 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Visual Attribute Effects in Advertising from Observational Data: A Deepfake-Informed Double Machine Learning Approach
Mar 02, 2026Digital advertising increasingly relies on visual content, yet marketers lack rigorous methods for understanding how specific visual attributes causally affect consumer engagement. This paper addresses a fundamental methodological challenge: estimating causal effects when the treatment, such as a model's skin tone, is an attribute embedded within the image itself. Standard approaches like Double Machine Learning (DML) fail in this setting because vision encoders entangle treatment information with confounding variables, producing severely biased estimates. We develop DICE-DML (Deepfake-Informed Control Encoder for Double Machine Learning), a framework that leverages generative AI to disentangle treatment from confounders. The approach combines three mechanisms: (1) deepfake-generated image pairs that isolate treatment variation; (2) DICE-Diff adversarial learning on paired difference vectors, where background signals cancel to reveal pure treatment fingerprints; and (3) orthogonal projection that geometrically removes treatment-axis components. In simulations with known ground truth, DICE-DML reduces root mean squared error by 73-97% compared to standard DML, with the strongest improvement (97.5%) at the null effect point, demonstrating robust Type I error control. Applying DICE-DML to 232,089 Instagram influencer posts, we estimate the causal effect of skin tone on engagement. Standard DML produces diagnostically invalid results (negative outcome R^2), while DICE-DML achieves valid confounding control (R^2 = 0.63) and estimates a marginally significant negative effect of darker skin tone (-522 likes; p = 0.062), substantially smaller than the biased standard estimate. Our framework provides a principled approach for causal inference with visual data when treatments and confounders coexist within images.
Adversarially Robust Detection of Harmful Online Content: A Computational Design Science Approach
Dec 19, 2025Social media platforms are plagued by harmful content such as hate speech, misinformation, and extremist rhetoric. Machine learning (ML) models are widely adopted to detect such content; however, they remain highly vulnerable to adversarial attacks, wherein malicious users subtly modify text to evade detection. Enhancing adversarial robustness is therefore essential, requiring detectors that can defend against diverse attacks (generalizability) while maintaining high overall accuracy. However, simultaneously achieving both optimal generalizability and accuracy is challenging. Following the computational design science paradigm, this study takes a sequential approach that first proposes a novel framework (Large Language Model-based Sample Generation and Aggregation, LLM-SGA) by identifying the key invariances of textual adversarial attacks and leveraging them to ensure that a detector instantiated within the framework has strong generalizability. Second, we instantiate our detector (Adversarially Robust Harmful Online Content Detector, ARHOCD) with three novel design components to improve detection accuracy: (1) an ensemble of multiple base detectors that exploits their complementary strengths; (2) a novel weight assignment method that dynamically adjusts weights based on each sample's predictability and each base detector's capability, with weights initialized using domain knowledge and updated via Bayesian inference; and (3) a novel adversarial training strategy that iteratively optimizes both the base detectors and the weight assignor. We addressed several limitations of existing adversarial robustness enhancement research and empirically evaluated ARHOCD across three datasets spanning hate speech, rumor, and extremist content. Results show that ARHOCD offers strong generalizability and improves detection accuracy under adversarial conditions.
Information-Consistent Language Model Recommendations through Group Relative Policy Optimization
Dec 14, 2025Large Language Models (LLMs) are increasingly deployed in business-critical domains such as finance, education, healthcare, and customer support, where users expect consistent and reliable recommendations. Yet LLMs often exhibit variability when prompts are phrased with minor differences, even when semantically equivalent. Such inconsistency undermines trust, complicates compliance, and disrupts user experience. While personalization is desirable in certain contexts, many enterprise scenarios-such as HR onboarding, customer support, or policy disclosure-require invariant information delivery regardless of phrasing or prior conversational history. Existing approaches, including retrieval-augmented generation (RAG) and temperature tuning, improve factuality or reduce stochasticity but cannot guarantee stability across equivalent prompts. In this paper, we propose a reinforcement learning framework based on Group Relative Policy Optimization (GRPO) to directly optimize for consistency. Unlike prior applications of GRPO, which have been limited to reasoning and code generation, we adapt GRPO to enforce stability of information content across groups of semantically equivalent prompts. We introduce entropy-based helpfulness and stability rewards, treating prompt variants as groups and resetting conversational context to isolate phrasing effects. Experiments on investment and job recommendation tasks show that our GRPO-trained model reduces variability more effectively than fine-tuning or decoding-based baselines. To our knowledge, this is a novel application of GRPO for aligning LLMs toward information consistency, reframing variability not as an acceptable feature of generative diversity but as a correctable flaw in enterprise deployments.
