 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEHAVIOR Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities
Mar 07, 2025Real-world household tasks present significant challenges for mobile manipulation robots. An analysis of existing robotics benchmarks reveals that successful task performance hinges on three key whole-body control capabilities: bimanual coordination, stable and precise navigation, and extensive end-effector reachability. Achieving these capabilities requires careful hardware design, but the resulting system complexity further complicates visuomotor policy learning. To address these challenges, we introduce the BEHAVIOR Robot Suite (BRS), a comprehensive framework for whole-body manipulation in diverse household tasks. Built on a bimanual, wheeled robot with a 4-DoF torso, BRS integrates a cost-effective whole-body teleoperation interface for data collection and a novel algorithm for learning whole-body visuomotor policies. We evaluate BRS on five challenging household tasks that not only emphasize the three core capabilities but also introduce additional complexities, such as long-range navigation, interaction with articulated and deformable objects, and manipulation in confined spaces. We believe that BRS's integrated robotic embodiment, data collection interface, and learning framework mark a significant step toward enabling real-world whole-body manipulation for everyday household tasks. BRS is open-sourced at https://behavior-robot-suite.github.io/
ACDC: Automated Creation of Digital Cousins for Robust Policy Learning
Oct 09, 2024



Training robot policies in the real world can be unsafe, costly, and difficult to scale. Simulation serves as an inexpensive and potentially limitless source of training data, but suffers from the semantics and physics disparity beween simulated and real-world environments. These discrepancies can be minimized by training in digital twins,which serve as virtual replicas of a real scene but are expensive to generate and cannot produce cross-domain generalization. To address these limitations, we propose the concept of digital cousins, a virtual asset or scene that, unlike a digital twin,does not explicitly model a real-world counterpart but still exhibits similar geometric and semantic affordances. As a result, digital cousins simultaneously reduce the cost of generating an analogous virtual environment while also facilitating better robustness during sim-to-real domain transfer by providing a distribution of similar training scenes. Leveraging digital cousins, we introduce a novel method for the Automatic Creation of Digital Cousins (ACDC), and propose a fully automated real-to-sim-to-real pipeline for generating fully interactive scenes and training robot policies that can be deployed zero-shot in the original scene. We find that ACDC can produce digital cousin scenes that preserve geometric and semantic affordances, and can be used to train policies that outperform policies trained on digital twins, achieving 90% vs. 25% under zero-shot sim-to-real transfer. Additional details are available at https://digital-cousins.github.io/.
TRANSIC: Sim-to-Real Policy Transfer by Learning from Online Correction
May 16, 2024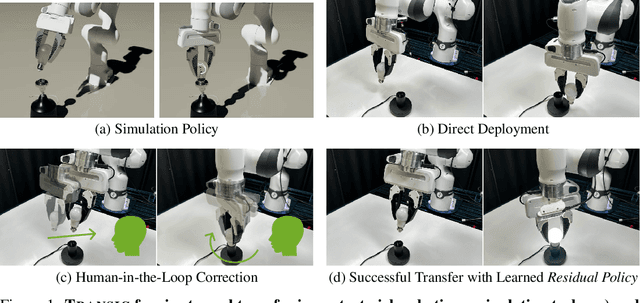



Learning in simulation and transferring the learned policy to the real world has the potential to enable generalist robots. The key challenge of this approach is to address simulation-to-reality (sim-to-real) gaps. Previous methods often require domain-specific knowledge a priori. We argue that a straightforward way to obtain such knowledge is by asking humans to observe and assist robot policy execution in the real world. The robots can then learn from humans to close various sim-to-real gaps. We propose TRANSIC, a data-driven approach to enable successful sim-to-real transfer based on a human-in-the-loop framework. TRANSIC allows humans to augment simulation policies to overcome various unmodeled sim-to-real gaps holistically through intervention and online correction. Residual policies can be learned from human corrections and integrated with simulation policies for autonomous execution. We show that our approach can achieve successful sim-to-real transfer in complex and contact-rich manipulation tasks such as furniture assembly. Through synergistic integration of policies learned in simulation and from humans, TRANSIC is effective as a holistic approach to addressing various, often coexisting sim-to-real gaps. It displays attractive properties such as scaling with human effort. Videos and code are available at https://transic-robot.github.io/
Cross-Episodic Curriculum for Transformer Agents
Oct 12, 2023We present a new algorithm, Cross-Episodic Curriculum (CEC), to boost the learning efficiency and generalization of Transformer agents. Central to CEC is the placement of cross-episodic experiences into a Transformer's context, which forms the basis of a curriculum. By sequentially structuring online learning trials and mixed-quality demonstrations, CEC constructs curricula that encapsulate learning progression and proficiency increase across episodes. Such synergy combined with the potent pattern recognition capabilities of Transformer models delivers a powerful cross-episodic attention mechanism. The effectiveness of CEC is demonstrated under two representative scenarios: one involving multi-task reinforcement learning with discrete control, such as in DeepMind Lab, where the curriculum captures the learning progression in both individual and progressively complex settings; and the other involving imitation learning with mixed-quality data for continuous control, as seen in RoboMimic, where the curriculum captures the improvement in demonstrators' expertise. In all instances, policies resulting from CEC exhibit superior performance and strong generalization. Code is open-sourced at https://cec-agent.github.io/ to facilitate research on Transformer agent learning.
