 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Process Model with Tensorial Inputs and Its Application to the Design of 3D Printed Antennas
Jul 19, 2024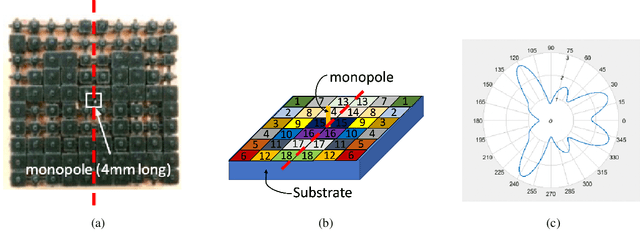

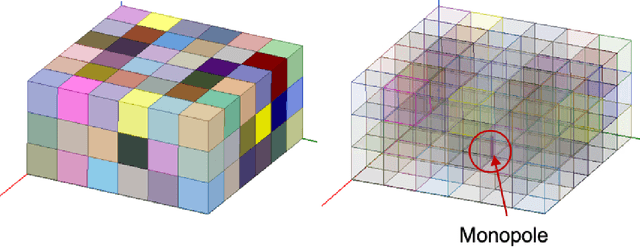

In simulation-based engineering design with time-consuming simulators, Gaussian process (GP) models are widely used as fast emulators to speed up the design optimization process. In its most commonly used form, the input of GP is a simple list of design parameters. With rapid development of additive manufacturing (also known as 3D printing), design inputs with 2D/3D spatial information become prevalent in some applications, for example, neighboring relations between pixels/voxels and material distributions in heterogeneous materials. Such spatial information, vital to 3D printed designs, is hard to incorporate into existing GP models with common kernels such as squared exponential or Mat\'ern. In this work, we propose to embed a generalized distance measure into a GP kernel, offering a novel and convenient technique to incorporate spatial information from freeform 3D printed designs into the GP framework. The proposed method allows complex design problems for 3D printed objects to take advantage of a plethora of tools available from the GP surrogate-based simulation optimization such as designed experiments and GP-based optimizations including Bayesian optimization. We investigate the properties of the proposed method and illustrate its performance by several numerical examples of 3D printed antennas. The dataset is publicly available at: https://github.com/xichennn/GP_dataset.
Sparse Learning and Class Probability Estimation with Weighted Support Vector Machines
Dec 17, 2023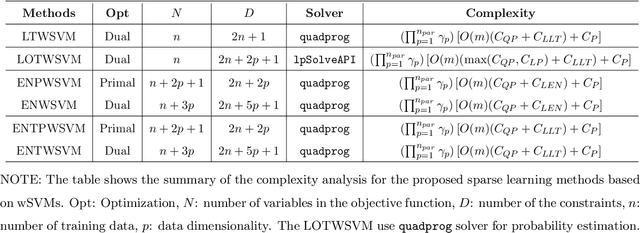
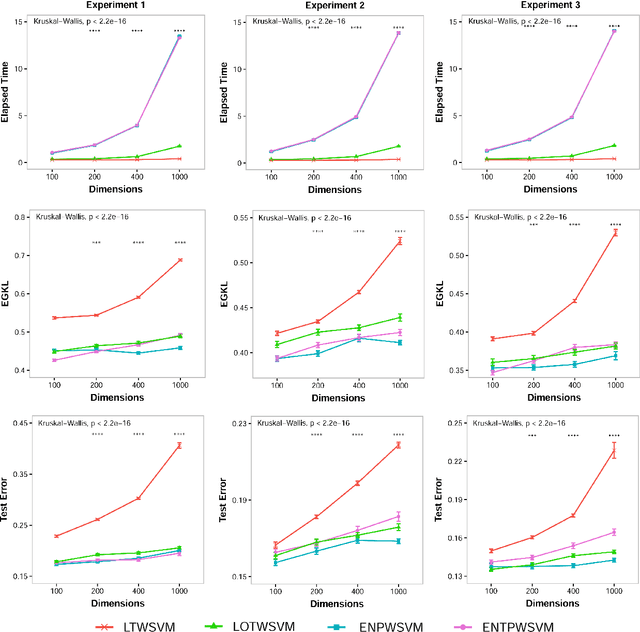
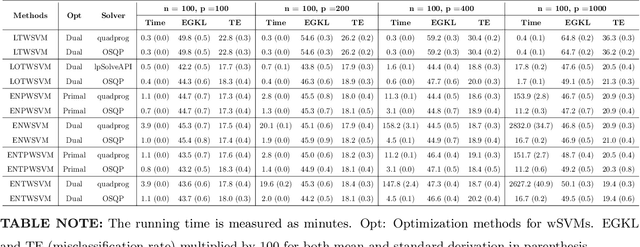
Classification and probability estimation have broad applications in modern machine learning and data science applications, including biology, medicine, engineering, and computer science. The recent development of a class of weighted Support Vector Machines (wSVMs) has shown great values in robustly predicting the class probability and classification for various problems with high accuracy. The current framework is