 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Heterogeneous PET Images from Uniform Organ Activity Maps Using a Pretrained Domain-Adapted Diffusion Model
May 18, 2026Synthetic PET images are valuable for quantitative imaging workflow development, scalable virtual imaging trials, and deep learning model training, but conventional physics-based simulation approaches are computationally intensive, limited in anatomical variability, and often fail to capture heterogeneous PET uptake. This study developed a pretrained domain-adapted diffusion (PAD) model for anatomy-conditioned PET synthesis from uniform organ activity maps. PAD adopts a natural-image pretrained text-to-image decoder with an upstream conditioning encoder and a downstream PET-domain adapter. A two-phase training strategy was used, with the first phase learning coarse uptake distributions and the second refining local image details. Uniform organ activity maps were generated from CT-based segmentations by assigning each organ its mean uptake from the paired PET image. Evaluation included quantitative accuracy, noise assessment, radiomic analysis, tumor segmentation performance, and a human observer study. PAD-generated images achieved high quantitative accuracy, with concordance correlation coefficients above 0.92 between organ mean SUVs and assigned activity values. The synthesized images showed noise levels and texture characteristics similar to target PET images and produced comparable tumor segmentation performance. In a two-alternative forced-choice observer study, four readers achieved approximately 50% accuracy, indicating visual indistinguishability between synthesized and target images. PAD also generated realistic PET images from XCAT-derived activity maps, demonstrating compatibility with phantom-based anatomical priors. Overall, PAD provides a diffusion-based framework for generating clinically relevant heterogeneous PET images from uniform organ activity maps derived from clinical segmentations or digital phantoms, supporting data augmentation and downstream imaging studies.
Automatic Neuronal Activity Segmentation in Fast Four Dimensional Spatio-Temporal Fluorescence Imaging using Bayesian Approach
Dec 22, 2025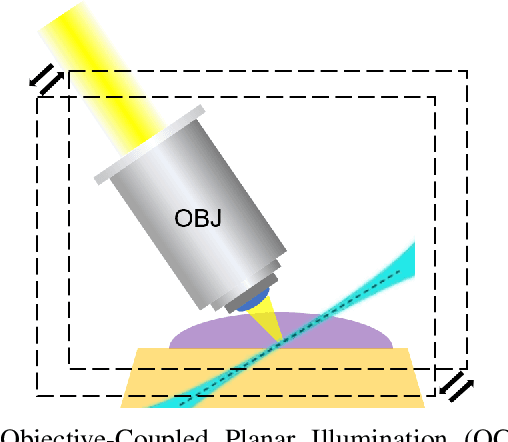
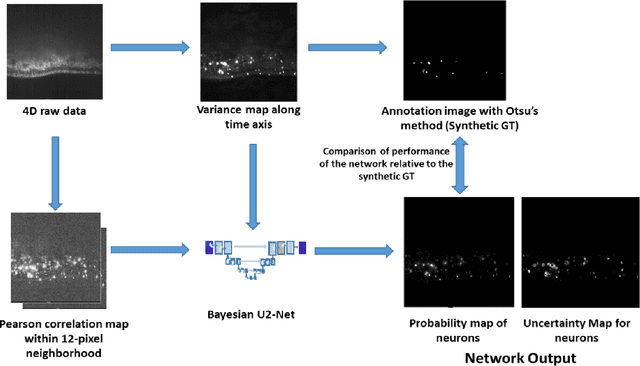
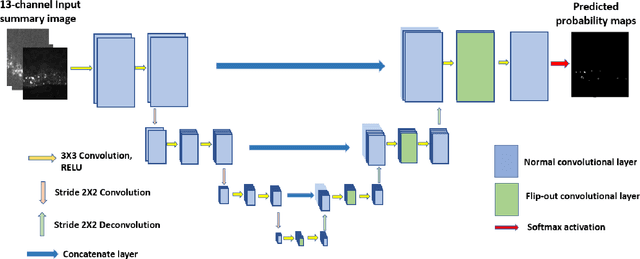
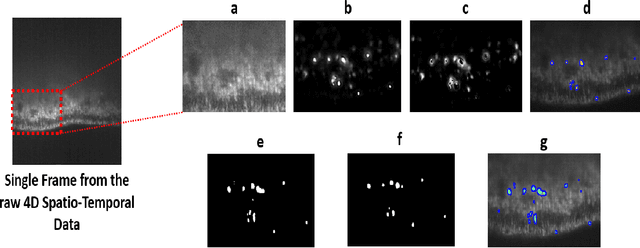
Fluorescence Microcopy Calcium Imaging is a fundamental tool to in-vivo record and analyze large scale neuronal activities simultaneously at a single cell resolution. Automatic and precise detection of behaviorally relevant neuron activity from the recordings is critical to study the mapping of brain activity in organisms. However a perpetual bottleneck to this problem is the manual segmentation which is time and labor intensive and lacks generalizability. To this end, we present a Bayesian Deep Learning Framework to detect neuronal activities in 4D spatio-temporal data obtained by light sheet microscopy. Our approach accounts for the use of temporal information by calculating pixel wise correlation maps and combines it with spatial information given by the mean summary image. The Bayesian framework not only produces probability segmentation maps but also models the uncertainty pertaining to active neuron detection. To evaluate the accuracy of our framework we implemented the test of reproducibility to assert the generalization of the network to detect neuron activity. The network achieved a mean Dice Score of 0.81 relative to the synthetic Ground Truth obtained by Otsu's method and a mean Dice Score of 0.79 between the first and second run for test of reproducibility. Our method successfully deployed can be used for rapid detection of active neuronal activities for behavioural studies.
