 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Detection of Harmful Online Content: A Computational Design Science Approach
Dec 19, 2025Social media platforms are plagued by harmful content such as hate speech, misinformation, and extremist rhetoric. Machine learning (ML) models are widely adopted to detect such content; however, they remain highly vulnerable to adversarial attacks, wherein malicious users subtly modify text to evade detection. Enhancing adversarial robustness is therefore essential, requiring detectors that can defend against diverse attacks (generalizability) while maintaining high overall accuracy. However, simultaneously achieving both optimal generalizability and accuracy is challenging. Following the computational design science paradigm, this study takes a sequential approach that first proposes a novel framework (Large Language Model-based Sample Generation and Aggregation, LLM-SGA) by identifying the key invariances of textual adversarial attacks and leveraging them to ensure that a detector instantiated within the framework has strong generalizability. Second, we instantiate our detector (Adversarially Robust Harmful Online Content Detector, ARHOCD) with three novel design components to improve detection accuracy: (1) an ensemble of multiple base detectors that exploits their complementary strengths; (2) a novel weight assignment method that dynamically adjusts weights based on each sample's predictability and each base detector's capability, with weights initialized using domain knowledge and updated via Bayesian inference; and (3) a novel adversarial training strategy that iteratively optimizes both the base detectors and the weight assignor. We addressed several limitations of existing adversarial robustness enhancement research and empirically evaluated ARHOCD across three datasets spanning hate speech, rumor, and extremist content. Results show that ARHOCD offers strong generalizability and improves detection accuracy under adversarial conditions.
Adversarially Robust Deep Learning with Optimal-Transport-Regularized Divergences
Sep 07, 2023We introduce the $ARMOR_D$ methods as novel approaches to enhancing the adversarial robustness of deep learning models. These methods are based on a new class of optimal-transport-regularized divergences, constructed via an infimal convolution between an information divergence and an optimal-transport (OT) cost. We use these as tools to enhance adversarial robustness by maximizing the expected loss over a neighborhood of distributions, a technique known as distributionally robust optimization. Viewed as a tool for constructing adversarial samples, our method allows samples to be both transported, according to the OT cost, and re-weighted, according to the information divergence. We demonstrate the effectiveness of our method on malware detection and image recognition applications and find that, to our knowledge, it outperforms existing methods at enhancing the robustness against adversarial attacks. $ARMOR_D$ yields the robustified accuracy of $98.29\%$ against $FGSM$ and $98.18\%$ against $PGD^{40}$ on the MNIST dataset, reducing the error rate by more than $19.7\%$ and $37.2\%$ respectively compared to prior methods. Similarly, in malware detection, a discrete (binary) data domain, $ARMOR_D$ improves the robustified accuracy under $rFGSM^{50}$ attack compared to the previous best-performing adversarial training methods by $37.0\%$ while lowering false negative and false positive rates by $51.1\%$ and $57.53\%$, respectively.
Multi-view Representation Learning from Malware to Defend Against Adversarial Variants
Oct 25, 2022Deep learning-based adversarial malware detectors have yielded promising results in detecting never-before-seen malware executables without relying on expensive dynamic behavior analysis and sandbox. Despite their abilities, these detectors have been shown to be vulnerable to adversarial malware variants - meticulously modified, functionality-preserving versions of original malware executables generated by machine learning. Due to the nature of these adversarial modifications, these adversarial methods often use a \textit{single view} of malware executables (i.e., the binary/hexadecimal view) to generate adversarial malware variants. This provides an opportunity for the defenders (i.e., malware detectors) to detect the adversarial variants by utilizing more than one view of a malware file (e.g., source code view in addition to the binary view). The rationale behind this idea is that while the adversary focuses on the binary view, certain characteristics of the malware file in the source code view remain untouched which leads to the detection of the adversarial malware variants. To capitalize on this opportunity, we propose Adversarially Robust Multiview Malware Defense (ARMD), a novel multi-view learning framework to improve the robustness of DL-based malware detectors against adversarial variants. Our experiments on three renowned open-source deep learning-based malware detectors across six common malware categories show that ARMD is able to improve the adversarial robustness by up to seven times on these malware detectors.
