 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCanvas: A Diffusion-base Unified Model for Text-in-Image Joint Generation
Jun 02, 2026Recent years have seen remarkable progress in unified vision-language models handling both multimodal understanding and generation within a single architecture. While autoregressive VLMs can reason across modalities, they fail to generate high-quality images. In contrast, diffusion models produce photorealistic visuals yet struggle to generate coherent text, making it challenging to develop a single unified model that can seamlessly handle both visual and text generation. Recent advances suggest that language can be effectively embedded within visual representations, allowing models to reason about textual semantics directly from images. To this end, we propose UniCanvas, a first attempt that unifies diffusion models to generate interleaved multimodal contents through text-in-image generation. Diffusion models naturally capture transformations on a shared pixel canvas, which can be viewed as world models of visual change. Instead of producing discrete text tokens, the model learns to represent language as visual patterns inside images, leveraging its inherent multimodal embedding space. This design allows the model to "draw" text naturally within a single pixel canvas during image synthesis, achieving seamless multimodal generation. Experiments demonstrate that UniCanvas improves performance over previous unified models, positioning text-in-image generation with diffusion models as a promising unified multimodal generation paradigm.
Fast Spatial Memory with Elastic Test-Time Training
Apr 08, 2026Large Chunk Test-Time Training (LaCT) has shown strong performance on long-context 3D reconstruction, but its fully plastic inference-time updates remain vulnerable to catastrophic forgetting and overfitting. As a result, LaCT is typically instantiated with a single large chunk spanning the full input sequence, falling short of the broader goal of handling arbitrarily long sequences in a single pass. We propose Elastic Test-Time Training inspired by elastic weight consolidation, that stabilizes LaCT fast-weight updates with a Fisher-weighted elastic prior around a maintained anchor state. The anchor evolves as an exponential moving average of past fast weights to balance stability and plasticity. Based on this updated architecture, we introduce Fast Spatial Memory (FSM), an efficient and scalable model for 4D reconstruction that learns spatiotemporal representations from long observation sequences and renders novel view-time combinations. We pre-trained FSM on large-scale curated 3D/4D data to capture the dynamics and semantics of complex spatial environments. Extensive experiments show that FSM supports fast adaptation over long sequences and delivers high-quality 3D/4D reconstruction with smaller chunks and mitigating the camera-interpolation shortcut. Overall, we hope to advance LaCT beyond the bounded single-chunk setting toward robust multi-chunk adaptation, a necessary step for generalization to genuinely longer sequences, while substantially alleviating the activation-memory bottleneck.
Action Images: End-to-End Policy Learning via Multiview Video Generation
Apr 07, 2026World action models (WAMs) have emerged as a promising direction for robot policy learning, as they can leverage powerful video backbones to model the future states. However, existing approaches often rely on separate action modules, or use action representations that are not pixel-grounded, making it difficult to fully exploit the pretrained knowledge of video models and limiting transfer across viewpoints and environments. In this work, we present Action Images, a unified world action model that formulates policy learning as multiview video generation. Instead of encoding control as low-dimensional tokens, we translate 7-DoF robot actions into interpretable action images: multi-view action videos that are grounded in 2D pixels and explicitly track robot-arm motion. This pixel-grounded action representation allows the video backbone itself to act as a zero-shot policy, without a separate policy head or action module. Beyond control, the same unified model supports video-action joint generation, action-conditioned video generation, and action labeling under a shared representation. On RLBench and real-world evaluations, our model achieves the strongest zero-shot success rates and improves video-action joint generation quality over prior video-space world models, suggesting that interpretable action images are a promising route to policy learning.
