 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL Token: Bootstrapping Online RL with Vision-Language-Action Models
Apr 24, 2026Vision-language-action (VLA) models can learn to perform diverse manipulation skills "out of the box," but achieving the precision and speed that real-world tasks demand requires further fine-tuning -- for example, via reinforcement learning (RL). We introduce a lightweight method that enables sample-efficient online RL fine-tuning of pretrained VLAs using just a few hours of real-world practice. We (1) adapt the VLA to expose an "RL token," a compact readout representation that preserves task-relevant pretrained knowledge while serving as an efficient interface for online RL, and (2) train a small actor-critic head on this RL token to refine the actions, while anchoring the learned policy to the VLA. Online RL with the RL token (RLT) makes it possible to fine-tune even large VLAs with RL quickly and efficiently. Across four real-robot tasks (screw installation, zip tie fastening, charger insertion, and Ethernet insertion), RLT improves the speed on the hardest part of the task by up to 3x and raises success rates significantly within minutes to a few hours of practice. It can even surpass the speed of human teleoperation on some of the tasks.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
Feb 26, 2025Generalist robots that can perform a range of different tasks in open-world settings must be able to not only reason about the steps needed to accomplish their goals, but also process complex instructions, prompts, and even feedback during task execution. Intricate instructions (e.g., "Could you make me a vegetarian sandwich?" or "I don't like that one") require not just the ability to physically perform the individual steps, but the ability to situate complex commands and feedback in the physical world. In this work, we describe a system that uses vision-language models in a hierarchical structure, first reasoning over complex prompts and user feedback to deduce the most appropriate next step to fulfill the task, and then performing that step with low-level actions. In contrast to direct instruction following methods that can fulfill simple commands ("pick up the cup"), our system can reason through complex prompts and incorporate situated feedback during task execution ("that's not trash"). We evaluate our system across three robotic platforms, including single-arm, dual-arm, and dual-arm mobile robots, demonstrating its ability to handle tasks such as cleaning messy tables, making sandwiches, and grocery shopping.
$π_0$: A Vision-Language-Action Flow Model for General Robot Control
Oct 31, 2024
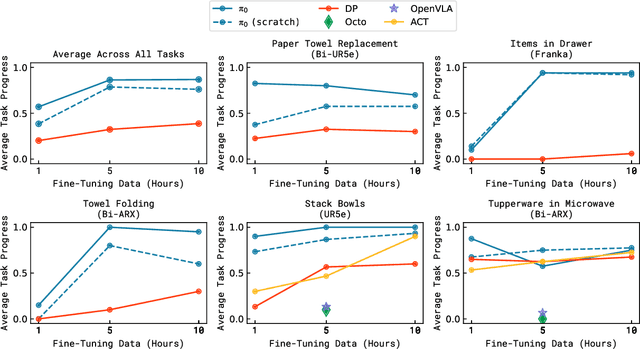

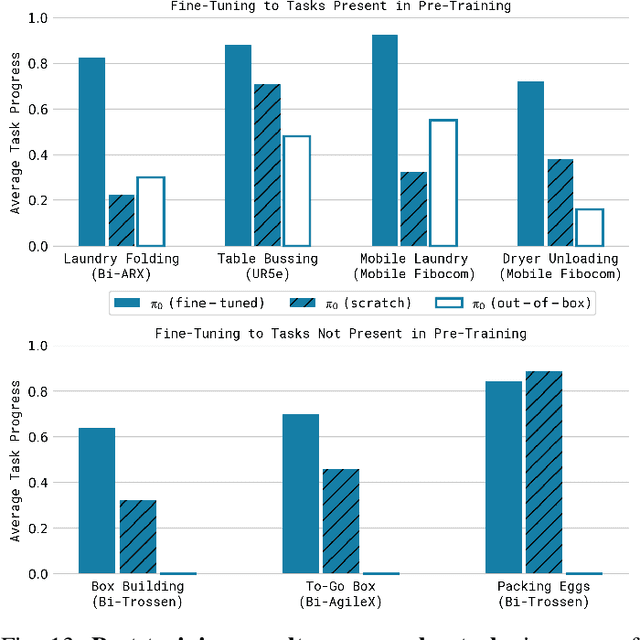
Robot learning holds tremendous promise to unlock the full potential of flexible, general, and dexterous robot systems, as well as to address some of the deepest questions in artificial intelligence. However, bringing robot learning to the level of generality required for effective real-world systems faces major obstacles in terms of data, generalization, and robustness. In this paper, we discuss how generalist robot policies (i.e., robot foundation models) can address these challenges, and how we can design effective generalist robot policies for complex and highly dexterous tasks. We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge. We then discuss how this model can be trained on a large and diverse dataset from multiple dexterous robot platforms, including single-arm robots, dual-arm robots, and mobile manipulators. We evaluate our model in terms of its ability to perform tasks in zero shot after pre-training, follow language instructions from people and from a high-level VLM policy, and its ability to acquire new skills via fine-tuning. Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes.
Overcoming the Sim-to-Real Gap: Leveraging Simulation to Learn to Explore for Real-World RL
Oct 26, 2024



