 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are Video Models from True Multimodal Reasoning?
Apr 21, 2026Despite remarkable progress toward general-purpose video models, a critical question remains unanswered: how far are these models from achieving true multimodal reasoning? Existing benchmarks fail to address this question rigorously, as they remain constrained by straightforward task designs and fragmented evaluation metrics that neglect complex multimodal reasoning. To bridge this gap, we introduce CLVG-Bench, an evaluation framework designed to probe video models' zero-shot reasoning capabilities via Context Learning in Video Generation. CLVG-Bench comprises more than 1,000 high-quality, manually annotated metadata across 6 categories and 47 subcategories, covering complex scenarios including physical simulation, logical reasoning, and interactive contexts. To enable rigorous and scalable assessment, we further propose an Adaptive Video Evaluator (AVE) that aligns with human expert perception using minimal annotations, delivering interpretable textual feedback across diverse video context tasks. Extensive experiments reveal a striking answer to our central question: while state-of-the-art (SOTA) video models, such as Seedance 2.0, demonstrate competence on certain understanding and reasoning subtasks, they fall substantially short with logically grounded and interactive generation tasks (achieving success rates <25% and ~0%, respectively), exposing multimodal reasoning and physical grounding as critical bottlenecks. By systematically quantifying these limitations, the proposed method provides actionable feedbacks and a clear roadmap toward truly robust, general-purpose video models. CLVG-Bench and code are released here.
TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents
Jan 06, 2026Long-horizon conversational agents have to manage ever-growing interaction histories that quickly exceed the finite context windows of large language models (LLMs). Existing memory frameworks provide limited support for temporally structured information across hierarchical levels, often leading to fragmented memories and unstable long-horizon personalization. We present TiMem, a temporal--hierarchical memory framework that organizes conversations through a Temporal Memory Tree (TMT), enabling systematic memory consolidation from raw conversational observations to progressively abstracted persona representations. TiMem is characterized by three core properties: (1) temporal--hierarchical organization through TMT; (2) semantic-guided consolidation that enables memory integration across hierarchical levels without fine-tuning; and (3) complexity-aware memory recall that balances precision and efficiency across queries of varying complexity. Under a consistent evaluation setup, TiMem achieves state-of-the-art accuracy on both benchmarks, reaching 75.30% on LoCoMo and 76.88% on LongMemEval-S. It outperforms all evaluated baselines while reducing the recalled memory length by 52.20% on LoCoMo. Manifold analysis indicates clear persona separation on LoCoMo and reduced dispersion on LongMemEval-S. Overall, TiMem treats temporal continuity as a first-class organizing principle for long-horizon memory in conversational agents.
Evaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025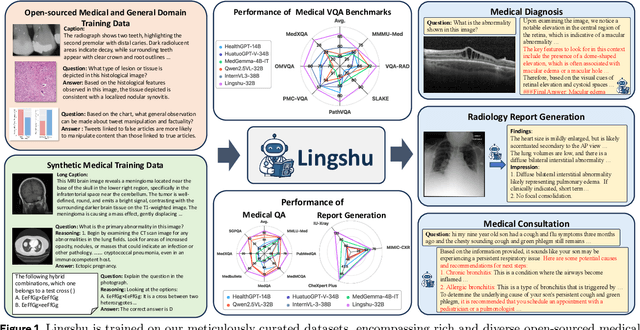
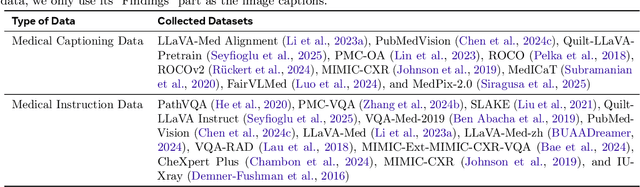
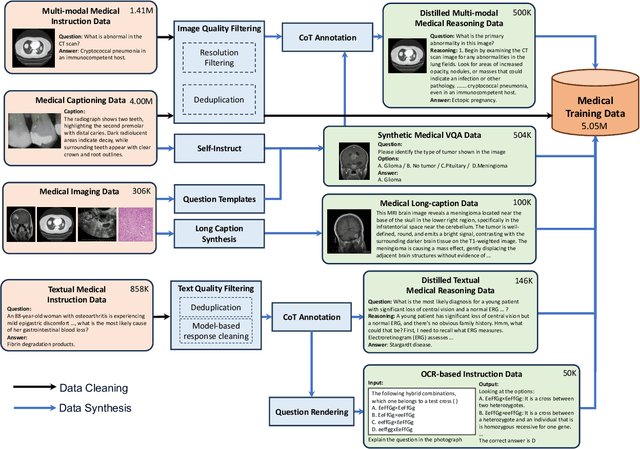

