 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Q-Learning: Accurate Value Learning via n-Step Inequalities
May 07, 2026Off-policy, value-based reinforcement learning methods such as Q-learning are appealing because they can learn from arbitrary experience, including data collected by older policies or other agents. In practice, however, bootstrapping makes long-horizon learning brittle: estimation errors at later states propagate backward through temporal-difference (TD) updates and can compound over time. We propose long-horizon Q-learning (LQL), which introduces a principled backstop against compounding error when learning the optimal action-value function. LQL builds on a prior optimality tightening observation: any realized action sequence lower-bounds what the optimal policy can achieve in expectation, so acting optimally earlier should not be worse than following the observed actions for several steps before switching to optimal behavior. Our contribution is to turn this inequality into a practical stabilization mechanism for Q-learning by using a hinge loss to penalize violations of these bounds. Importantly, LQL computes these penalties using network outputs already produced for the TD error, requiring no auxiliary networks and no additional forward passes relative to Q-learning. When combined with multiple state-of-the-art methods on a range of online and offline-to-online benchmarks, LQL consistently outperforms both 1-step TD and n-step TD learning at similar runtime.
VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
Feb 15, 2026The goal of this paper is to improve the performance and reliability of vision-language-action (VLA) models through iterative online interaction. Since collecting policy rollouts in the real world is expensive, we investigate whether a learned simulator-specifically, an action-conditioned video generation model-can be used to generate additional rollout data. Unfortunately, existing world models lack the physical fidelity necessary for policy improvement: they are predominantly trained on demonstration datasets that lack coverage of many different physical interactions (particularly failure cases) and struggle to accurately model small yet critical physical details in contact-rich object manipulation. We propose a simple iterative improvement algorithm that uses real-world roll-out data to improve the fidelity of the world model, which can then, in turn, be used to generate supplemental synthetic data for improving the VLA model. In our experiments on a real robot, we use this approach to improve the performance of a state-of-the-art VLA model on multiple downstream tasks. We achieve a 39.2% absolute success rate improvement over the base policy and 11.6% improvement from training with the generated synthetic rollouts. Videos can be found at this anonymous website: https://sites.google.com/view/vla-w
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better
May 29, 2025Vision-language-action (VLA) models provide a powerful approach to training control policies for physical systems, such as robots, by combining end-to-end learning with transfer of semantic knowledge from web-scale vision-language model (VLM) training. However, the constraints of real-time control are often at odds with the design of VLMs: the most powerful VLMs have tens or hundreds of billions of parameters, presenting an obstacle to real-time inference, and operate on discrete tokens rather than the continuous-valued outputs that are required for controlling robots. To address this challenge, recent VLA models have used specialized modules for efficient continuous control, such as action experts or continuous output heads, which typically require adding new untrained parameters to the pretrained VLM backbone. While these modules improve real-time and control capabilities, it remains an open question whether they preserve or degrade the semantic knowledge contained in the pretrained VLM, and what effect they have on the VLA training dynamics. In this paper, we study this question in the context of VLAs that include a continuous diffusion or flow matching action expert, showing that naively including such experts significantly harms both training speed and knowledge transfer. We provide an extensive analysis of various design choices, their impact on performance and knowledge transfer, and propose a technique for insulating the VLM backbone during VLA training that mitigates this issue. Videos are available at https://pi.website/research/knowledge_insulation.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
Feb 26, 2025Generalist robots that can perform a range of different tasks in open-world settings must be able to not only reason about the steps needed to accomplish their goals, but also process complex instructions, prompts, and even feedback during task execution. Intricate instructions (e.g., "Could you make me a vegetarian sandwich?" or "I don't like that one") require not just the ability to physically perform the individual steps, but the ability to situate complex commands and feedback in the physical world. In this work, we describe a system that uses vision-language models in a hierarchical structure, first reasoning over complex prompts and user feedback to deduce the most appropriate next step to fulfill the task, and then performing that step with low-level actions. In contrast to direct instruction following methods that can fulfill simple commands ("pick up the cup"), our system can reason through complex prompts and incorporate situated feedback during task execution ("that's not trash"). We evaluate our system across three robotic platforms, including single-arm, dual-arm, and dual-arm mobile robots, demonstrating its ability to handle tasks such as cleaning messy tables, making sandwiches, and grocery shopping.