Heterogeneous Domain Adaptation with Adversarial Neural Representation Learning: Experiments on E-Commerce and Cybersecurity
May 05, 2022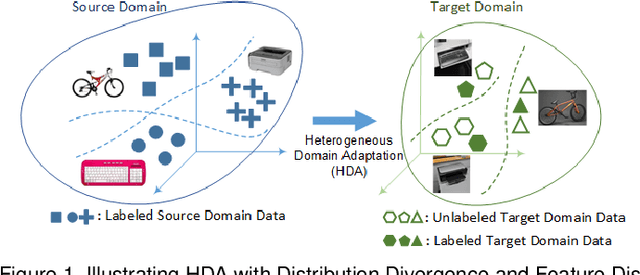


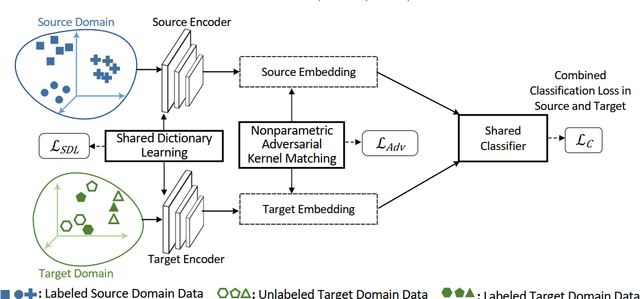
Learning predictive models in new domains with scarce training data is a growing challenge in modern supervised learning scenarios. This incentivizes developing domain adaptation methods that leverage the knowledge in known domains (source) and adapt to new domains (target) with a different probability distribution. This becomes more challenging when the source and target domains are in heterogeneous feature spaces, known as heterogeneous domain adaptation (HDA). While most HDA methods utilize mathematical optimization to map source and target data to a common space, they suffer from low transferability. Neural representations have proven to be more transferable; however, they are mainly designed for homogeneous environments. Drawing on the theory of domain adaptation, we propose a novel framework, Heterogeneous Adversarial Neural Domain Adaptation (HANDA), to effectively maximize the transferability in heterogeneous environments. HANDA conducts feature and distribution alignment in a unified neural network architecture and achieves domain invariance through adversarial kernel learning. Three experiments were conducted to evaluate the performance against the state-of-the-art HDA methods on major image and text e-commerce benchmarks. HANDA shows statistically significant improvement in predictive performance. The practical utility of HANDA was shown in real-world dark web online markets. HANDA is an important step towards successful domain adaptation in e-commerce applications.
Counteracting Dark Web Text-Based CAPTCHA with Generative Adversarial Learning for Proactive Cyber Threat Intelligence
Jan 14, 2022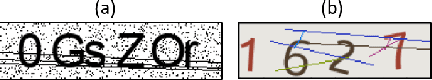
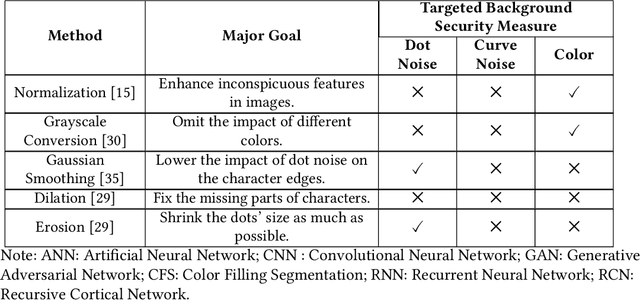
