 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Detection of Harmful Online Content: A Computational Design Science Approach
Dec 19, 2025Social media platforms are plagued by harmful content such as hate speech, misinformation, and extremist rhetoric. Machine learning (ML) models are widely adopted to detect such content; however, they remain highly vulnerable to adversarial attacks, wherein malicious users subtly modify text to evade detection. Enhancing adversarial robustness is therefore essential, requiring detectors that can defend against diverse attacks (generalizability) while maintaining high overall accuracy. However, simultaneously achieving both optimal generalizability and accuracy is challenging. Following the computational design science paradigm, this study takes a sequential approach that first proposes a novel framework (Large Language Model-based Sample Generation and Aggregation, LLM-SGA) by identifying the key invariances of textual adversarial attacks and leveraging them to ensure that a detector instantiated within the framework has strong generalizability. Second, we instantiate our detector (Adversarially Robust Harmful Online Content Detector, ARHOCD) with three novel design components to improve detection accuracy: (1) an ensemble of multiple base detectors that exploits their complementary strengths; (2) a novel weight assignment method that dynamically adjusts weights based on each sample's predictability and each base detector's capability, with weights initialized using domain knowledge and updated via Bayesian inference; and (3) a novel adversarial training strategy that iteratively optimizes both the base detectors and the weight assignor. We addressed several limitations of existing adversarial robustness enhancement research and empirically evaluated ARHOCD across three datasets spanning hate speech, rumor, and extremist content. Results show that ARHOCD offers strong generalizability and improves detection accuracy under adversarial conditions.
Detecting Fake News on Social Media: A Novel Reliability Aware Machine-Crowd Hybrid Intelligence-Based Method
Dec 07, 2024



Fake news on social media platforms poses a significant threat to societal systems, underscoring the urgent need for advanced detection methods. The existing detection methods can be divided into machine intelligence-based, crowd intelligence-based, and hybrid intelligence-based methods. Among them, hybrid intelligence-based methods achieve the best performance but fail to consider the reliability issue in detection. In light of this, we propose a novel Reliability Aware Hybrid Intelligence (RAHI) method for fake news detection. Our method comprises three integral modules. The first module employs a Bayesian deep learning model to capture the inherent reliability within machine intelligence. The second module uses an Item Response Theory (IRT)-based user response aggregation to account for the reliability in crowd intelligence. The third module introduces a new distribution fusion mechanism, which takes the distributions derived from both machine and crowd intelligence as input, and outputs a fused distribution that provides predictions along with the associated reliability. The experiments on the Weibo dataset demonstrate the advantages of our method. This study contributes to the research field with a novel RAHI-based method, and the code is shared at https://github.com/Kangwei-g/RAHI. This study has practical implications for three key stakeholders: internet users, online platform managers, and the government.
From Machine Learning to Machine Unlearning: Complying with GDPR's Right to be Forgotten while Maintaining Business Value of Predictive Models
Nov 26, 2024Recent privacy regulations (e.g., GDPR) grant data subjects the `Right to Be Forgotten' (RTBF) and mandate companies to fulfill data erasure requests from data subjects. However, companies encounter great challenges in complying with the RTBF regulations, particularly when asked to erase specific training data from their well-trained predictive models. While researchers have introduced machine unlearning methods aimed at fast data erasure, these approaches often overlook maintaining model performance (e.g., accuracy), which can lead to financial losses and non-compliance with RTBF obligations. This work develops a holistic machine learning-to-unlearning framework, called Ensemble-based iTerative Information Distillation (ETID), to achieve efficient data erasure while preserving the business value of predictive models. ETID incorporates a new ensemble learning method to build an accurate predictive model that can facilitate handling data erasure requests. ETID also introduces an innovative distillation-based unlearning method tailored to the constructed ensemble model to enable efficient and effective data erasure. Extensive experiments demonstrate that ETID outperforms various state-of-the-art methods and can deliver high-quality unlearned models with efficiency. We also highlight ETID's potential as a crucial tool for fostering a legitimate and thriving market for data and predictive services.