Learning 3D Persistent Embodied World Models
May 05, 2025
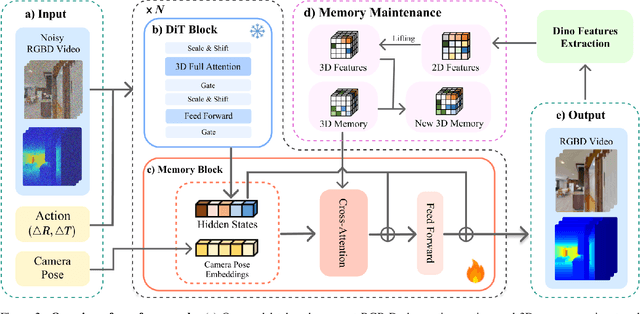
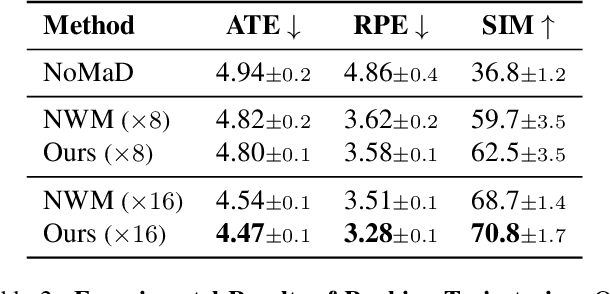
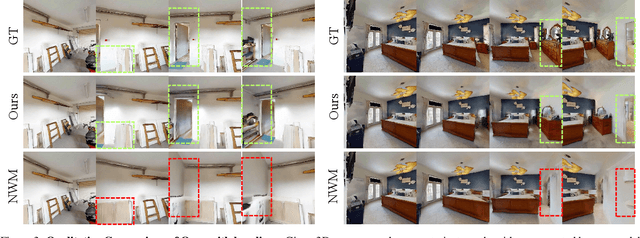
The ability to simulate the effects of future actions on the world is a crucial ability of intelligent embodied agents, enabling agents to anticipate the effects of their actions and make plans accordingly. While a large body of existing work has explored how to construct such world models using video models, they are often myopic in nature, without any memory of a scene not captured by currently observed images, preventing agents from making consistent long-horizon plans in complex environments where many parts of the scene are partially observed. We introduce a new persistent embodied world model with an explicit memory of previously generated content, enabling much more consistent long-horizon simulation. During generation time, our video diffusion model predicts RGB-D video of the future observations of the agent. This generation is then aggregated into a persistent 3D map of the environment. By conditioning the video model on this 3D spatial map, we illustrate how this enables video world models to faithfully simulate both seen and unseen parts of the world. Finally, we illustrate the efficacy of such a world model in downstream embodied applications, enabling effective planning and policy learning.
From Machine Learning to Machine Unlearning: Complying with GDPR's Right to be Forgotten while Maintaining Business Value of Predictive Models
Nov 26, 2024Recent privacy regulations (e.g., GDPR) grant data subjects the `Right to Be Forgotten' (RTBF) and mandate companies to fulfill data erasure requests from data subjects. However, companies encounter great challenges in complying with the RTBF regulations, particularly when asked to erase specific training data from their well-trained predictive models. While researchers have introduced machine unlearning methods aimed at fast data erasure, these approaches often overlook maintaining model performance (e.g., accuracy), which can lead to financial losses and non-compliance with RTBF obligations. This work develops a holistic machine learning-to-unlearning framework, called Ensemble-based iTerative Information Distillation (ETID), to achieve efficient data erasure while preserving the business value of predictive models. ETID incorporates a new ensemble learning method to build an accurate predictive model that can facilitate handling data erasure requests. ETID also introduces an innovative distillation-based unlearning method tailored to the constructed ensemble model to enable efficient and effective data erasure. Extensive experiments demonstrate that ETID outperforms various state-of-the-art methods and can deliver high-quality unlearned models with efficiency. We also highlight ETID's potential as a crucial tool for fostering a legitimate and thriving market for data and predictive services.
SnapMem: Snapshot-based 3D Scene Memory for Embodied Exploration and Reasoning
Nov 23, 2024