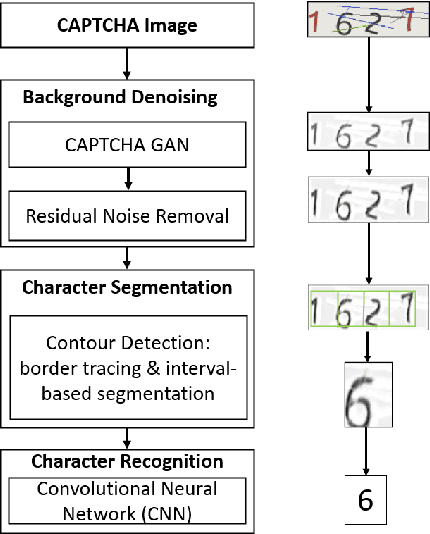
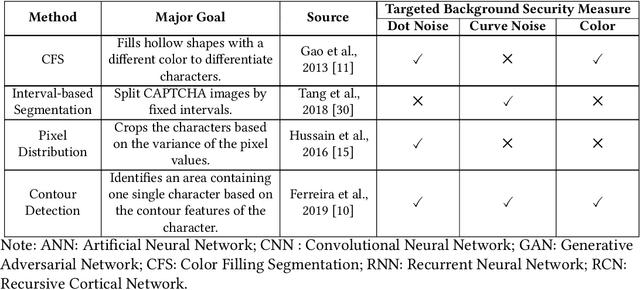
Automated monitoring of dark web (DW) platforms on a large scale is the first step toward developing proactive Cyber Threat Intelligence (CTI). While there are efficient methods for collecting data from the surface web, large-scale dark web data collection is often hindered by anti-crawling measures. In particular, text-based CAPTCHA serves as the most prevalent and prohibiting type of these measures in the dark web. Text-based CAPTCHA identifies and blocks automated crawlers by forcing the user to enter a combination of hard-to-recognize alphanumeric characters. In the dark web, CAPTCHA images are meticulously designed with additional background noise and variable character length to prevent automated CAPTCHA breaking. Existing automated CAPTCHA breaking methods have difficulties in overcoming these dark web challenges. As such, solving dark web text-based CAPTCHA has been relying heavily on human involvement, which is labor-intensive and time-consuming. In this study, we propose a novel framework for automated breaking of dark web CAPTCHA to facilitate dark web data collection. This framework encompasses a novel generative method to recognize dark web text-based CAPTCHA with noisy background and variable character length. To eliminate the need for human involvement, the proposed framework utilizes Generative Adversarial Network (GAN) to counteract dark web background noise and leverages an enhanced character segmentation algorithm to handle CAPTCHA images with variable character length. Our proposed framework, DW-GAN, was systematically evaluated on multiple dark web CAPTCHA testbeds. DW-GAN significantly outperformed the state-of-the-art benchmark methods on all datasets, achieving over 94.4% success rate on a carefully collected real-world dark web dataset...
Single-Shot Black-Box Adversarial Attacks Against Malware Detectors: A Causal Language Model Approach