Towards Trustworthy Web Attack Detection: An Uncertainty-Aware Ensemble Deep Kernel Learning Model
Oct 10, 2024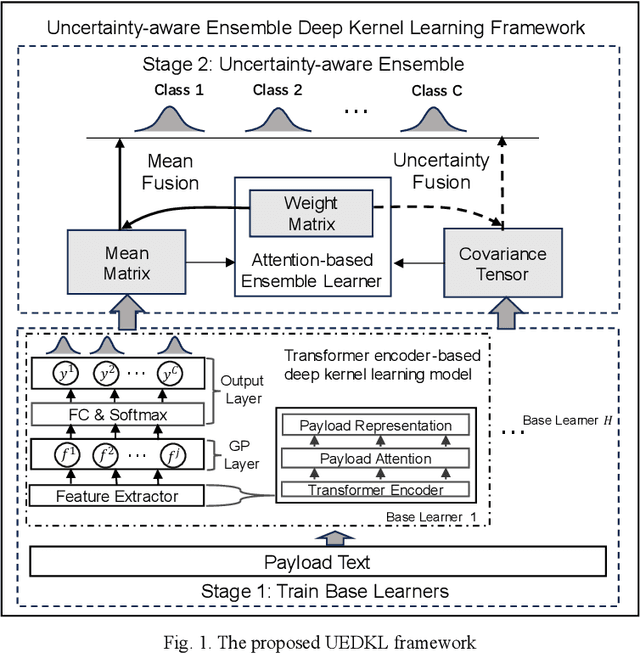
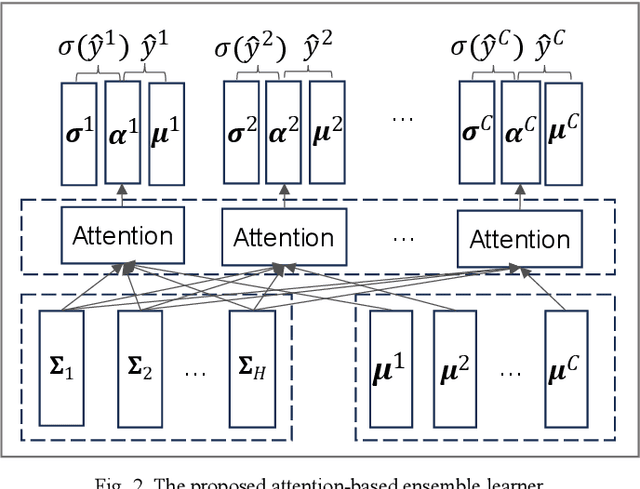
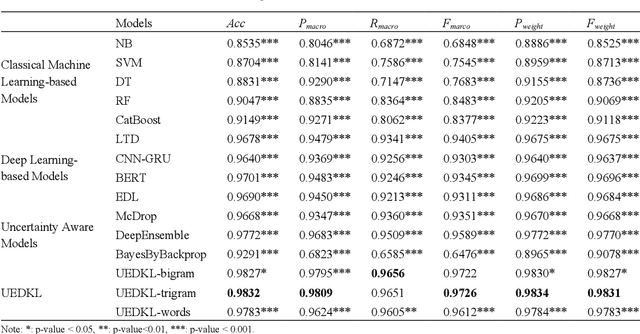
Web attacks are one of the major and most persistent forms of cyber threats, which bring huge costs and losses to web application-based businesses. Various detection methods, such as signature-based, machine learning-based, and deep learning-based, have been proposed to identify web attacks. However, these methods either (1) heavily rely on accurate and complete rule design and feature engineering, which may not adapt to fast-evolving attacks, or (2) fail to estimate model uncertainty, which is essential to the trustworthiness of the prediction made by the model. In this study, we proposed an Uncertainty-aware Ensemble Deep Kernel Learning (UEDKL) model to detect web attacks from HTTP request payload data with the model uncertainty captured from the perspective of both data distribution and model parameters. The proposed UEDKL utilizes a deep kernel learning model to distinguish normal HTTP requests from different types of web attacks with model uncertainty estimated from data distribution perspective. Multiple deep kernel learning models were trained as base learners to capture the model uncertainty from model parameters perspective. An attention-based ensemble learning approach was designed to effectively integrate base learners' predictions and model uncertainty. We also proposed a new metric named High Uncertainty Ratio-F Score Curve to evaluate model uncertainty estimation. Experiments on BDCI and SRBH datasets demonstrated that the proposed UEDKL framework yields significant improvement in both web attack detection performance and uncertainty estimation quality compared to benchmark models.