Do LLMs have a Gender (Entropy) Bias?
May 24, 2025We investigate the existence and persistence of a specific type of gender bias in some of the popular LLMs and contribute a new benchmark dataset, RealWorldQuestioning (released on HuggingFace ), developed from real-world questions across four key domains in business and health contexts: education, jobs, personal financial management, and general health. We define and study entropy bias, which we define as a discrepancy in the amount of information generated by an LLM in response to real questions users have asked. We tested this using four different LLMs and evaluated the generated responses both qualitatively and quantitatively by using ChatGPT-4o (as "LLM-as-judge"). Our analyses (metric-based comparisons and "LLM-as-judge" evaluation) suggest that there is no significant bias in LLM responses for men and women at a category level. However, at a finer granularity (the individual question level), there are substantial differences in LLM responses for men and women in the majority of cases, which "cancel" each other out often due to some responses being better for males and vice versa. This is still a concern since typical users of these tools often ask a specific question (only) as opposed to several varied ones in each of these common yet important areas of life. We suggest a simple debiasing approach that iteratively merges the responses for the two genders to produce a final result. Our approach demonstrates that a simple, prompt-based debiasing strategy can effectively debias LLM outputs, thus producing responses with higher information content than both gendered variants in 78% of the cases, and consistently achieving a balanced integration in the remaining cases.
From Machine Learning to Machine Unlearning: Complying with GDPR's Right to be Forgotten while Maintaining Business Value of Predictive Models
Nov 26, 2024Recent privacy regulations (e.g., GDPR) grant data subjects the `Right to Be Forgotten' (RTBF) and mandate companies to fulfill data erasure requests from data subjects. However, companies encounter great challenges in complying with the RTBF regulations, particularly when asked to erase specific training data from their well-trained predictive models. While researchers have introduced machine unlearning methods aimed at fast data erasure, these approaches often overlook maintaining model performance (e.g., accuracy), which can lead to financial losses and non-compliance with RTBF obligations. This work develops a holistic machine learning-to-unlearning framework, called Ensemble-based iTerative Information Distillation (ETID), to achieve efficient data erasure while preserving the business value of predictive models. ETID incorporates a new ensemble learning method to build an accurate predictive model that can facilitate handling data erasure requests. ETID also introduces an innovative distillation-based unlearning method tailored to the constructed ensemble model to enable efficient and effective data erasure. Extensive experiments demonstrate that ETID outperforms various state-of-the-art methods and can deliver high-quality unlearned models with efficiency. We also highlight ETID's potential as a crucial tool for fostering a legitimate and thriving market for data and predictive services.
AI Hallucinations: A Misnomer Worth Clarifying
Jan 09, 2024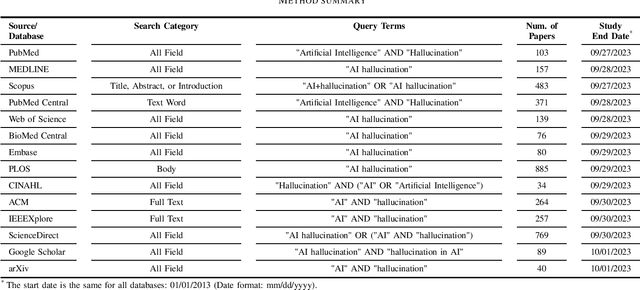

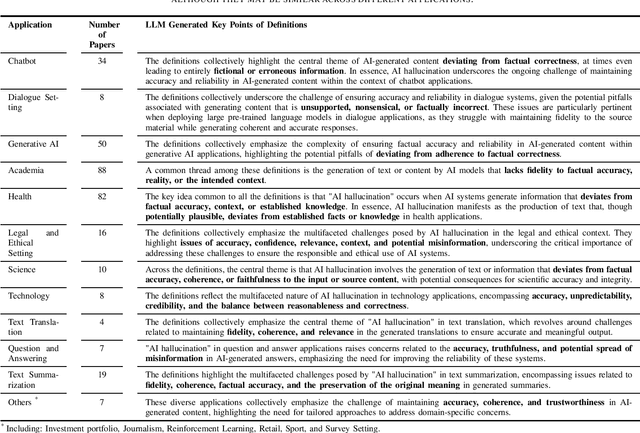
As large language models continue to advance in Artificial Intelligence (AI), text generation systems have been shown to suffer from a problematic phenomenon termed often as "hallucination." However, with AI's increasing presence across various domains including medicine, concerns have arisen regarding the use of the term itself. In this study, we conducted a systematic review to identify papers defining "AI hallucination" across fourteen databases. We present and analyze definitions obtained across all databases, categorize them based on their applications, and extract key points within each category. Our results highlight a lack of consistency in how the term is used, but also help identify several alternative terms in the literature. We discuss implications of these and call for a more unified effort to bring consistency to an important contemporary AI issue that can affect multiple domains significantly.