Dec 03, 2021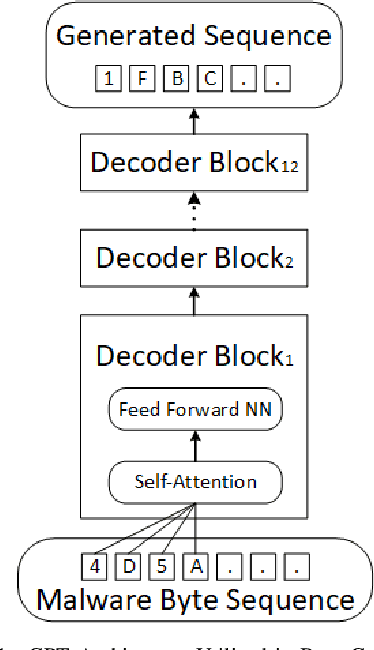
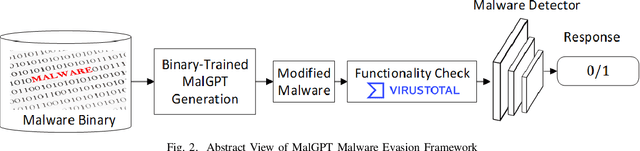
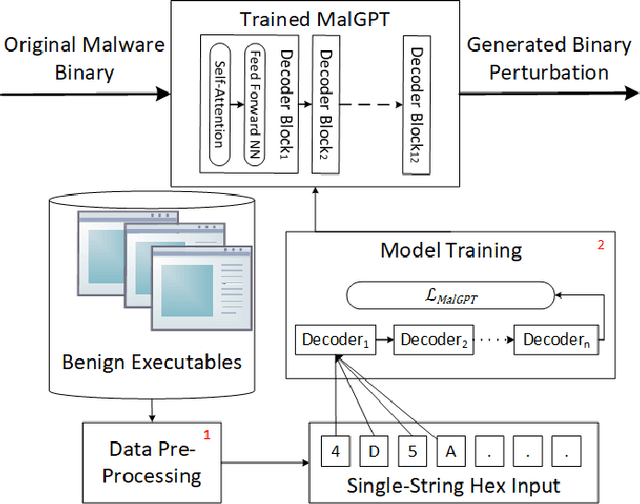
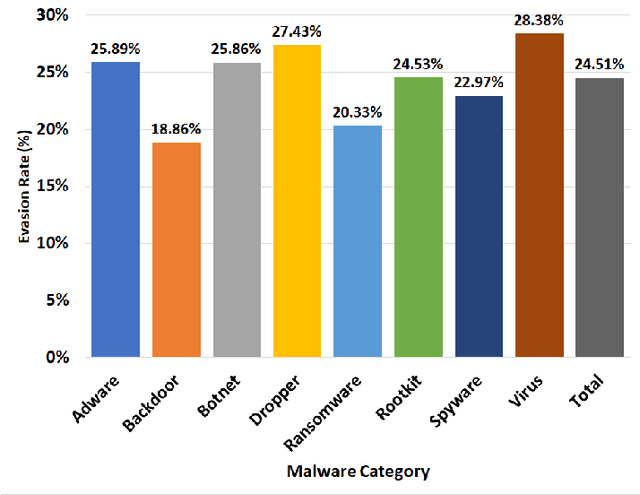
Deep Learning (DL)-based malware detectors are increasingly adopted for early detection of malicious behavior in cybersecurity. However, their sensitivity to adversarial malware variants has raised immense security concerns. Generating such adversarial variants by the defender is crucial to improving the resistance of DL-based malware detectors against them. This necessity has given rise to an emerging stream of machine learning research, Adversarial Malware example Generation (AMG), which aims to generate evasive adversarial malware variants that preserve the malicious functionality of a given malware. Within AMG research, black-box method has gained more attention than white-box methods. However, most black-box AMG methods require numerous interactions with the malware detectors to generate adversarial malware examples. Given that most malware detectors enforce a query limit, this could result in generating non-realistic adversarial examples that are likely to be detected in practice due to lack of stealth. In this study, we show that a novel DL-based causal language model enables single-shot evasion (i.e., with only one query to malware detector) by treating the content of the malware executable as a byte sequence and training a Generative Pre-Trained Transformer (GPT). Our proposed method, MalGPT, significantly outperformed the leading benchmark methods on a real-world malware dataset obtained from VirusTotal, achieving over 24.51\% evasion rate. MalGPT enables cybersecurity researchers to develop advanced defense capabilities by emulating large-scale realistic AMG.
Automated PII Extraction from Social Media for Raising Privacy Awareness: A Deep Transfer Learning Approach
Nov 11, 2021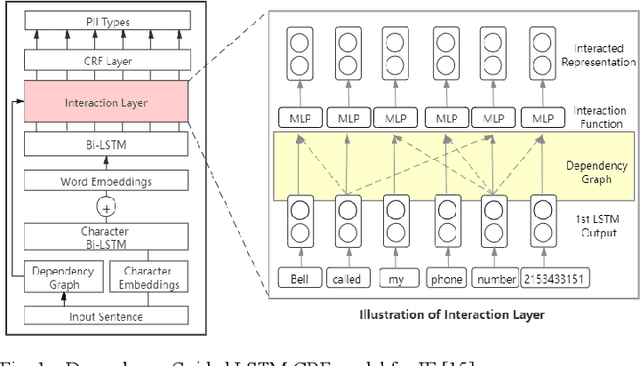
