 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Intervention Learning from Emergency Stop Interventions
Feb 03, 2026Human interventions are a common source of data in autonomous systems during testing. These interventions provide an important signal about where the current policy needs improvement, but are often noisy and incomplete. We define Robust Intervention Learning (RIL) as the problem of learning from intervention data while remaining robust to the quality and informativeness of the intervention signal. In the best case, interventions are precise and avoiding them is sufficient to solve the task, but in many realistic settings avoiding interventions is necessary but not sufficient for achieving good performance. We study robust intervention learning in the context of emergency stop interventions and propose Residual Intervention Fine-Tuning (RIFT), a residual fine-tuning algorithm that treats intervention feedback as an incomplete learning signal and explicitly combines it with a prior policy. By framing intervention learning as a fine-tuning problem, our approach leverages structure encoded in the prior policy to resolve ambiguity when intervention signals under-specify the task. We provide theoretical analysis characterizing conditions under which this formulation yields principled policy improvement, and identify regimes where intervention learning is expected to fail. Our experiments reveal that residual fine-tuning enables robust and consistent policy improvement across a range of intervention strategies and prior policy qualities, and highlight robust intervention learning as a promising direction for future work.
Long Range Navigator (LRN): Extending robot planning horizons beyond metric maps
Apr 17, 2025A robot navigating an outdoor environment with no prior knowledge of the space must rely on its local sensing to perceive its surroundings and plan. This can come in the form of a local metric map or local policy with some fixed horizon. Beyond that, there is a fog of unknown space marked with some fixed cost. A limited planning horizon can often result in myopic decisions leading the robot off course or worse, into very difficult terrain. Ideally, we would like the robot to have full knowledge that can be orders of magnitude larger than a local cost map. In practice, this is intractable due to sparse sensing information and often computationally expensive. In this work, we make a key observation that long-range navigation only necessitates identifying good frontier directions for planning instead of full map knowledge. To this end, we propose Long Range Navigator (LRN), that learns an intermediate affordance representation mapping high-dimensional camera images to `affordable' frontiers for planning, and then optimizing for maximum alignment with the desired goal. LRN notably is trained entirely on unlabeled ego-centric videos making it easy to scale and adapt to new platforms. Through extensive off-road experiments on Spot and a Big Vehicle, we find that augmenting existing navigation stacks with LRN reduces human interventions at test-time and leads to faster decision making indicating the relevance of LRN. https://personalrobotics.github.io/lrn
Causal Composition Diffusion Model for Closed-loop Traffic Generation
Dec 23, 2024Simulation is critical for safety evaluation in autonomous driving, particularly in capturing complex interactive behaviors. However, generating realistic and controllable traffic scenarios in long-tail situations remains a significant challenge. Existing generative models suffer from the conflicting objective between user-defined controllability and realism constraints, which is amplified in safety-critical contexts. In this work, we introduce the Causal Compositional Diffusion Model (CCDiff), a structure-guided diffusion framework to address these challenges. We first formulate the learning of controllable and realistic closed-loop simulation as a constrained optimization problem. Then, CCDiff maximizes controllability while adhering to realism by automatically identifying and injecting causal structures directly into the diffusion process, providing structured guidance to enhance both realism and controllability. Through rigorous evaluations on benchmark datasets and in a closed-loop simulator, CCDiff demonstrates substantial gains over state-of-the-art approaches in generating realistic and user-preferred trajectories. Our results show CCDiff's effectiveness in extracting and leveraging causal structures, showing improved closed-loop performance based on key metrics such as collision rate, off-road rate, FDE, and comfort.
DriveGPT: Scaling Autoregressive Behavior Models for Driving
Dec 19, 2024



We present DriveGPT, a scalable behavior model for autonomous driving. We model driving as a sequential decision making task, and learn a transformer model to predict future agent states as tokens in an autoregressive fashion. We scale up our model parameters and training data by multiple orders of magnitude, enabling us to explore the scaling properties in terms of dataset size, model parameters, and compute. We evaluate DriveGPT across different scales in a planning task, through both quantitative metrics and qualitative examples including closed-loop driving in complex real-world scenarios. In a separate prediction task, DriveGPT outperforms a state-of-the-art baseline and exhibits improved performance by pretraining on a large-scale dataset, further validating the benefits of data scaling.
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
Dec 19, 2024