based on the $\ell^2$-norm regularized binary wSVMs optimization problem, which only works with dense features and has poor performance at sparse features with redundant noise in most real applications. The sparse learning process requires a prescreen of the important variables for each binary wSVMs for accurately estimating pairwise conditional probability. In this paper, we proposed novel wSVMs frameworks that incorporate automatic variable selection with accurate probability estimation for sparse learning problems. We developed efficient algorithms for effective variable selection for solving either the $\ell^1$-norm or elastic net regularized binary wSVMs optimization problems. The binary class probability is then estimated either by the $\ell^2$-norm regularized wSVMs framework with selected variables or by elastic net regularized wSVMs directly. The two-step approach of $\ell^1$-norm followed by $\ell^2$-norm wSVMs show a great advantage in both automatic variable selection and reliable probability estimators with the most efficient time. The elastic net regularized wSVMs offer the best performance in terms of variable selection and probability estimation with the additional advantage of variable grouping in the compensation of more computation time for high dimensional problems. The proposed wSVMs-based sparse learning methods have wide applications and can be further extended to $K$-class problems through ensemble learning.
Robust Brain MRI Image Classification with SIBOW-SVM
Nov 15, 2023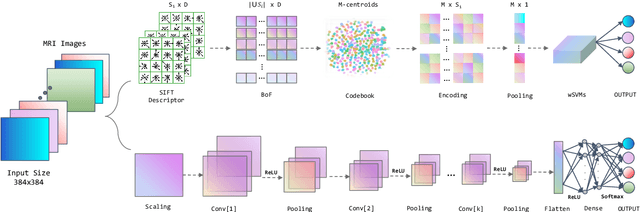
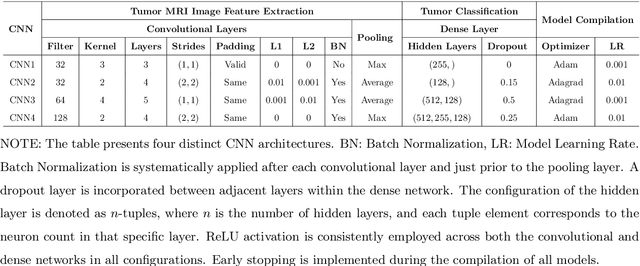
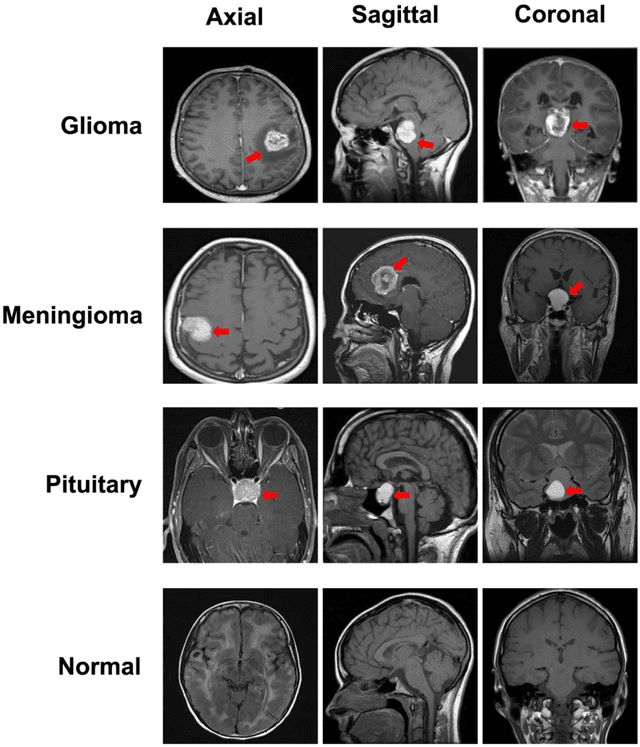
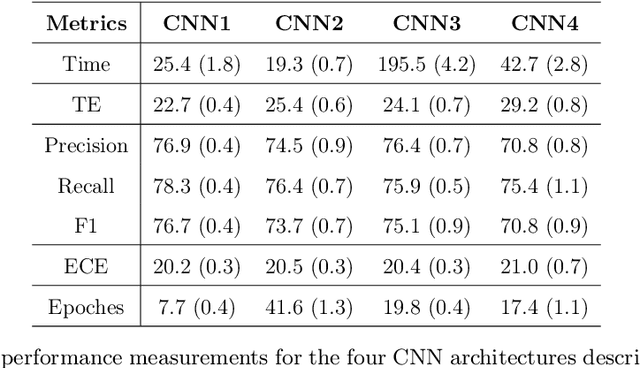
The majority of primary Central Nervous System (CNS) tumors in the brain are among the most aggressive diseases affecting humans. Early detection of brain tumor types, whether benign or malignant, glial or non-glial, is critical for cancer prevention and treatment, ultimately improving human life expectancy. Magnetic Resonance Imaging (MRI) stands as the most effective technique to detect brain tumors by generating comprehensive brain images through scans. However, human examination can be error-prone and inefficient due to the complexity, size, and location variability of brain tumors. Recently, automated