Information-Consistent Language Model Recommendations through Group Relative Policy Optimization
Dec 14, 2025Large Language Models (LLMs) are increasingly deployed in business-critical domains such as finance, education, healthcare, and customer support, where users expect consistent and reliable recommendations. Yet LLMs often exhibit variability when prompts are phrased with minor differences, even when semantically equivalent. Such inconsistency undermines trust, complicates compliance, and disrupts user experience. While personalization is desirable in certain contexts, many enterprise scenarios-such as HR onboarding, customer support, or policy disclosure-require invariant information delivery regardless of phrasing or prior conversational history. Existing approaches, including retrieval-augmented generation (RAG) and temperature tuning, improve factuality or reduce stochasticity but cannot guarantee stability across equivalent prompts. In this paper, we propose a reinforcement learning framework based on Group Relative Policy Optimization (GRPO) to directly optimize for consistency. Unlike prior applications of GRPO, which have been limited to reasoning and code generation, we adapt GRPO to enforce stability of information content across groups of semantically equivalent prompts. We introduce entropy-based helpfulness and stability rewards, treating prompt variants as groups and resetting conversational context to isolate phrasing effects. Experiments on investment and job recommendation tasks show that our GRPO-trained model reduces variability more effectively than fine-tuning or decoding-based baselines. To our knowledge, this is a novel application of GRPO for aligning LLMs toward information consistency, reframing variability not as an acceptable feature of generative diversity but as a correctable flaw in enterprise deployments.
Do LLMs have a Gender (Entropy) Bias?
May 24, 2025We investigate the existence and persistence of a specific type of gender bias in some of the popular LLMs and contribute a new benchmark dataset, RealWorldQuestioning (released on HuggingFace ), developed from real-world questions across four key domains in business and health contexts: education, jobs, personal financial management, and general health. We define and study entropy bias, which we define as a discrepancy in the amount of information generated by an LLM in response to real questions users have asked. We tested this using four different LLMs and evaluated the generated responses both qualitatively and quantitatively by using ChatGPT-4o (as "LLM-as-judge"). Our analyses (metric-based comparisons and "LLM-as-judge" evaluation) suggest that there is no significant bias in LLM responses for men and women at a category level. However, at a finer granularity (the individual question level), there are substantial differences in LLM responses for men and women in the majority of cases, which "cancel" each other out often due to some responses being better for males and vice versa. This is still a concern since typical users of these tools often ask a specific question (only) as opposed to several varied ones in each of these common yet important areas of life. We suggest a simple debiasing approach that iteratively merges the responses for the two genders to produce a final result. Our approach demonstrates that a simple, prompt-based debiasing strategy can effectively debias LLM outputs, thus producing responses with higher information content than both gendered variants in 78% of the cases, and consistently achieving a balanced integration in the remaining cases.