Voyager: An Open-Ended Embodied Agent with Large Language Models
May 25, 2023We introduce Voyager, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Voyager consists of three key components: 1) an automatic curriculum that maximizes exploration, 2) an ever-growing skill library of executable code for storing and retrieving complex behaviors, and 3) a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement. Voyager interacts with GPT-4 via blackbox queries, which bypasses the need for model parameter fine-tuning. The skills developed by Voyager are temporally extended, interpretable, and compositional, which compounds the agent's abilities rapidly and alleviates catastrophic forgetting. Empirically, Voyager shows strong in-context lifelong learning capability and exhibits exceptional proficiency in playing Minecraft. It obtains 3.3x more unique items, travels 2.3x longer distances, and unlocks key tech tree milestones up to 15.3x faster than prior SOTA. Voyager is able to utilize the learned skill library in a new Minecraft world to solve novel tasks from scratch, while other techniques struggle to generalize. We open-source our full codebase and prompts at https://voyager.minedojo.org/.
MMA-RNN: A Multi-level Multi-task Attention-based Recurrent Neural Network for Discrimination and Localization of Atrial Fibrillation
Feb 09, 2023The automatic detection of atrial fibrillation based on electrocardiograph (ECG) signals has received wide attention both clinically and practically. It is challenging to process ECG signals with cyclical pattern, varying length and unstable quality due to noise and distortion. Besides, there has been insufficient research on separating persistent atrial fibrillation from paroxysmal atrial fibrillation, and little discussion on locating the onsets and end points of AF episodes. It is even more arduous to perform well on these two distinct but interrelated tasks, while avoiding the mistakes inherent from stage-by-stage approaches. This paper proposes the Multi-level Multi-task Attention-based Recurrent Neural Network for three-class discrimination on patients and localization of the exact timing of AF episodes. Our model captures three-level sequential features based on a hierarchical architecture utilizing Bidirectional Long and Short-Term Memory Network (Bi-LSTM) and attention layers, and accomplishes the two tasks simultaneously with a multi-head classifier. The model is designed as an end-to-end framework to enhance information interaction and reduce error accumulation. Finally, we conduct experiments on CPSC 2021 dataset and the result demonstrates the superior performance of our method, indicating the potential application of MMA-RNN to wearable mobile devices for routine AF monitoring and early diagnosis.