A Whole-Process Certifiably Robust Aggregation Method Against Backdoor Attacks in Federated Learning
Jun 30, 2024



Federated Learning (FL) has garnered widespread adoption across various domains such as finance, healthcare, and cybersecurity. Nonetheless, FL remains under significant threat from backdoor attacks, wherein malicious actors insert triggers into trained models, enabling them to perform certain tasks while still meeting FL's primary objectives. In response, robust aggregation methods have been proposed, which can be divided into three types: ex-ante, ex-durante, and ex-post methods. Given the complementary nature of these methods, combining all three types is promising yet unexplored. Such a combination is non-trivial because it requires leveraging their advantages while overcoming their disadvantages. Our study proposes a novel whole-process certifiably robust aggregation (WPCRA) method for FL, which enhances robustness against backdoor attacks across three phases: ex-ante, ex-durante, and ex-post. Moreover, since the current geometric median estimation method fails to consider differences among clients, we propose a novel weighted geometric median estimation algorithm (WGME). This algorithm estimates the geometric median of model updates from clients based on each client's weight, further improving the robustness of WPCRA against backdoor attacks. We also theoretically prove that WPCRA offers improved certified robustness guarantees with a larger certified radius. We evaluate the advantages of our methods based on the task of loan status prediction. Comparison with baselines shows that our methods significantly improve FL's robustness against backdoor attacks. This study contributes to the literature with a novel WPCRA method and a novel WGME algorithm. Our code is available at https://github.com/brick-brick/WPCRAM.
Personalized Music Recommendation with a Heterogeneity-aware Deep Bayesian Network
Jun 20, 2024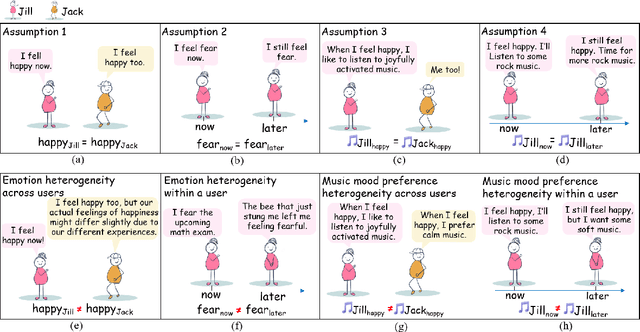
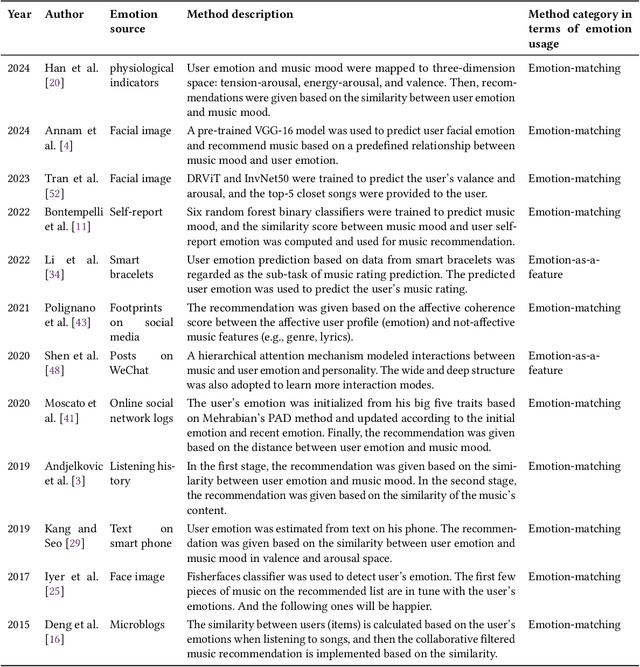
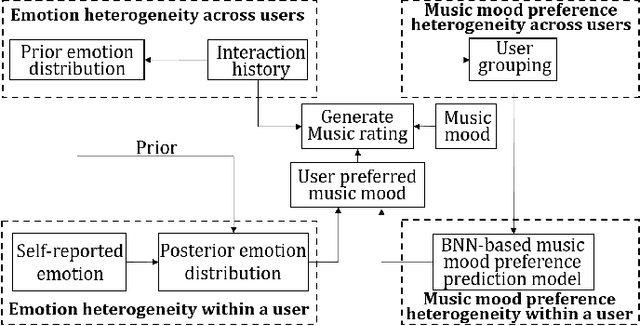
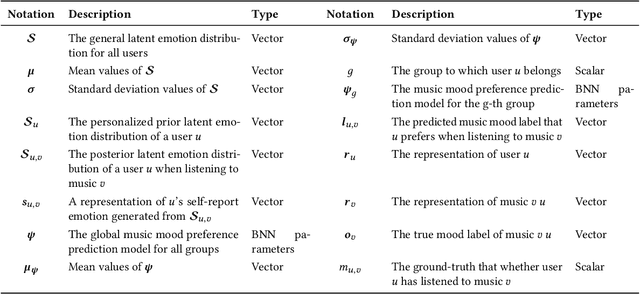
Music recommender systems are crucial in music streaming platforms, providing users with music they would enjoy. Recent studies have shown that user emotions can affect users' music mood preferences. However, existing emotion-aware music recommender systems (EMRSs) explicitly or implicitly assume that users' actual emotional states expressed by an identical emotion word are homogeneous. They also assume that users' music mood preferences are homogeneous under an identical emotional state. In this article, we propose four types of heterogeneity that an EMRS should consider: emotion heterogeneity across users, emotion heterogeneity within a user, music mood preference heterogeneity across users, and music mood preference heterogeneity within a user. We further propose a Heterogeneity-aware Deep Bayesian Network (HDBN) to model these assumptions. The HDBN mimics a user's decision process to choose music with four components: personalized prior user emotion distribution modeling, posterior user emotion distribution modeling, user grouping, and Bayesian neural network-based music mood preference prediction. We constructed a large-scale dataset called EmoMusicLJ to validate our method. Extensive experiments demonstrate that our method significantly outperforms baseline approaches on widely used HR and NDCG recommendation metrics. Ablation experiments and case studies further validate the effectiveness of our HDBN. The source code is available at https://github.com/jingrk/HDBN.