In order to mitigate the sample complexity of real-world reinforcement learning, common practice is to first train a policy in a simulator where samples are cheap, and then deploy this policy in the real world, with the hope that it generalizes effectively. Such \emph{direct sim2real} transfer is not guaranteed to succeed, however, and in cases where it fails, it is unclear how to best utilize the simulator. In this work, we show that in many regimes, while direct sim2real transfer may fail, we can utilize the simulator to learn a set of \emph{exploratory} policies which enable efficient exploration in the real world. In particular, in the setting of low-rank MDPs, we show that coupling these exploratory policies with simple, practical approaches -- least-squares regression oracles and naive randomized exploration -- yields a polynomial sample complexity in the real world, an exponential improvement over direct sim2real transfer, or learning without access to a simulator. To the best of our knowledge, this is the first evidence that simulation transfer yields a provable gain in reinforcement learning in settings where direct sim2real transfer fails. We validate our theoretical results on several realistic robotic simulators and a real-world robotic sim2real task, demonstrating that transferring exploratory policies can yield substantial gains in practice as well.
Data Efficient Behavior Cloning for Fine Manipulation via Continuity-based Corrective Labels
May 29, 2024
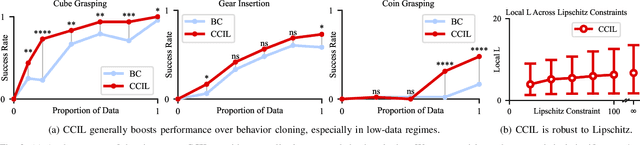
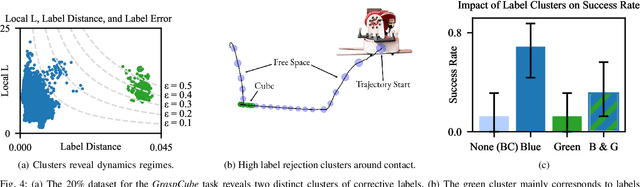
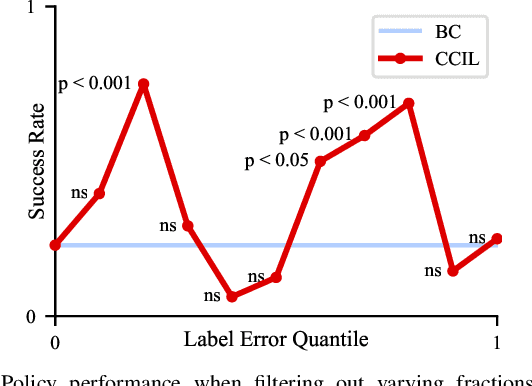
We consider imitation learning with access only to expert demonstrations, whose real-world application is often limited by covariate shift due to compounding errors during execution. We investigate the effectiveness of the Continuity-based Corrective Labels for Imitation Learning (CCIL) framework in mitigating this issue for real-world fine manipulation tasks. CCIL generates corrective labels by learning a locally continuous dynamics model from demonstrations to guide the agent back toward expert states. Through extensive experiments on peg insertion and fine grasping, we provide the first empirical validation that CCIL can significantly improve imitation learning performance despite discontinuities present in contact-rich manipulation. We find that: (1) real-world manipulation exhibits sufficient local smoothness to apply CCIL, (2) generated corrective labels are most beneficial in low-data regimes, and (3) label filtering based on estimated dynamics model error enables performance gains. To effectively apply CCIL to robotic domains, we offer a practical instantiation of the framework and insights into design choices and hyperparameter selection. Our work demonstrates CCIL's practicality for alleviating compounding errors in imitation learning on physical robots.
CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
Oct 19, 2023