classification techniques using machine learning (ML) methods, such as Convolutional Neural Network (CNN), have demonstrated significantly higher accuracy than manual screening, while maintaining low computational costs. Nonetheless, deep learning-based image classification methods, including CNN, face challenges in estimating class probabilities without proper model calibration. In this paper, we propose a novel brain tumor image classification method, called SIBOW-SVM, which integrates the Bag-of-Features (BoF) model with SIFT feature extraction and weighted Support Vector Machines (wSVMs). This new approach effectively captures hidden image features, enabling the differentiation of various tumor types and accurate label predictions. Additionally, the SIBOW-SVM is able to estimate the probabilities of images belonging to each class, thereby providing high-confidence classification decisions. We have also developed scalable and parallelable algorithms to facilitate the practical implementation of SIBOW-SVM for massive images. As a benchmark, we apply the SIBOW-SVM to a public data set of brain tumor MRI images containing four classes: glioma, meningioma, pituitary, and normal. Our results show that the new method outperforms state-of-the-art methods, including CNN.
Boosting Nyström Method
Feb 21, 2023The Nystr\"{o}m method is an effective tool to generate low-rank approximations of large matrices, and it is particularly useful for kernel-based learning. To improve the standard Nystr\"{o}m approximation, ensemble Nystr\"{o}m algorithms compute a mixture of Nystr\"{o}m approximations which are generated independently based on column resampling. We propose a new family of algorithms, boosting Nystr\"{o}m, which iteratively generate multiple ``weak'' Nystr\"{o}m approximations (each using a small number of columns) in a sequence adaptively - each approximation aims to compensate for the weaknesses of its predecessor - and then combine them to form one strong approximation. We demonstrate that our boosting Nystr\"{o}m algorithms can yield more efficient and accurate low-rank approximations to kernel matrices. Improvements over the standard and ensemble Nystr\"{o}m methods are illustrated by simulation studies and real-world data analysis.
