 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognition to Control - Multi-Agent Learning for Human-Humanoid Collaborative Transport
Mar 04, 2026Effective human-robot collaboration (HRC) requires translating high-level intent into contact-stable whole-body motion while continuously adapting to a human partner. Many vision-language-action (VLA) systems learn end-to-end mappings from observations and instructions to actions, but they often emphasize reactive (System 1-like) behavior and leave under-specified how sustained System 2-style deliberation can be integrated with reliable, low-latency continuous control. This gap is acute in multi-agent HRC, where long-horizon coordination decisions and physical execution must co-evolve under contact, feasibility, and safety constraints. We address this limitation with cognition-to-control (C2C), a three-layer hierarchy that makes the deliberation-to-control pathway explicit: (i) a VLM-based grounding layer that maintains persistent scene referents and infers embodiment-aware affordances/constraints; (ii) a deliberative skill/coordination layer-the System 2 core-that optimizes long-horizon skill choices and sequences under human-robot coupling via decentralized MARL cast as a Markov potential game with a shared potential encoding task progress; and (iii) a whole-body control layer that executes the selected skills at high frequency while enforcing kinematic/dynamic feasibility and contact stability. The deliberative layer is realized as a residual policy relative to a nominal controller, internalizing partner dynamics without explicit role assignment. Experiments on collaborative manipulation tasks show higher success and robustness than single-agent and end-to-end baselines, with stable coordination and emergent leader-follower behaviors.
HALyPO: Heterogeneous-Agent Lyapunov Policy Optimization for Human-Robot Collaboration
Mar 04, 2026To improve generalization and resilience in human-robot collaboration (HRC), robots must handle the combinatorial diversity of human behaviors and contexts, motivating multi-agent reinforcement learning (MARL). However, inherent heterogeneity between robots and humans creates a rationality gap (RG) in the learning process-a variational mismatch between decentralized best-response dynamics and centralized cooperative ascent. The resulting learning problem is a general-sum differentiable game, so independent policy-gradient updates can oscillate or diverge without added structure. We propose heterogeneous-agent Lyapunov policy optimization (HALyPO), which establishes formal stability directly in the policy-parameter space by enforcing a per-step Lyapunov decrease condition on a parameter-space disagreement metric. Unlike Lyapunov-based safe RL, which targets state/trajectory constraints in constrained Markov decision processes, HALyPO uses Lyapunov certification to stabilize decentralized policy learning. HALyPO rectifies decentralized gradients via optimal quadratic projections, ensuring monotonic contraction of RG and enabling effective exploration of open-ended interaction spaces. Extensive simulations and real-world humanoid-robot experiments show that this certified stability improves generalization and robustness in collaborative corner cases.
Interaction-Aware Whole-Body Control for Compliant Object Transport
Mar 04, 2026Cooperative object transport in unstructured environments remains challenging for assistive humanoids because strong, time-varying interaction forces can make tracking-centric whole-body control unreliable, especially in close-contact support tasks. This paper proposes a bio-inspired, interaction-oriented whole-body control (IO-WBC) that functions as an artificial cerebellum - an adaptive motor agent that translates upstream (skill-level) commands into stable, physically consistent whole-body behavior under contact. This work structurally separates upper-body interaction execution from lower-body support control, enabling the robot to maintain balance while shaping force exchange in a tightly coupled robot-object system. A trajectory-optimized reference generator (RG) provides a kinematic prior, while a reinforcement learning (RL) policy governs body responses under heavy-load interactions and disturbances. The policy is trained in simulation with randomized payload mass/inertia and external perturbations, and deployed via asymmetric teacher-student distillation so that the student relies only on proprioceptive histories at runtime. Extensive experiments demonstrate that IO-WBC maintains stable whole-body behavior and physical interaction even when precise velocity tracking becomes infeasible, enabling compliant object transport across a wide range of scenarios.
APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots
Feb 11, 2026Humanoid locomotion has advanced rapidly with deep reinforcement learning (DRL), enabling robust feet-based traversal over uneven terrain. Yet platforms beyond leg length remain largely out of reach because current RL training paradigms often converge to jumping-like solutions that are high-impact, torque-limited, and unsafe for real-world deployment. To address this gap, we propose APEX, a system for perceptive, climbing-based high-platform traversal that composes terrain-conditioned behaviors: climb-up and climb-down at vertical edges, walking or crawling on the platform, and stand-up and lie-down for posture reconfiguration. Central to our approach is a generalized ratchet progress reward for learning contact-rich, goal-reaching maneuvers. It tracks the best-so-far task progress and penalizes non-improving steps, providing dense yet velocity-free supervision that enables efficient exploration under strong safety regularization. Based on this formulation, we train LiDAR-based full-body maneuver policies and reduce the sim-to-real perception gap through a dual strategy: modeling mapping artifacts during training and applying filtering and inpainting to elevation maps during deployment. Finally, we distill all six skills into a single policy that autonomously selects behaviors and transitions based on local geometry and commands. Experiments on a 29-DoF Unitree G1 humanoid demonstrate zero-shot sim-to-real traversal of 0.8 meter platforms (approximately 114% of leg length), with robust adaptation to platform height and initial pose, as well as smooth and stable multi-skill transitions.
Pushing Forward Pareto Frontiers of Proactive Agents with Behavioral Agentic Optimization
Feb 11, 2026Proactive large language model (LLM) agents aim to actively plan, query, and interact over multiple turns, enabling efficient task completion beyond passive instruction following and making them essential for real-world, user-centric applications. Agentic reinforcement learning (RL) has recently emerged as a promising solution for training such agents in multi-turn settings, allowing interaction strategies to be learned from feedback. However, existing pipelines face a critical challenge in balancing task performance with user engagement, as passive agents can not efficiently adapt to users' intentions while overuse of human feedback reduces their satisfaction. To address this trade-off, we propose BAO, an agentic RL framework that combines behavior enhancement to enrich proactive reasoning and information-gathering capabilities with behavior regularization to suppress inefficient or redundant interactions and align agent behavior with user expectations. We evaluate BAO on multiple tasks from the UserRL benchmark suite, and demonstrate that it substantially outperforms proactive agentic RL baselines while achieving comparable or even superior performance to commercial LLM agents, highlighting its effectiveness for training proactive, user-aligned LLM agents in complex multi-turn scenarios. Our website: https://proactive-agentic-rl.github.io/.
LightTact: A Visual-Tactile Fingertip Sensor for Deformation-Independent Contact Sensing
Dec 23, 2025Contact often occurs without macroscopic surface deformation, such as during interaction with liquids, semi-liquids, or ultra-soft materials. Most existing tactile sensors rely on deformation to infer contact, making such light-contact interactions difficult to perceive robustly. To address this, we present LightTact, a visual-tactile fingertip sensor that makes contact directly visible via a deformation-independent, optics-based principle. LightTact uses an ambient-blocking optical configuration that suppresses both external light and internal illumination at non-contact regions, while transmitting only the diffuse light generated at true contacts. As a result, LightTact produces high-contrast raw images in which non-contact pixels remain near-black (mean gray value < 3) and contact pixels preserve the natural appearance of the contacting surface. Built on this, LightTact achieves accurate pixel-level contact segmentation that is robust to material properties, contact force, surface appearance, and environmental lighting. We further integrate LightTact on a robotic arm and demonstrate manipulation behaviors driven by extremely light contact, including water spreading, facial-cream dipping, and thin-film interaction. Finally, we show that LightTact's spatially aligned visual-tactile images can be directly interpreted by existing vision-language models, enabling resistor value reasoning for robotic sorting.