Systemic Fairness
Apr 14, 2023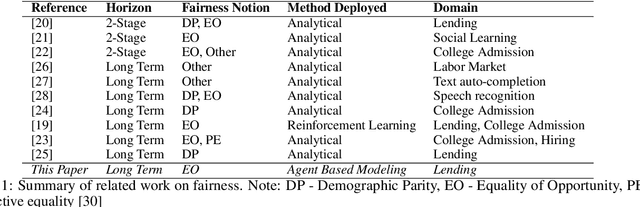
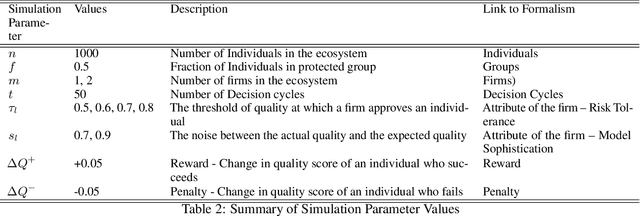
Machine learning algorithms are increasingly used to make or support decisions in a wide range of settings. With such expansive use there is also growing concern about the fairness of such methods. Prior literature on algorithmic fairness has extensively addressed risks and in many cases presented approaches to manage some of them. However, most studies have focused on fairness issues that arise from actions taken by a (single) focal decision-maker or agent. In contrast, most real-world systems have many agents that work collectively as part of a larger ecosystem. For example, in a lending scenario, there are multiple lenders who evaluate loans for applicants, along with policymakers and other institutions whose decisions also affect outcomes. Thus, the broader impact of any lending decision of a single decision maker will likely depend on the actions of multiple different agents in the ecosystem. This paper develops formalisms for firm versus systemic fairness, and calls for a greater focus in the algorithmic fairness literature on ecosystem-wide fairness - or more simply systemic fairness - in real-world contexts.