VIMA: General Robot Manipulation with Multimodal Prompts
Oct 06, 2022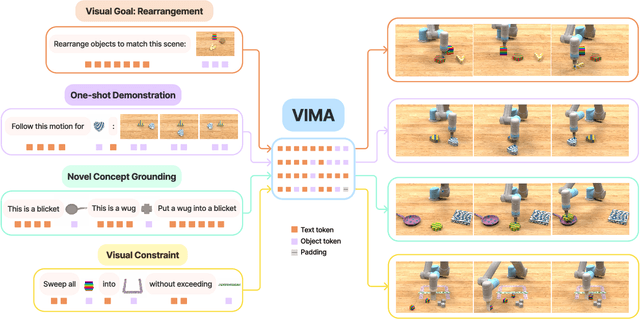
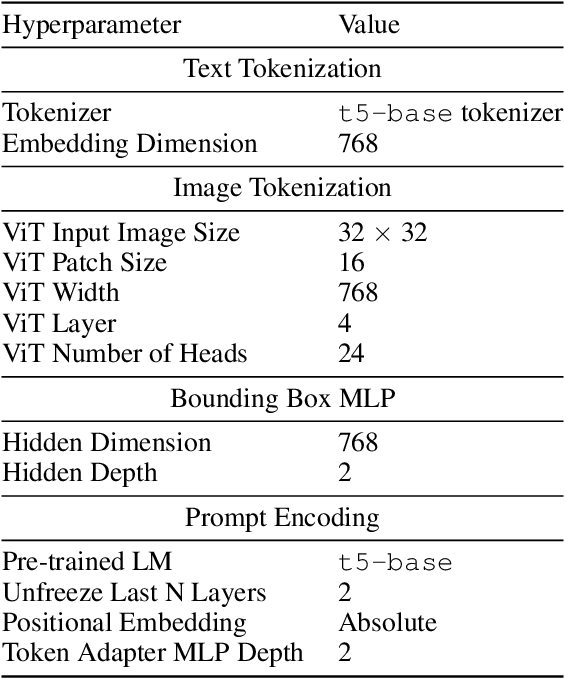
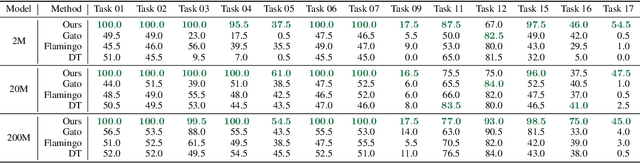
Prompt-based learning has emerged as a successful paradigm in natural language processing, where a single general-purpose language model can be instructed to perform any task specified by input prompts. Yet task specification in robotics comes in various forms, such as imitating one-shot demonstrations, following language instructions, and reaching visual goals. They are often considered different tasks and tackled by specialized models. This work shows that we can express a wide spectrum of robot manipulation tasks with multimodal prompts, interleaving textual and visual tokens. We design a transformer-based generalist robot agent, VIMA, that processes these prompts and outputs motor actions autoregressively. To train and evaluate VIMA, we develop a new simulation benchmark with thousands of procedurally-generated tabletop tasks with multimodal prompts, 600K+ expert trajectories for imitation learning, and four levels of evaluation protocol for systematic generalization. VIMA achieves strong scalability in both model capacity and data size. It outperforms prior SOTA methods in the hardest zero-shot generalization setting by up to $2.9\times$ task success rate given the same training data. With $10\times$ less training data, VIMA still performs $2.7\times$ better than the top competing approach. We open-source all code, pretrained models, dataset, and simulation benchmark at https://vimalabs.github.io
MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
Jun 17, 2022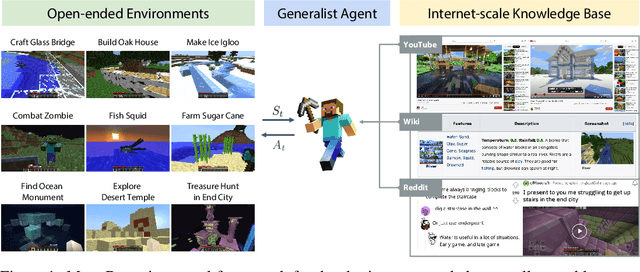
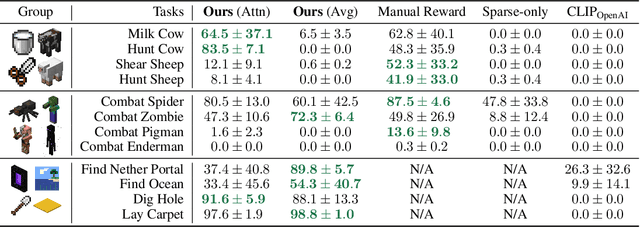
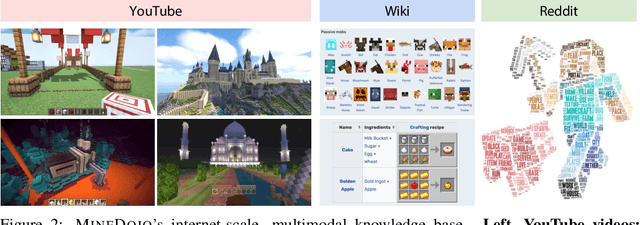

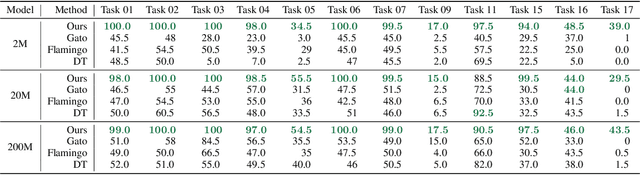
Autonomous agents have made great strides in specialist domains like Atari games and Go. However, they typically learn tabula rasa in isolated environments with limited and manually conceived objectives, thus failing to generalize across a wide spectrum of tasks and capabilities. Inspired by how humans continually learn and adapt in the open world, we advocate a trinity of ingredients for building generalist agents: 1) an environment that supports a multitude of tasks and goals, 2) a large-scale database of multimodal knowledge, and 3) a flexible and scalable agent architecture. We introduce MineDojo, a new framework built on the popular Minecraft game that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base with Minecraft videos, tutorials, wiki pages, and forum discussions. Using MineDojo's data, we propose a novel agent learning algorithm that leverages large pre-trained video-language models as a learned reward function. Our agent is able to solve a variety of open-ended tasks specified in free-form language without any manually designed dense shaping reward. We open-source the simulation suite and knowledge bases (https://minedojo.org) to promote research towards the goal of generally capable embodied agents.