AI Hallucinations: A Misnomer Worth Clarifying
Jan 09, 2024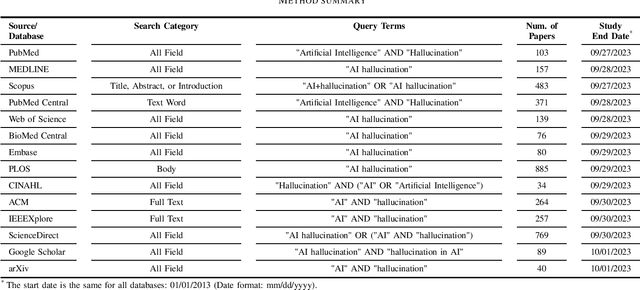

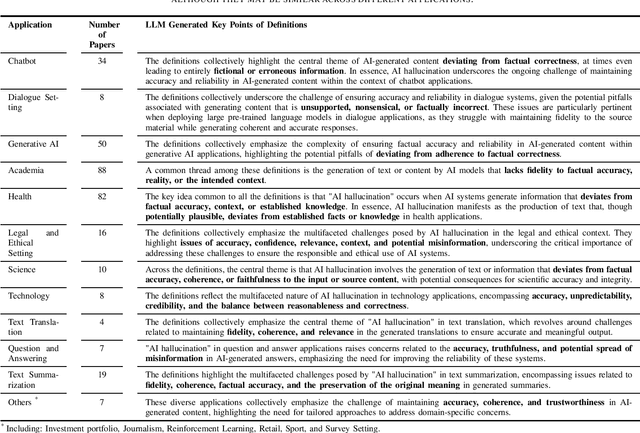
As large language models continue to advance in Artificial Intelligence (AI), text generation systems have been shown to suffer from a problematic phenomenon termed often as "hallucination." However, with AI's increasing presence across various domains including medicine, concerns have arisen regarding the use of the term itself. In this study, we conducted a systematic review to identify papers defining "AI hallucination" across fourteen databases. We present and analyze definitions obtained across all databases, categorize them based on their applications, and extract key points within each category. Our results highlight a lack of consistency in how the term is used, but also help identify several alternative terms in the literature. We discuss implications of these and call for a more unified effort to bring consistency to an important contemporary AI issue that can affect multiple domains significantly.
Representing Social Networks as Dynamic Heterogeneous Graphs
Sep 12, 2022



Graph representations for real-world social networks in the past have missed two important elements: the multiplexity of connections as well as representing time. To this end, in this paper, we present a new dynamic heterogeneous graph representation for social networks which includes time in every single component of the graph, i.e., nodes and edges, each of different types that captures heterogeneity. We illustrate the power of this representation by presenting four time-dependent queries and deep learning problems that cannot easily be handled in conventional homogeneous graph representations commonly used. As a proof of concept we present a detailed representation of a new social media platform (Steemit), which we use to illustrate both the dynamic querying capability as well as prediction tasks using graph neural networks (GNNs). The results illustrate the power of the dynamic heterogeneous graph representation to model social networks. Given that this is a relatively understudied area we also illustrate opportunities for future work in query optimization as well as new dynamic prediction tasks on heterogeneous graph structures.
Deep Learning based Framework for Automatic Diagnosis of Glaucoma based on analysis of Focal Notching in the Optic Nerve Head
Dec 10, 2021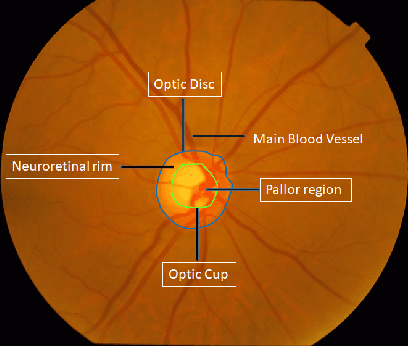
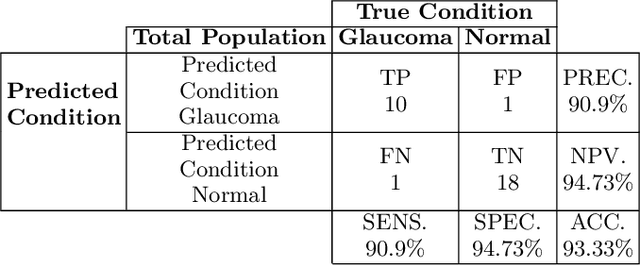
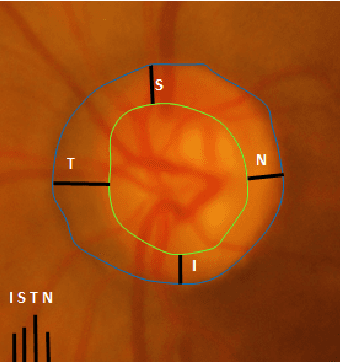
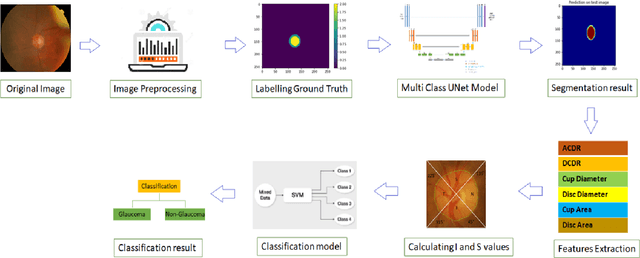
Automatic evaluation of the retinal fundus image is emerging as one of the most important tools for early detection and treatment of progressive eye diseases like Glaucoma. Glaucoma results to a progressive degeneration of vision and is characterized by the deformation of the shape of optic cup and the degeneration of the blood vessels resulting in the formation of a notch along the neuroretinal rim. In this paper, we propose a deep learning-based pipeline for