Tailored Primitive Initialization is the Secret Key to Reinforcement Learning
Nov 16, 2025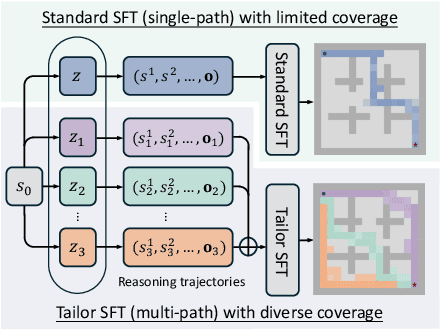

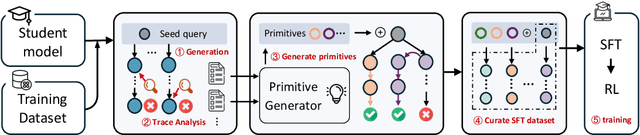
Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). While RL has demonstrated substantial performance gains, it still faces key challenges, including low sampling efficiency and a strong dependence on model initialization: some models achieve rapid improvements with minimal RL steps, while others require significant training data to make progress. In this work, we investigate these challenges through the lens of reasoning token coverage and argue that initializing LLMs with diverse, high-quality reasoning primitives is essential for achieving stable and sample-efficient RL training. We propose Tailor, a finetuning pipeline that automatically discovers and curates novel reasoning primitives, thereby expanding the coverage of reasoning-state distributions before RL. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that Tailor generates more diverse and higher-quality warm-start data, resulting in higher downstream RL performance.
Bipedalism for Quadrupedal Robots: Versatile Loco-Manipulation through Risk-Adaptive Reinforcement Learning
Jul 27, 2025Loco-manipulation of quadrupedal robots has broadened robotic applications, but using legs as manipulators often compromises locomotion, while mounting arms complicates the system. To mitigate this issue, we introduce bipedalism for quadrupedal robots, thus freeing the front legs for versatile interactions with the environment. We propose a risk-adaptive distributional Reinforcement Learning (RL) framework designed for quadrupedal robots walking on their hind legs, balancing worst-case conservativeness with optimal performance in this inherently unstable task. During training, the adaptive risk preference is dynamically adjusted based on the uncertainty of the return, measured by the coefficient of variation of the estimated return distribution. Extensive experiments in simulation show our method's superior performance over baselines. Real-world deployment on a Unitree Go2 robot further demonstrates the versatility of our policy, enabling tasks like cart pushing, obstacle probing, and payload transport, while showcasing robustness against challenging dynamics and external disturbances.
LocoTouch: Learning Dexterous Quadrupedal Transport with Tactile Sensing
May 29, 2025Quadrupedal robots have demonstrated remarkable agility and robustness in traversing complex terrains. However, they remain limited in performing object interactions that require sustained contact. In this work, we present LocoTouch, a system that equips quadrupedal robots with tactile sensing to address a challenging task in this category: long-distance transport of unsecured cylindrical objects, which typically requires custom mounting mechanisms to maintain stability. For efficient large-area tactile sensing, we design a high-density distributed tactile sensor array that covers the entire back of the robot. To effectively leverage tactile feedback for locomotion control, we develop a simulation environment with high-fidelity tactile signals, and train tactile-aware transport policies using a two-stage learning pipeline. Furthermore, we design a novel reward function to promote stable, symmetric, and frequency-adaptive locomotion gaits. After training in simulation, LocoTouch transfers zero-shot to the real world, reliably balancing and transporting a wide range of unsecured, cylindrical everyday objects with broadly varying sizes and weights. Thanks to the responsiveness of the tactile sensor and the adaptive gait reward, LocoTouch can robustly balance objects with slippery surfaces over long distances, or even under severe external perturbations.
Behavior Injection: Preparing Language Models for Reinforcement Learning
May 25, 2025Reinforcement fine-tuning (RFT) has emerged as a powerful post-training technique to incentivize the reasoning ability of large language models (LLMs). However, LLMs can respond very inconsistently to RFT: some show substantial performance gains, while others plateau or even degrade. To understand this divergence, we analyze the per-step influence of the RL objective and identify two key conditions for effective post-training: (1) RL-informative rollout accuracy, and (2) strong data co-influence, which quantifies how much the training data affects performance on other samples. Guided by these insights, we propose behavior injection, a task-agnostic data-augmentation scheme applied prior to RL. Behavior injection enriches the supervised finetuning (SFT) data by seeding exploratory and exploitative behaviors, effectively making the model more RL-ready. We evaluate our method across two reasoning benchmarks with multiple base models. The results demonstrate that our theoretically motivated augmentation can significantly increases the performance gain from RFT over the pre-RL model.