Many Ways to be Lonely: Fine-grained Characterization of Loneliness and its Potential Changes in COVID-19
Jan 20, 2022
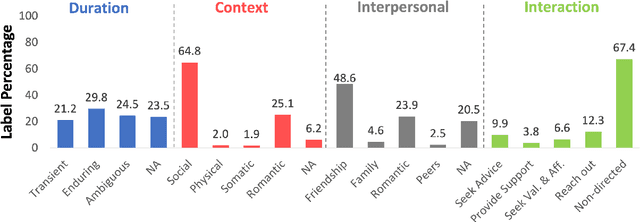
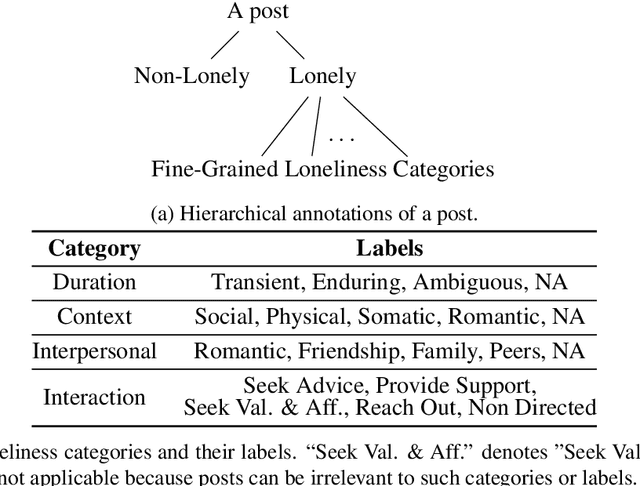
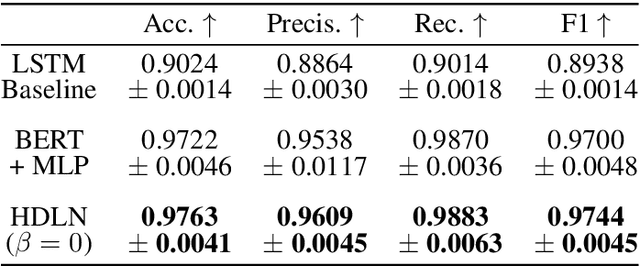
Loneliness has been associated with negative outcomes for physical and mental health. Understanding how people express and cope with various forms of loneliness is critical for early screening and targeted interventions to reduce loneliness, particularly among vulnerable groups such as young adults. To examine how different forms of loneliness and coping strategies manifest in loneliness self-disclosure, we built a dataset, FIG-Loneliness (FIne-Grained Loneliness) by using Reddit posts in two young adult-focused forums and two loneliness related forums consisting of a diverse age group. We provide annotations by trained human annotators for binary and fine-grained loneliness classifications of the posts. Trained on FIG-Loneliness, two BERT-based models were used to understand loneliness forms and authors' coping strategies in these forums. Our binary loneliness classification archived an accuracy above 97%, and fine-grained loneliness category classification reached an average accuracy of 77% across all labeled categories. With FIG-Loneliness and model predictions, we found that loneliness expressions in the young adult related forums are distinct from other forums. Those in young adult-focused forums are more likely to express concerns pertaining to peer relationship, and are potentially more sensitive to geographical isolation impacted by the COVID-19 pandemic lockdown. Also, we show that different forms of loneliness have differential use in coping strategies.