Few-Shot Learning for Chronic Disease Management: Leveraging Large Language Models and Multi-Prompt Engineering with Medical Knowledge Injection
Jan 16, 2024This study harnesses state-of-the-art AI technology for chronic disease management, specifically in detecting various mental disorders through user-generated textual content. Existing studies typically rely on fully supervised machine learning, which presents challenges such as the labor-intensive manual process of annotating extensive training data for each disease and the need to design specialized deep learning architectures for each problem. To address such challenges, we propose a novel framework that leverages advanced AI techniques, including large language models and multi-prompt engineering. Specifically, we address two key technical challenges in data-driven chronic disease management: (1) developing personalized prompts to represent each user's uniqueness and (2) incorporating medical knowledge into prompts to provide context for chronic disease detection, instruct learning objectives, and operationalize prediction goals. We evaluate our method using four mental disorders, which are prevalent chronic diseases worldwide, as research cases. On the depression detection task, our method (F1 = 0.975~0.978) significantly outperforms traditional supervised learning paradigms, including feature engineering (F1 = 0.760) and architecture engineering (F1 = 0.756). Meanwhile, our approach demonstrates success in few-shot learning, i.e., requiring only a minimal number of training examples to detect chronic diseases based on user-generated textual content (i.e., only 2, 10, or 100 subjects). Moreover, our method can be generalized to other mental disorder detection tasks, including anorexia, pathological gambling, and self-harm (F1 = 0.919~0.978).
Heterogeneous Domain Adaptation with Adversarial Neural Representation Learning: Experiments on E-Commerce and Cybersecurity
May 05, 2022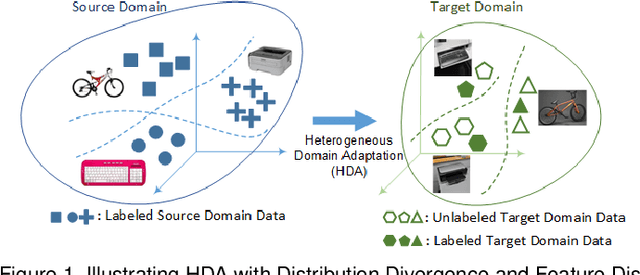


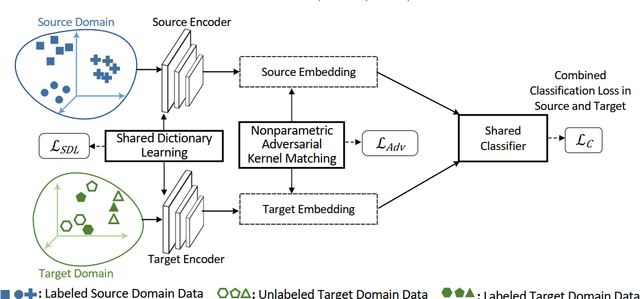
Learning predictive models in new domains with scarce training data is a growing challenge in modern supervised learning scenarios. This incentivizes developing domain adaptation methods that leverage the knowledge in known domains (source) and adapt to new domains (target) with a different probability distribution. This becomes more challenging when the source and target domains are in heterogeneous feature spaces, known as heterogeneous domain adaptation (HDA). While most HDA methods utilize mathematical optimization to map source and target data to a common space, they suffer from low transferability. Neural representations have proven to be more transferable; however, they are mainly designed for homogeneous environments. Drawing on the theory of domain adaptation, we propose a novel framework, Heterogeneous Adversarial Neural Domain Adaptation (HANDA), to effectively maximize the transferability in heterogeneous environments. HANDA conducts feature and distribution alignment in a unified neural network architecture and achieves domain invariance through adversarial kernel learning. Three experiments were conducted to evaluate the performance against the state-of-the-art HDA methods on major image and text e-commerce benchmarks. HANDA shows statistically significant improvement in predictive performance. The practical utility of HANDA was shown in real-world dark web online markets. HANDA is an important step towards successful domain adaptation in e-commerce applications.