Constructing compact and informative 3D scene representations is essential for effective embodied exploration and reasoning, especially in complex environments over long periods. Existing scene representations, such as object-centric 3D scene graphs, have significant limitations. They oversimplify spatial relationships by modeling scenes as individual objects, with inter-object relationships described by restrictive texts, making it difficult to answer queries that require nuanced spatial understanding. Furthermore, these representations lack natural mechanisms for active exploration and memory management, which hampers their application to lifelong autonomy. In this work, we propose SnapMem, a novel snapshot-based scene representation serving as 3D scene memory for embodied agents. SnapMem employs informative images, termed Memory Snapshots, to capture rich visual information of explored regions. It also integrates frontier-based exploration by introducing Frontier Snapshots-glimpses of unexplored areas-that enable agents to make informed exploration decisions by considering both known and potential new information. Meanwhile, to support lifelong memory in active exploration settings, we further present an incremental construction pipeline for SnapMem, as well as an effective memory retrieval technique for memory management. Experimental results on three benchmarks demonstrate that SnapMem significantly enhances agents' exploration and reasoning capabilities in 3D environments over extended periods, highlighting its potential for advancing applications in embodied AI.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
Jun 17, 2022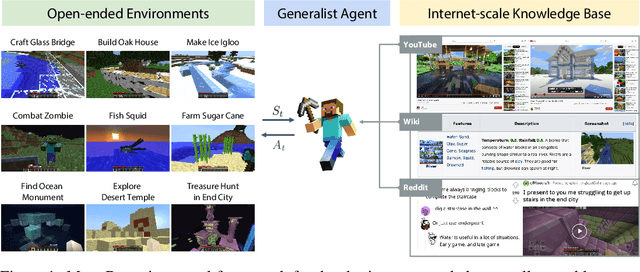
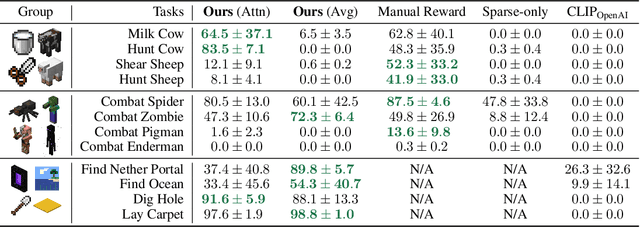
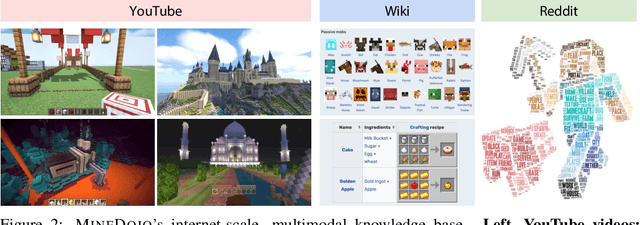

Autonomous agents have made great strides in specialist domains like Atari games and Go. However, they typically learn tabula rasa in isolated environments with limited and manually conceived objectives, thus failing to generalize across a wide spectrum of tasks and capabilities. Inspired by how humans continually learn and adapt in the open world, we advocate a trinity of ingredients for building generalist agents: 1) an environment that supports a multitude of tasks and goals, 2) a large-scale database of multimodal knowledge, and 3) a flexible and scalable agent architecture. We introduce MineDojo, a new framework built on the popular Minecraft game that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base with Minecraft videos, tutorials, wiki pages, and forum discussions. Using MineDojo's data, we propose a novel agent learning algorithm that leverages large pre-trained video-language models as a learned reward function. Our agent is able to solve a variety of open-ended tasks specified in free-form language without any manually designed dense shaping reward. We open-source the simulation suite and knowledge bases (https://minedojo.org) to promote research towards the goal of generally capable embodied agents.
Large-Scale Privacy-Preserving Network Embedding against Private Link Inference Attacks
May 28, 2022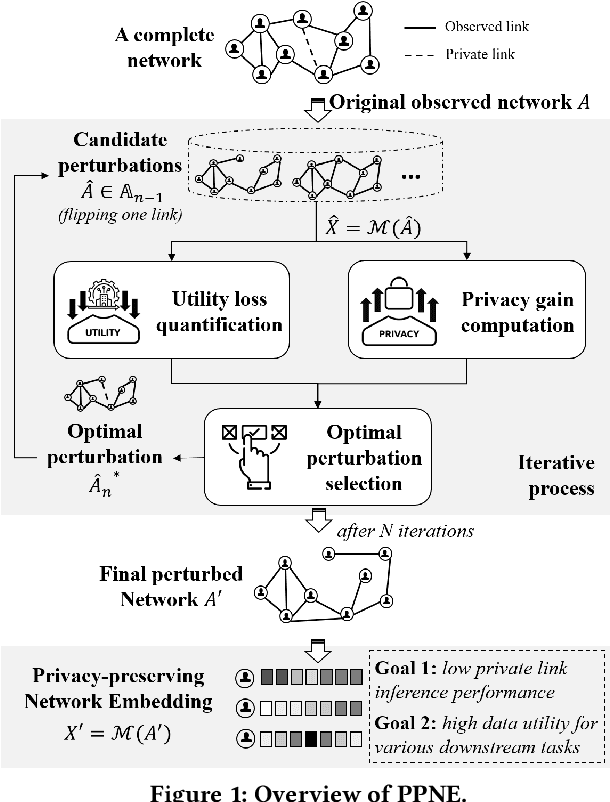

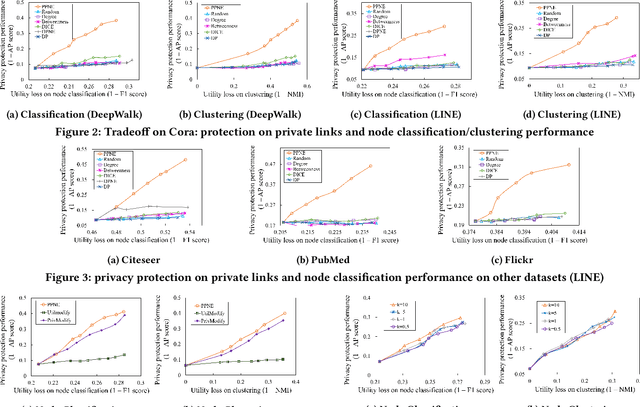
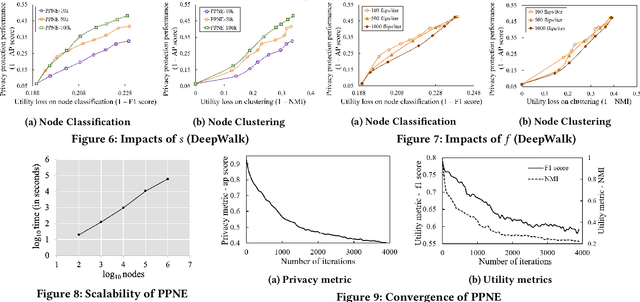