Whom to Test? Active Sampling Strategies for Managing COVID-19
Dec 25, 2020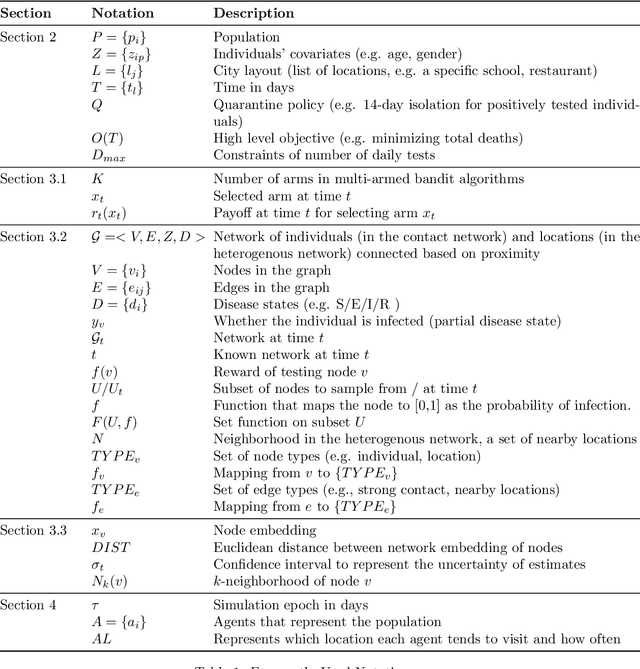
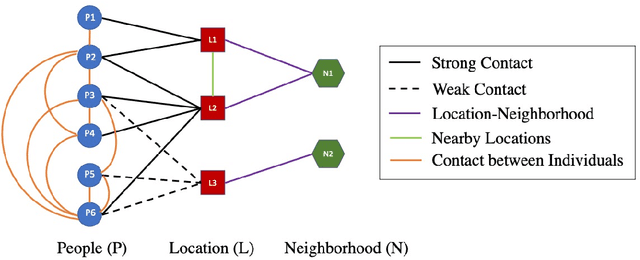

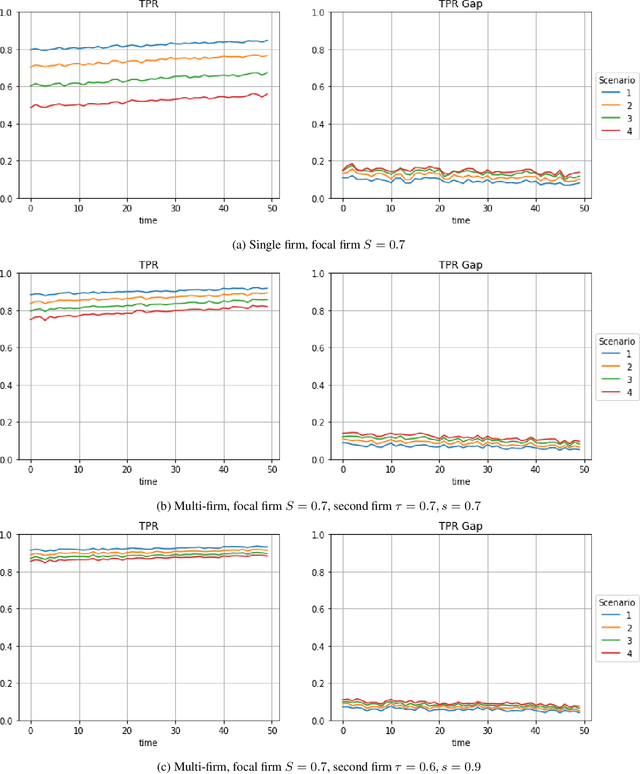
This paper presents methods to choose individuals to test for infection during a pandemic such as COVID-19, characterized by high contagion and presence of asymptomatic carriers. The smart-testing ideas presented here are motivated by active learning and multi-armed bandit techniques in machine learning. Our active sampling method works in conjunction with quarantine policies, can handle different objectives, is dynamic and adaptive in the sense that it continually adapts to changes in real-time data. The bandit algorithm uses contact tracing, location-based sampling and random sampling in order to select specific individuals to test. Using a data-driven agent-based model simulating New York City we show that the algorithm samples individuals to test in a manner that rapidly traces infected individuals. Experiments also suggest that smart-testing can significantly reduce the death rates as compared to current methods such as testing symptomatic individuals with or without contact tracing.