Linear Algorithms for Nonparametric Multiclass Probability Estimation
Jun 03, 2022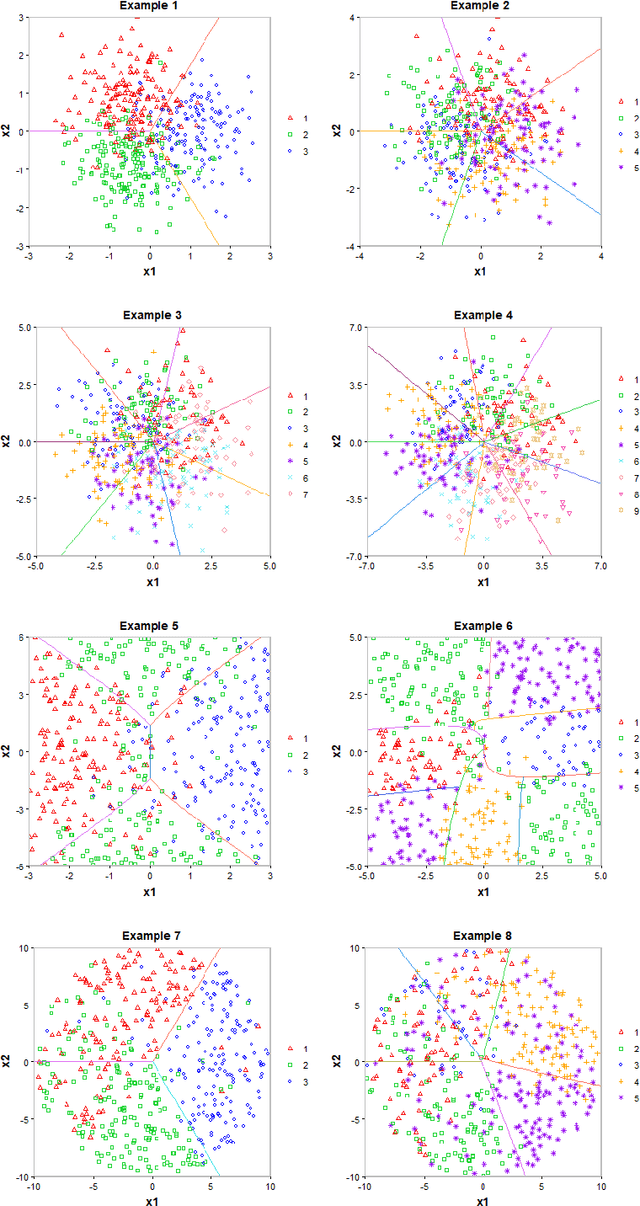

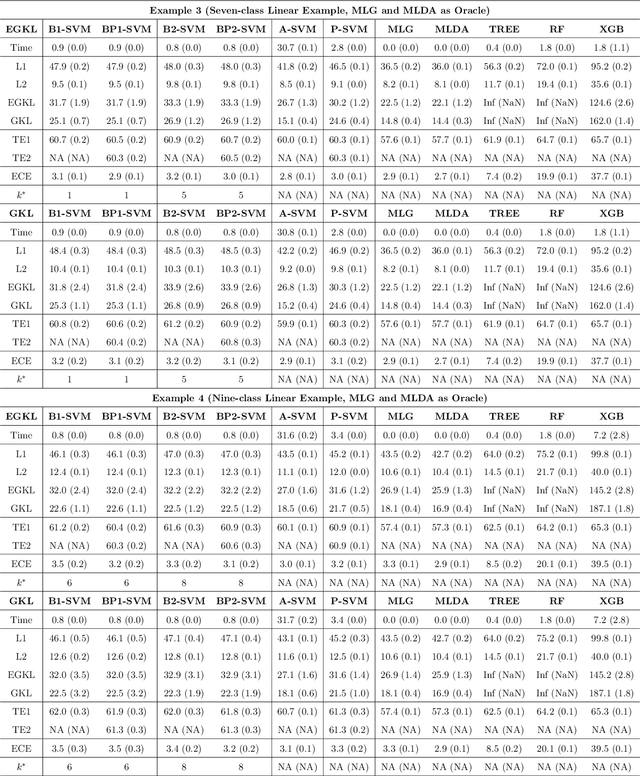
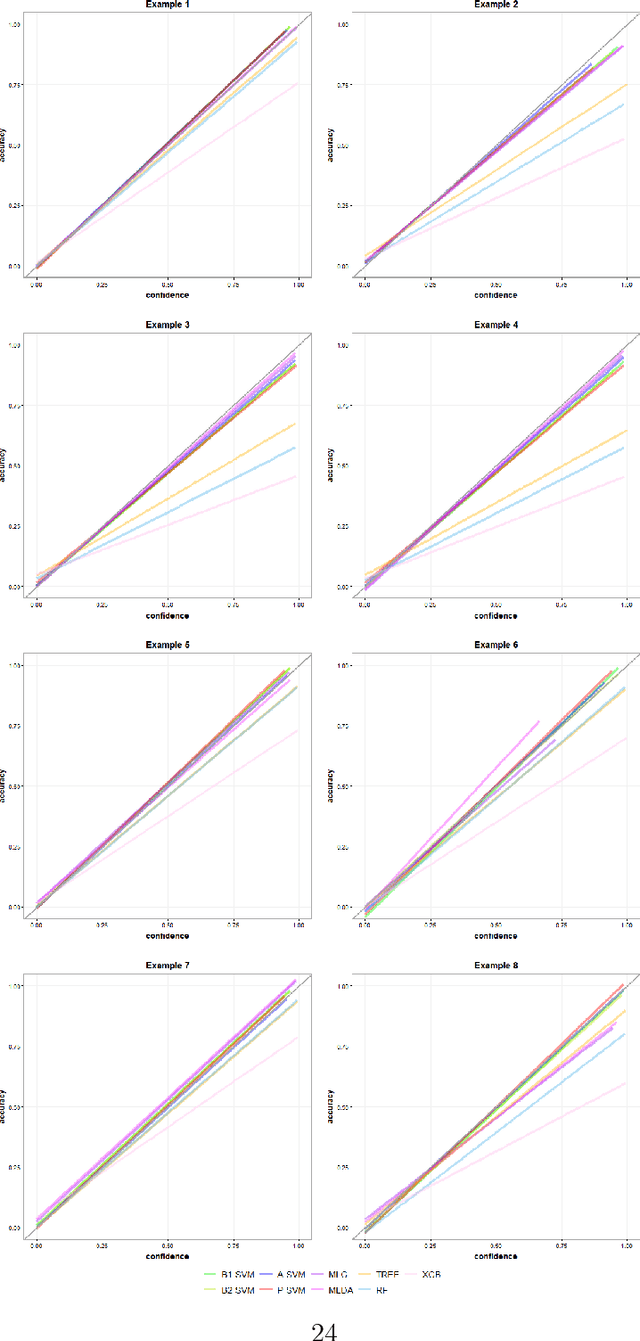
Multiclass probability estimation is the problem of estimating conditional probabilities of a data point belonging to a class given its covariate information. It has broad applications in statistical analysis and data science. Recently a class of weighted Support Vector Machines (wSVMs) has been developed to estimate class probabilities through ensemble learning for $K$-class problems (Wu, Zhang and Liu, 2010; Wang, Zhang and Wu, 2019), where $K$ is the number of classes. The estimators are robust and achieve high accuracy for probability estimation, but their learning is implemented through pairwise coupling, which demands polynomial time in $K$. In this paper, we propose two new learning schemes, the baseline learning and the One-vs-All (OVA) learning, to further improve wSVMs in terms of computational efficiency and estimation accuracy. In particular, the baseline learning has optimal computational complexity in the sense that it is linear in $K$. Though not being most efficient in computation, the OVA offers the best estimation accuracy among all the procedures under comparison. The resulting estimators are distribution-free and shown to be consistent. We further conduct extensive numerical experiments to demonstrate finite sample performance.