Network embedding represents network nodes by a low-dimensional informative vector. While it is generally effective for various downstream tasks, it may leak some private information of networks, such as hidden private links. In this work, we address a novel problem of privacy-preserving network embedding against private link inference attacks. Basically, we propose to perturb the original network by adding or removing links, and expect the embedding generated on the perturbed network can leak little information about private links but hold high utility for various downstream tasks. Towards this goal, we first propose general measurements to quantify privacy gain and utility loss incurred by candidate network perturbations; we then design a PPNE framework to identify the optimal perturbation solution with the best privacy-utility trade-off in an iterative way. Furthermore, we propose many techniques to accelerate PPNE and ensure its scalability. For instance, as the skip-gram embedding methods including DeepWalk and LINE can be seen as matrix factorization with closed form embedding results, we devise efficient privacy gain and utility loss approximation methods to avoid the repetitive time-consuming embedding training for every candidate network perturbation in each iteration. Experiments on real-life network datasets (with up to millions of nodes) verify that PPNE outperforms baselines by sacrificing less utility and obtaining higher privacy protection.
HyObscure: Hybrid Obscuring for Privacy-Preserving Data Publishing
Dec 15, 2021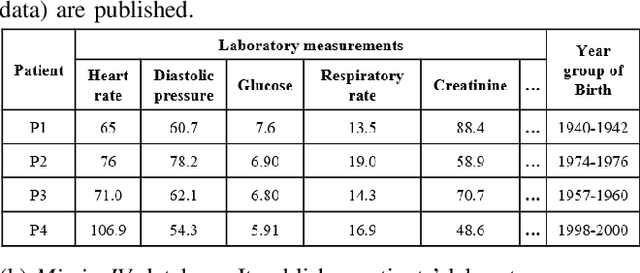
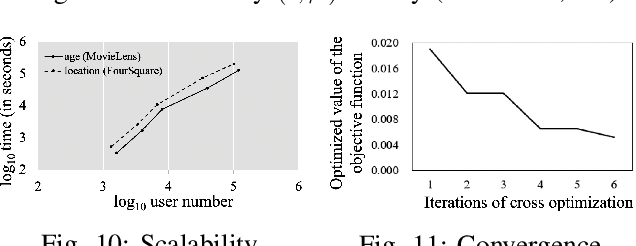
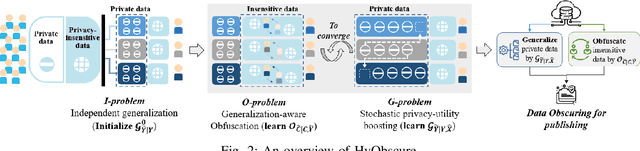
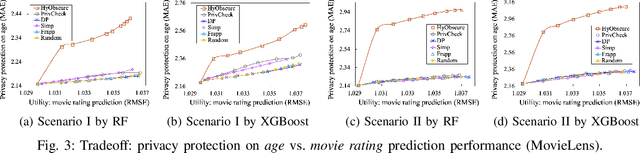
Minimizing privacy leakage while ensuring data utility is a critical problem to data holders in a privacy-preserving data publishing task. Most prior research concerns only with one type of data and resorts to a single obscuring method, \eg, obfuscation or generalization, to achieve a privacy-utility tradeoff, which is inadequate for protecting real-life heterogeneous data and is hard to defend ever-growing machine learning based inference attacks. This work takes a pilot study on privacy-preserving data publishing when both generalization and obfuscation operations are employed for heterogeneous data protection. To this end, we first propose novel measures for privacy and utility quantification and formulate the hybrid privacy-preserving data obscuring problem to account for the joint effect of generalization and obfuscation. We then design a novel hybrid protection mechanism called HyObscure, to cross-iteratively optimize the generalization and obfuscation operations for maximum privacy protection under a certain utility guarantee. The convergence of the iterative process and the privacy leakage bound of HyObscure are also provided in theory. Extensive experiments demonstrate that HyObscure significantly outperforms a variety of state-of-the-art baseline methods when facing various inference attacks under different scenarios. HyObscure also scales linearly to the data size and behaves robustly with varying key parameters.