Deep Learning for Information Systems Research
Oct 07, 2020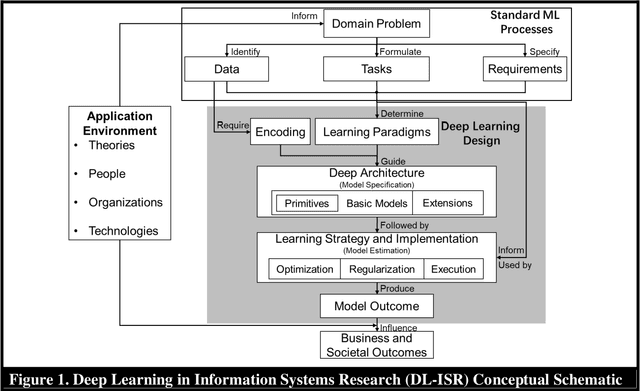
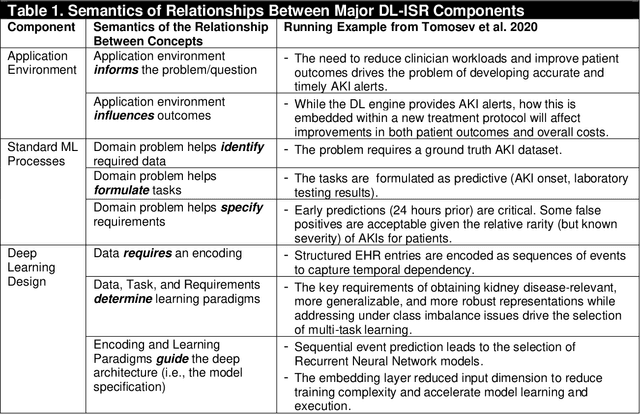
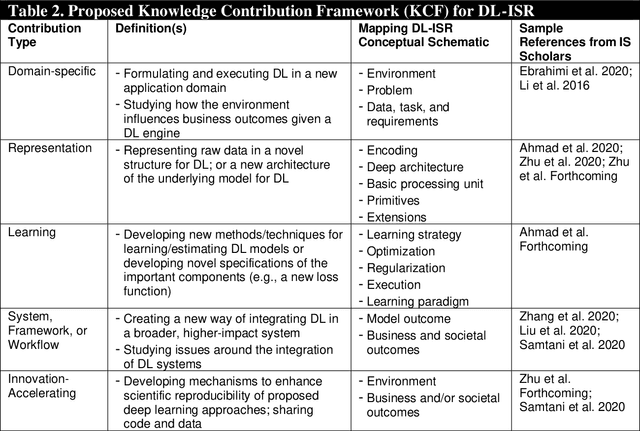
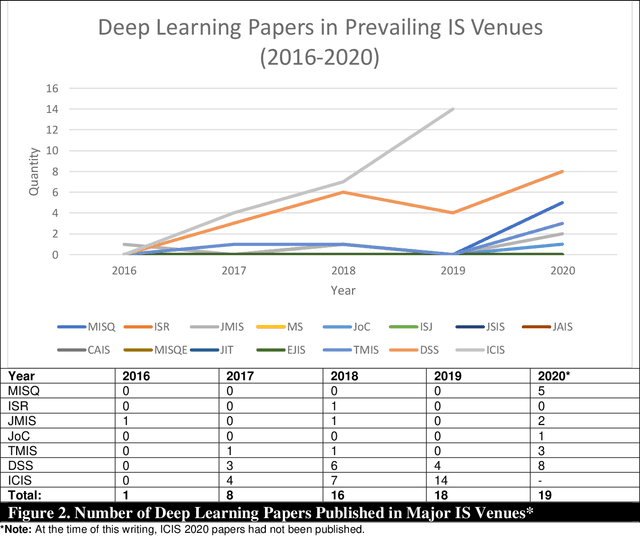
Artificial Intelligence (AI) has rapidly emerged as a key disruptive technology in the 21st century. At the heart of modern AI lies Deep Learning (DL), an emerging class of algorithms that has enabled today's platforms and organizations to operate at unprecedented efficiency, effectiveness, and scale. Despite significant interest, IS contributions in DL have been limited, which we argue is in part due to issues with defining, positioning, and conducting DL research. Recognizing the tremendous opportunity here for the IS community, this work clarifies, streamlines, and presents approaches for IS scholars to make timely and high-impact contributions. Related to this broader goal, this paper makes five timely contributions. First, we systematically summarize the major components of DL in a novel Deep Learning for Information Systems Research (DL-ISR) schematic that illustrates how technical DL processes are driven by key factors from an application environment. Second, we present a novel Knowledge Contribution Framework (KCF) to help IS scholars position their DL contributions for maximum impact. Third, we provide ten guidelines to help IS scholars generate rigorous and relevant DL-ISR in a systematic, high-quality fashion. Fourth, we present a review of prevailing journal and conference venues to examine how IS scholars have leveraged DL for various research inquiries. Finally, we provide a unique perspective on how IS scholars can formulate DL-ISR inquiries by carefully considering the interplay of business function(s), application areas(s), and the KCF. This perspective intentionally emphasizes inter-disciplinary, intra-disciplinary, and cross-IS tradition perspectives. Taken together, these contributions provide IS scholars a timely framework to advance the scale, scope, and impact of deep learning research.