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
LocoTouch: Learning Dexterous Quadrupedal Transport with Tactile Sensing
May 29, 2025Quadrupedal robots have demonstrated remarkable agility and robustness in traversing complex terrains. However, they remain limited in performing object interactions that require sustained contact. In this work, we present LocoTouch, a system that equips quadrupedal robots with tactile sensing to address a challenging task in this category: long-distance transport of unsecured cylindrical objects, which typically requires custom mounting mechanisms to maintain stability. For efficient large-area tactile sensing, we design a high-density distributed tactile sensor array that covers the entire back of the robot. To effectively leverage tactile feedback for locomotion control, we develop a simulation environment with high-fidelity tactile signals, and train tactile-aware transport policies using a two-stage learning pipeline. Furthermore, we design a novel reward function to promote stable, symmetric, and frequency-adaptive locomotion gaits. After training in simulation, LocoTouch transfers zero-shot to the real world, reliably balancing and transporting a wide range of unsecured, cylindrical everyday objects with broadly varying sizes and weights. Thanks to the responsiveness of the tactile sensor and the adaptive gait reward, LocoTouch can robustly balance objects with slippery surfaces over long distances, or even under severe external perturbations.
Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models
Apr 17, 2025Learning to perform manipulation tasks from human videos is a promising approach for teaching robots. However, many manipulation tasks require changing control parameters during task execution, such as force, which visual data alone cannot capture. In this work, we leverage sensing devices such as armbands that measure human muscle activities and microphones that record sound, to capture the details in the human manipulation process, and enable robots to extract task plans and control parameters to perform the same task. To achieve this, we introduce Chain-of-Modality (CoM), a prompting strategy that enables Vision Language Models to reason about multimodal human demonstration data -- videos coupled with muscle or audio signals. By progressively integrating information from each modality, CoM refines a task plan and generates detailed control parameters, enabling robots to perform manipulation tasks based on a single multimodal human video prompt. Our experiments show that CoM delivers a threefold improvement in accuracy for extracting task plans and control parameters compared to baselines, with strong generalization to new task setups and objects in real-world robot experiments. Videos and code are available at https://chain-of-modality.github.io
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
QuietPaw: Learning Quadrupedal Locomotion with Versatile Noise Preference Alignment
Mar 06, 2025When operating at their full capacity, quadrupedal robots can produce loud footstep noise, which can be disruptive in human-centered environments like homes, offices, and hospitals. As a result, balancing locomotion performance with noise constraints is crucial for the successful real-world deployment of quadrupedal robots. However, achieving adaptive noise control is challenging due to (a) the trade-off between agility and noise minimization, (b) the need for generalization across diverse deployment conditions, and (c) the difficulty of effectively adjusting policies based on noise requirements. We propose QuietPaw, a framework incorporating our Conditional Noise-Constrained Policy (CNCP), a constrained learning-based algorithm that enables flexible, noise-aware locomotion by conditioning policy behavior on noise-reduction levels. We leverage value representation decomposition in the critics, disentangling state representations from condition-dependent representations and this allows a single versatile policy to generalize across noise levels without retraining while improving the Pareto trade-off between agility and noise reduction. We validate our approach in simulation and the real world, demonstrating that CNCP can effectively balance locomotion performance and noise constraints, achieving continuously adjustable noise reduction.
A2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025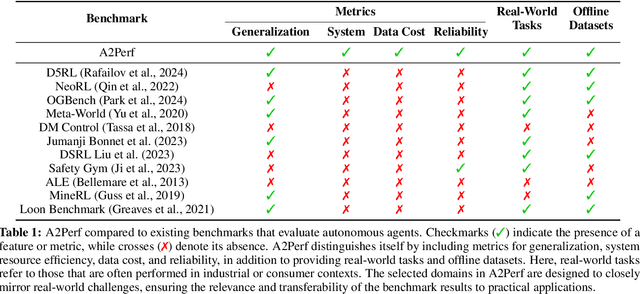

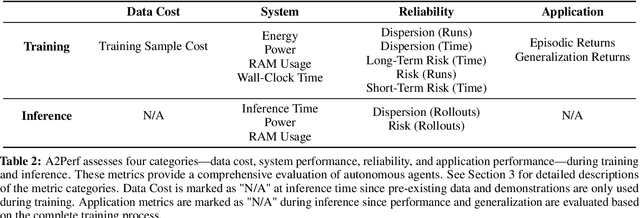

Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.
Natural Language-Assisted Multi-modal Medication Recommendation
Jan 13, 2025Combinatorial medication recommendation(CMR) is a fundamental task of healthcare, which offers opportunities for clinical physicians to provide more precise prescriptions for patients with intricate health conditions, particularly in the scenarios of long-term medical care. Previous research efforts have sought to extract meaningful information from electronic health records (EHRs) to facilitate combinatorial medication recommendations. Existing learning-based approaches further consider the chemical structures of medications, but ignore the textual medication descriptions in which the functionalities are clearly described. Furthermore, the textual knowledge derived from the EHRs of patients remains largely underutilized. To address these issues, we introduce the Natural Language-Assisted Multi-modal Medication Recommendation(NLA-MMR), a multi-modal alignment framework designed to learn knowledge from the patient view and medication view jointly. Specifically, NLA-MMR formulates CMR as an alignment problem from patient and medication modalities. In this vein, we employ pretrained language models(PLMs) to extract in-domain knowledge regarding patients and medications, serving as the foundational representation for both modalities. In the medication modality, we exploit both chemical structures and textual descriptions to create medication representations. In the patient modality, we generate the patient representations based on textual descriptions of diagnosis, procedure, and symptom. Extensive experiments conducted on three publicly accessible datasets demonstrate that NLA-MMR achieves new state-of-the-art performance, with a notable average improvement of 4.72% in Jaccard score. Our source code is publicly available on https://github.com/jtan1102/NLA-MMR_CIKM_2024.
* 10 pages