Understanding Health Misinformation Transmission: An Interpretable Deep Learning Approach to Manage Infodemics
Dec 21, 2020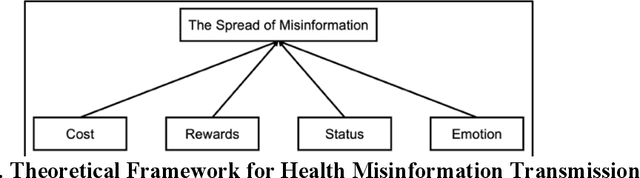

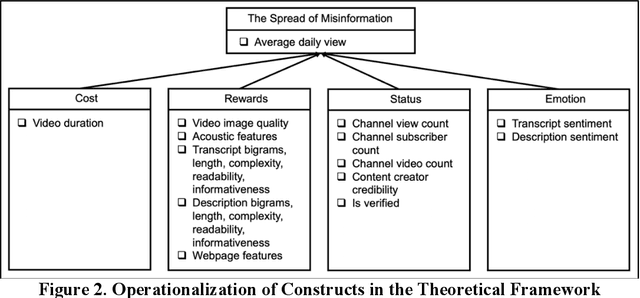
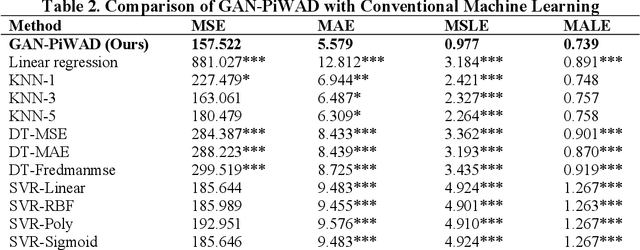
Health misinformation on social media devastates physical and mental health, invalidates health gains, and potentially costs lives. Understanding how health misinformation is transmitted is an urgent goal for researchers, social media platforms, health sectors, and policymakers to mitigate those ramifications. Deep learning methods have been deployed to predict the spread of misinformation. While achieving the state-of-the-art predictive performance, deep learning methods lack the interpretability due to their blackbox nature. To remedy this gap, this study proposes a novel interpretable deep learning approach, Generative Adversarial Network based Piecewise Wide and Attention Deep Learning (GAN-PiWAD), to predict health misinformation transmission in social media. Improving upon state-of-the-art interpretable methods, GAN-PiWAD captures the interactions among multi-modal data, offers unbiased estimation of the total effect of each feature, and models the dynamic total effect of each feature when its value varies. We select features according to social exchange theory and evaluate GAN-PiWAD on 4,445 misinformation videos. The proposed approach outperformed strong benchmarks. Interpretation of GAN-PiWAD indicates video description, negative video content, and channel credibility are key features that drive viral transmission of misinformation. This study contributes to IS with a novel interpretable deep learning method that is generalizable to understand other human decision factors. Our findings provide direct implications for social media platforms and policymakers to design proactive interventions to identify misinformation, control transmissions, and manage infodemics.
TopicModel4J: A Java Package for Topic Models
Oct 28, 2020

Topic models provide a flexible and principled framework for exploring hidden structure in high-dimensional co-occurrence data and are commonly used natural language processing (NLP) of text. In this paper, we design and implement a Java package, TopicModel4J, which contains 13 kinds of representative algorithms for fitting topic models. The TopicModel4J in the Java programming environment provides an easy-to-use interface for data analysts to run the algorithms, and allow to easily input and output data. In addition, this package provides a few unstructured text preprocessing techniques, such as splitting textual data into words, lowercasing the words, preforming lemmatization and removing the useless characters, URLs and stop words.