Human drivers rely on commonsense reasoning to navigate diverse and dynamic real-world scenarios. Existing end-to-end (E2E) autonomous driving (AD) models are typically optimized to mimic driving patterns observed in data, without capturing the underlying reasoning processes. This limitation constrains their ability to handle challenging driving scenarios. To close this gap, we propose VLM-AD, a method that leverages vision-language models (VLMs) as teachers to enhance training by providing additional supervision that incorporates unstructured reasoning information and structured action labels. Such supervision enhances the model's ability to learn richer feature representations that capture the rationale behind driving patterns. Importantly, our method does not require a VLM during inference, making it practical for real-time deployment. When integrated with state-of-the-art methods, VLM-AD achieves significant improvements in planning accuracy and reduced collision rates on the nuScenes dataset.
Multi-Sample Long Range Path Planning under Sensing Uncertainty for Off-Road Autonomous Driving
Mar 17, 2024We focus on the problem of long-range dynamic replanning for off-road autonomous vehicles, where a robot plans paths through a previously unobserved environment while continuously receiving noisy local observations. An effective approach for planning under sensing uncertainty is determinization, where one converts a stochastic world into a deterministic one and plans under this simplification. This makes the planning problem tractable, but the cost of following the planned path in the real world may be different than in the determinized world. This causes collisions if the determinized world optimistically ignores obstacles, or causes unnecessarily long routes if the determinized world pessimistically imagines more obstacles. We aim to be robust to uncertainty over potential worlds while still achieving the efficiency benefits of determinization. We evaluate algorithms for dynamic replanning on a large real-world dataset of challenging long-range planning problems from the DARPA RACER program. Our method, Dynamic Replanning via Evaluating and Aggregating Multiple Samples (DREAMS), outperforms other determinization-based approaches in terms of combined traversal time and collision cost. https://sites.google.com/cs.washington.edu/dreams/
An Adaptable, Safe, and Portable Robot-Assisted Feeding System
Mar 07, 2024


We demonstrate a robot-assisted feeding system that enables people with mobility impairments to feed themselves. Our system design embodies Safety, Portability, and User Control, with comprehensive full-stack safety checks, the ability to be mounted on and powered by any powered wheelchair, and a custom web-app allowing care-recipients to leverage their own assistive devices for robot control. For bite acquisition, we leverage multi-modal online learning to tractably adapt to unseen food types. For bite transfer, we leverage real-time mouth perception and interaction-aware control. Co-designed with community researchers, our system has been validated through multiple end-user studies.
CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
Oct 19, 2023



We present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
NEWTON: Are Large Language Models Capable of Physical Reasoning?
Oct 10, 2023

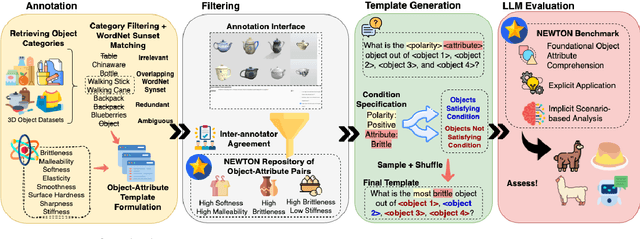
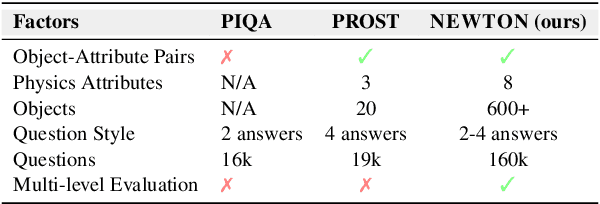
Large Language Models (LLMs), through their contextualized representations, have been empirically proven to encapsulate syntactic, semantic, word sense, and common-sense knowledge. However, there has been limited exploration of their physical reasoning abilities, specifically concerning the crucial attributes for comprehending everyday objects. To address this gap, we introduce NEWTON, a repository and benchmark for evaluating the physics reasoning skills of LLMs. Further, to enable domain-specific adaptation of this benchmark, we present a pipeline to enable researchers to generate a variant of this benchmark that has been customized to the objects and attributes relevant for their application. The NEWTON repository comprises a collection of 2800 object-attribute pairs, providing the foundation for generating infinite-scale assessment templates. The NEWTON benchmark consists of 160K QA questions, curated using the NEWTON repository to investigate the physical reasoning capabilities of several mainstream language models across foundational, explicit, and implicit reasoning tasks. Through extensive empirical analysis, our results highlight the capabilities of LLMs for physical reasoning. We find that LLMs like GPT-4 demonstrate strong reasoning capabilities in scenario-based tasks but exhibit less consistency in object-attribute reasoning compared to humans (50% vs. 84%). Furthermore, the NEWTON platform demonstrates its potential for evaluating and enhancing language models, paving the way for their integration into physically grounded settings, such as robotic manipulation. Project site: https://newtonreasoning.github.io
Cherry-Picking with Reinforcement Learning
Mar 09, 2023Grasping small objects surrounded by unstable or non-rigid material plays a crucial role in applications such as surgery, harvesting, construction, disaster recovery, and assisted feeding. This task is especially difficult when fine manipulation is required in the presence of sensor noise and perception errors; this inevitably triggers dynamic motion, which is challenging to model precisely. Circumventing the difficulty to build accurate models for contacts and dynamics, data-driven methods like reinforcement learning (RL) can optimize task performance via trial and error. Applying these methods to real robots, however, has been hindered by factors such as prohibitively high sample complexity or the high training infrastructure cost for providing resets on hardware. This work presents CherryBot, an RL system that uses chopsticks for fine manipulation that surpasses human reactiveness for some dynamic grasping tasks. By carefully designing the training paradigm and algorithm, we study how to make a real-world robot learning system sample efficient and general while reducing the human effort required for supervision. Our system shows continual improvement through 30 minutes of real-world interaction: through reactive retry, it achieves an almost 100% success rate on the demanding task of using chopsticks to grasp small objects swinging in the air. We demonstrate the reactiveness, robustness and generalizability of CherryBot to varying object shapes and dynamics (e.g., external disturbances like wind and human perturbations). Videos are available at https://goodcherrybot.github.io/.