$π_0$: A Vision-Language-Action Flow Model for General Robot Control
Oct 31, 2024
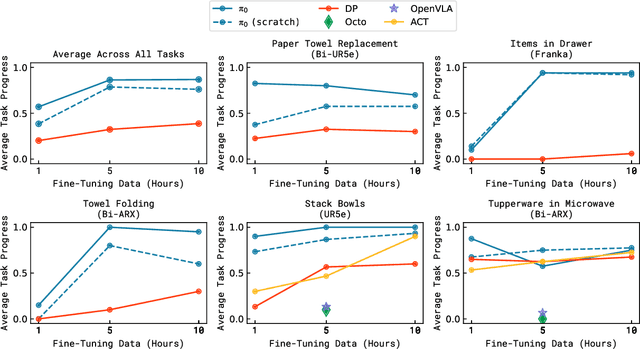

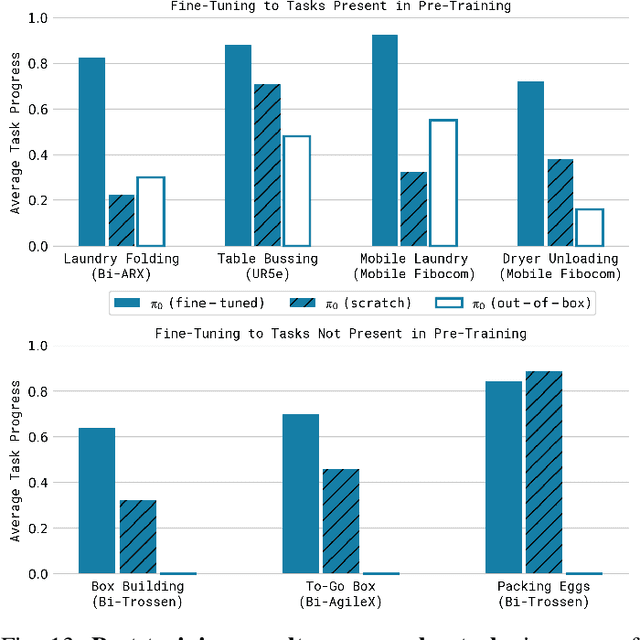
Robot learning holds tremendous promise to unlock the full potential of flexible, general, and dexterous robot systems, as well as to address some of the deepest questions in artificial intelligence. However, bringing robot learning to the level of generality required for effective real-world systems faces major obstacles in terms of data, generalization, and robustness. In this paper, we discuss how generalist robot policies (i.e., robot foundation models) can address these challenges, and how we can design effective generalist robot policies for complex and highly dexterous tasks. We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge. We then discuss how this model can be trained on a large and diverse dataset from multiple dexterous robot platforms, including single-arm robots, dual-arm robots, and mobile manipulators. We evaluate our model in terms of its ability to perform tasks in zero shot after pre-training, follow language instructions from people and from a high-level VLM policy, and its ability to acquire new skills via fine-tuning. Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes.
Yell At Your Robot: Improving On-the-Fly from Language Corrections
Mar 19, 2024Hierarchical policies that combine language and low-level control have been shown to perform impressively long-horizon robotic tasks, by leveraging either zero-shot high-level planners like pretrained language and vision-language models (LLMs/VLMs) or models trained on annotated robotic demonstrations. However, for complex and dexterous skills, attaining high success rates on long-horizon tasks still represents a major challenge -- the longer the task is, the more likely it is that some stage will fail. Can humans help the robot to continuously improve its long-horizon task performance through intuitive and natural feedback? In this paper, we make the following observation: high-level policies that index into sufficiently rich and expressive low-level language-conditioned skills can be readily supervised with human feedback in the form of language corrections. We show that even fine-grained corrections, such as small movements ("move a bit to the left"), can be effectively incorporated into high-level policies, and that such corrections can be readily obtained from humans observing the robot and making occasional suggestions. This framework enables robots not only to rapidly adapt to real-time language feedback, but also incorporate this feedback into an iterative training scheme that improves the high-level policy's ability to correct errors in both low-level execution and high-level decision-making purely from verbal feedback. Our evaluation on real hardware shows that this leads to significant performance improvement in long-horizon, dexterous manipulation tasks without the need for any additional teleoperation. Videos and code are available at https://yay-robot.github.io/.
Cross-Episodic Curriculum for Transformer Agents
Oct 12, 2023



We present a new algorithm, Cross-Episodic Curriculum (CEC), to boost the learning efficiency and generalization of Transformer agents. Central to CEC is the placement of cross-episodic experiences into a Transformer's context, which forms the basis of a curriculum. By sequentially structuring online learning trials and mixed-quality demonstrations, CEC constructs curricula that encapsulate learning progression and proficiency increase across episodes. Such synergy combined with the potent pattern recognition capabilities of Transformer models delivers a powerful cross-episodic attention mechanism. The effectiveness of CEC is demonstrated under two representative scenarios: one involving multi-task reinforcement learning with discrete control, such as in DeepMind Lab, where the curriculum captures the learning progression in both individual and progressively complex settings; and the other involving imitation learning with mixed-quality data for continuous control, as seen in RoboMimic, where the curriculum captures the improvement in demonstrators' expertise. In all instances, policies resulting from CEC exhibit superior performance and strong generalization. Code is open-sourced at https://cec-agent.github.io/ to facilitate research on Transformer agent learning.
Waypoint-Based Imitation Learning for Robotic Manipulation
Jul 26, 2023While imitation learning methods have seen a resurgent interest for robotic manipulation, the well-known problem of compounding errors continues to afflict behavioral cloning (BC). Waypoints can help address this problem by reducing the horizon of the learning problem for BC, and thus, the errors compounded over time. However, waypoint labeling is underspecified, and requires additional human supervision. Can we generate waypoints automatically without any additional human supervision? Our key insight is that if a trajectory segment can be approximated by linear motion, the endpoints can be used as waypoints. We propose Automatic Waypoint Extraction (AWE) for imitation learning, a preprocessing module to decompose a demonstration into a minimal set of waypoints which when interpolated linearly can approximate the trajectory up to a specified error threshold. AWE can be combined with any BC algorithm, and we find that AWE can increase the success rate of state-of-the-art algorithms by up to 25% in simulation and by 4-28% on real-world bimanual manipulation tasks, reducing the decision making horizon by up to a factor of 10. Videos and code are available at https://lucys0.github.io/awe/