automatic segmentation of optic disc (OD) and optic cup (OC) regions from Digital Fundus Images (DFIs), thereby extracting distinct features necessary for prediction of Glaucoma. This methodology has utilized focal notch analysis of neuroretinal rim along with cup-to-disc ratio values as classifying parameters to enhance the accuracy of Computer-aided design (CAD) systems in analyzing glaucoma. Support Vector-based Machine Learning algorithm is used for classification, which classifies DFIs as Glaucomatous or Normal based on the extracted features. The proposed pipeline was evaluated on the freely available DRISHTI-GS dataset with a resultant accuracy of 93.33% for detecting Glaucoma from DFIs.
Densely Connected Recurrent Residual (Dense R2UNet) Convolutional Neural Network for Segmentation of Lung CT Images
Feb 01, 2021



Deep Learning networks have established themselves as providing state of art performance for semantic segmentation. These techniques are widely applied specifically to medical detection, segmentation and classification. The advent of the U-Net based architecture has become particularly popular for this application. In this paper we present the Dense Recurrent Residual Convolutional Neural Network(Dense R2U CNN) which is a synthesis of Recurrent CNN, Residual Network and Dense Convolutional Network based on the U-Net model architecture. The residual unit helps training deeper network, while the dense recurrent layers enhances feature propagation needed for segmentation. The proposed model tested on the benchmark Lung Lesion dataset showed better performance on segmentation tasks than its equivalent models.
Identifying Fake Profiles in LinkedIn
Jun 02, 2020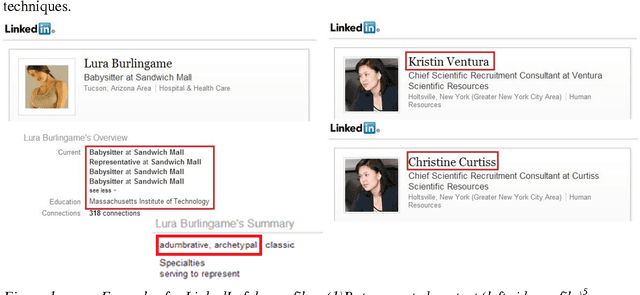



As organizations increasingly rely on professionally oriented networks such as LinkedIn (the largest such social network) for building business connections, there is increasing value in having one's profile noticed within the network. As this value increases, so does the temptation to misuse the network for unethical purposes. Fake profiles have an adverse effect on the trustworthiness of the network as a whole, and can represent significant costs in time and effort in building a connection based on fake information. Unfortunately, fake profiles are difficult to identify. Approaches have been proposed for some social networks; however, these generally rely on data that are not publicly available for LinkedIn profiles. In this research, we identify the minimal set of profile data necessary for identifying fake profiles in LinkedIn, and propose an appropriate data mining approach for fake profile identification. We demonstrate that, even with limited profile data, our approach can identify fake profiles with 87% accuracy and 94% True Negative Rate, which is comparable to the results obtained based on larger data sets and more expansive profile information. Further, when compared to approaches using similar amounts and types of data, our method provides an improvement of approximately 14% accuracy.