Heterogeneous Domain Adaptation with Adversarial Neural Representation Learning: Experiments on E-Commerce and Cybersecurity
May 05, 2022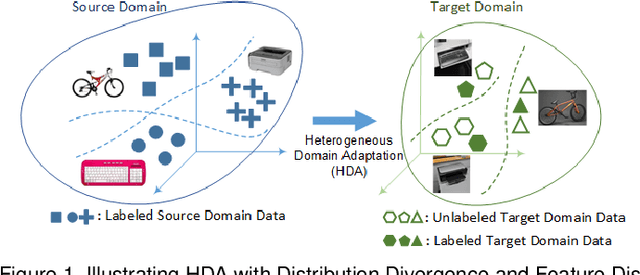


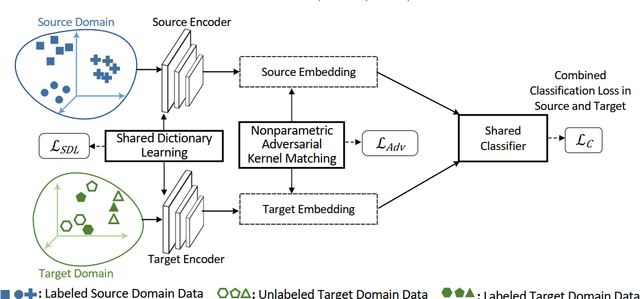
Learning predictive models in new domains with scarce training data is a growing challenge in modern supervised learning scenarios. This incentivizes developing domain adaptation methods that leverage the knowledge in known domains (source) and adapt to new domains (target) with a different probability distribution. This becomes more challenging when the source and target domains are in heterogeneous feature spaces, known as heterogeneous domain adaptation (HDA). While most HDA methods utilize mathematical optimization to map source and target data to a common space, they suffer from low transferability. Neural representations have proven to be more transferable; however, they are mainly designed for homogeneous environments. Drawing on the theory of domain adaptation, we propose a novel framework, Heterogeneous Adversarial Neural Domain Adaptation (HANDA), to effectively maximize the transferability in heterogeneous environments. HANDA conducts feature and distribution alignment in a unified neural network architecture and achieves domain invariance through adversarial kernel learning. Three experiments were conducted to evaluate the performance against the state-of-the-art HDA methods on major image and text e-commerce benchmarks. HANDA shows statistically significant improvement in predictive performance. The practical utility of HANDA was shown in real-world dark web online markets. HANDA is an important step towards successful domain adaptation in e-commerce applications.
Nonparametric Trace Regression in High Dimensions via Sign Series Representation
May 04, 2021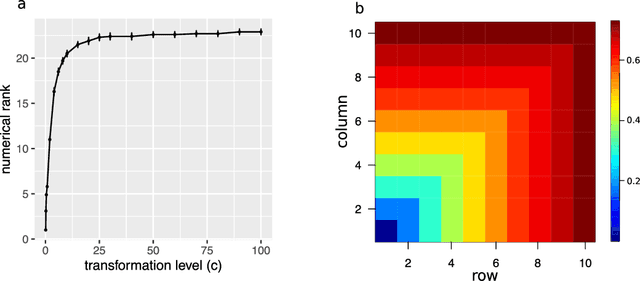

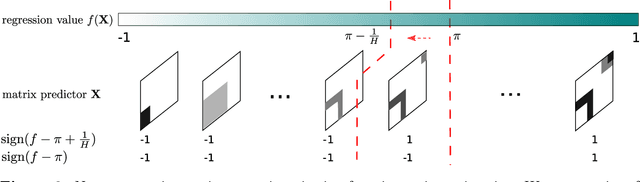

Learning of matrix-valued data has recently surged in a range of scientific and business applications. Trace regression is a widely used method to model effects of matrix predictors and has shown great success in matrix learning. However, nearly all existing trace regression solutions rely on two assumptions: (i) a known functional form of the conditional mean, and (ii) a global low-rank structure in the entire range of the regression function, both of which may be violated in practice. In this article, we relax these assumptions by developing a general framework for nonparametric trace regression models via structured sign series representations of high dimensional functions. The new model embraces both linear and nonlinear trace effects, and enjoys rank invariance to order-preserving transformations of the response. In the context of matrix completion, our framework leads to a substantially richer model based on what we coin as the "sign rank" of a matrix. We show that the sign series can be statistically characterized by weighted classification tasks. Based on this connection, we propose a learning reduction approach to learn the regression model via a series of classifiers, and develop a parallelable computation algorithm to implement sign series aggregations. We establish the excess risk bounds, estimation error rates, and sample complexities. Our proposal provides a broad nonparametric paradigm to many important matrix learning problems, including matrix regression, matrix completion, multi-task learning, and compressed sensing. We demonstrate the advantages of our method through simulations and two applications, one on brain connectivity study and the other on high-rank image completion.