables uncertainty quantification of 6D pose estimation to be implemented in real-time robot perception applications.