We present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
Cherry-Picking with Reinforcement Learning
Mar 09, 2023
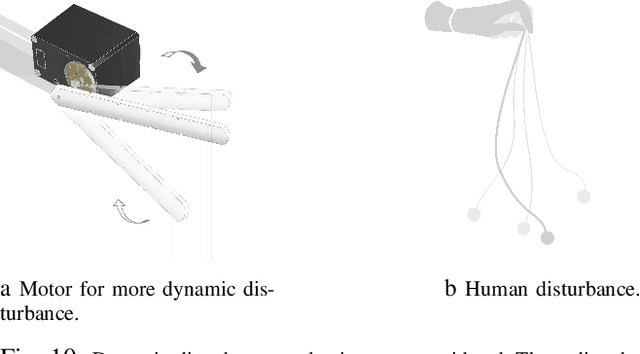


Grasping small objects surrounded by unstable or non-rigid material plays a crucial role in applications such as surgery, harvesting, construction, disaster recovery, and assisted feeding. This task is especially difficult when fine manipulation is required in the presence of sensor noise and perception errors; this inevitably triggers dynamic motion, which is challenging to model precisely. Circumventing the difficulty to build accurate models for contacts and dynamics, data-driven methods like reinforcement learning (RL) can optimize task performance via trial and error. Applying these methods to real robots, however, has been hindered by factors such as prohibitively high sample complexity or the high training infrastructure cost for providing resets on hardware. This work presents CherryBot, an RL system that uses chopsticks for fine manipulation that surpasses human reactiveness for some dynamic grasping tasks. By carefully designing the training paradigm and algorithm, we study how to make a real-world robot learning system sample efficient and general while reducing the human effort required for supervision. Our system shows continual improvement through 30 minutes of real-world interaction: through reactive retry, it achieves an almost 100% success rate on the demanding task of using chopsticks to grasp small objects swinging in the air. We demonstrate the reactiveness, robustness and generalizability of CherryBot to varying object shapes and dynamics (e.g., external disturbances like wind and human perturbations). Videos are available at https://goodcherrybot.github.io/.
Real World Offline Reinforcement Learning with Realistic Data Source
Oct 12, 2022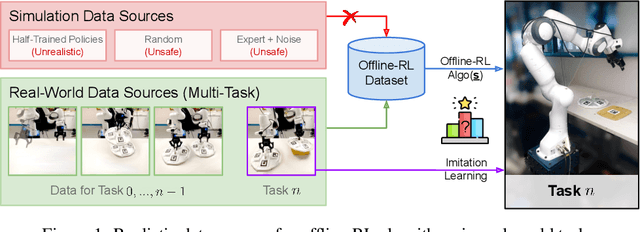

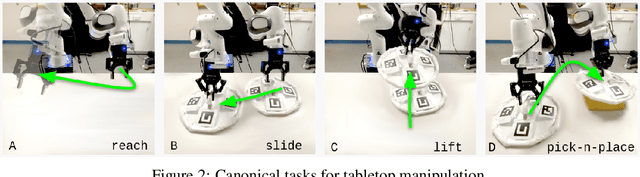

Offline reinforcement learning (ORL) holds great promise for robot learning due to its ability to learn from arbitrary pre-generated experience. However, current ORL benchmarks are almost entirely in simulation and utilize contrived datasets like replay buffers of online RL agents or sub-optimal trajectories, and thus hold limited relevance for real-world robotics. In this work (Real-ORL), we posit that data collected from safe operations of closely related tasks are more practical data sources for real-world robot learning. Under these settings, we perform an extensive (6500+ trajectories collected over 800+ robot hours and 270+ human labor hour) empirical study evaluating generalization and transfer capabilities of representative ORL methods on four real-world tabletop manipulation tasks. Our study finds that ORL and imitation learning prefer different action spaces, and that ORL algorithms can generalize from leveraging offline heterogeneous data sources and outperform imitation learning. We release our dataset and implementations at URL: https://sites.google.com/view/real-orl