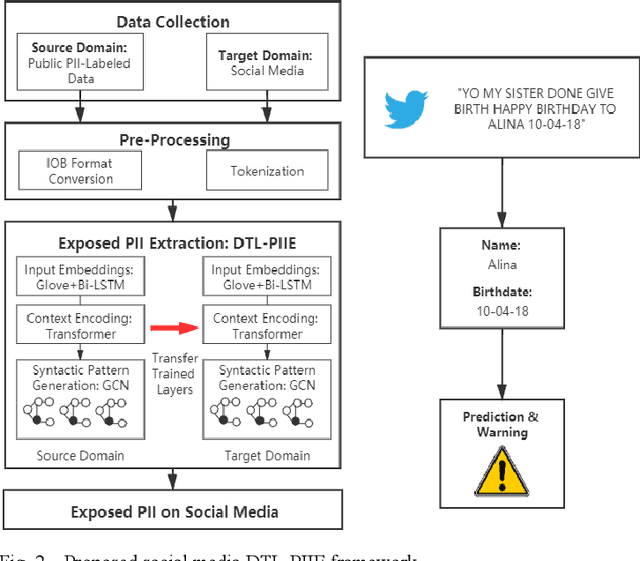
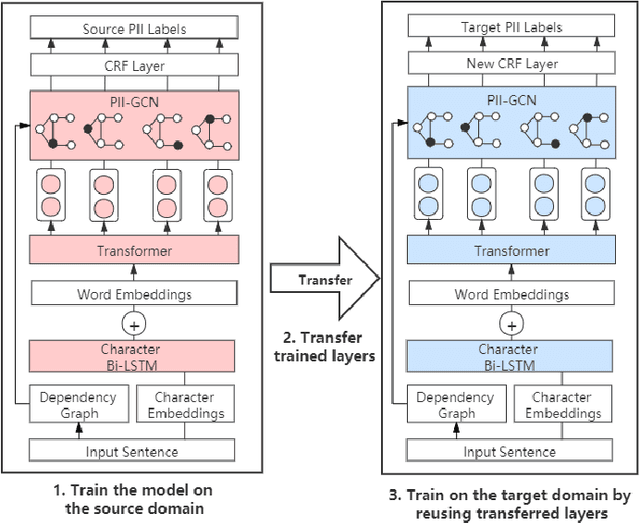
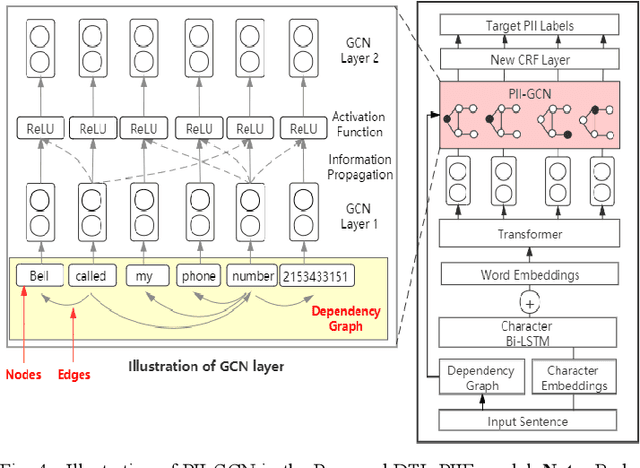
Internet users have been exposing an increasing amount of Personally Identifiable Information (PII) on social media. Such exposed PII can cause severe losses to the users, and informing users of their PII exposure is crucial to raise their privacy awareness and encourage them to take protective measures. To this end, advanced automatic techniques are needed. While Information Extraction (IE) techniques can be used to extract the PII automatically, Deep Learning (DL)-based IE models alleviate the need for feature engineering and further improve the efficiency. However, DL-based IE models often require large-scale labeled data for training, but PII-labeled social media posts are difficult to obtain due to privacy concerns. Also, these models rely heavily on pre-trained word embeddings, while PII in social media often varies in forms and thus has no fixed representations in pre-trained word embeddings. In this study, we propose the Deep Transfer Learning for PII Extraction (DTL-PIIE) framework to address these two limitations. DTL-PIIE transfers knowledge learned from publicly available PII data to social media to address the problem of rare PII-labeled data. Moreover, our framework leverages Graph Convolutional Networks (GCNs) to incorporate syntactic patterns to guide PIIE without relying on pre-trained word embeddings. Evaluation against benchmark IE models indicates that our approach outperforms state-of-the-art DL-based IE models. Our framework can facilitate various applications, such as PII misuse prediction and privacy risk assessment, protecting the privacy of internet users.
Binary Black-box Evasion Attacks Against Deep Learning-based Static Malware Detectors with Adversarial Byte-Level Language Model
Dec 14, 2020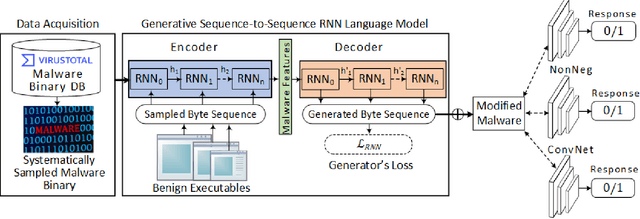
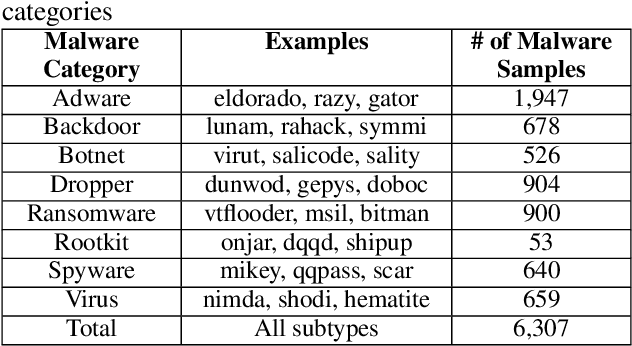
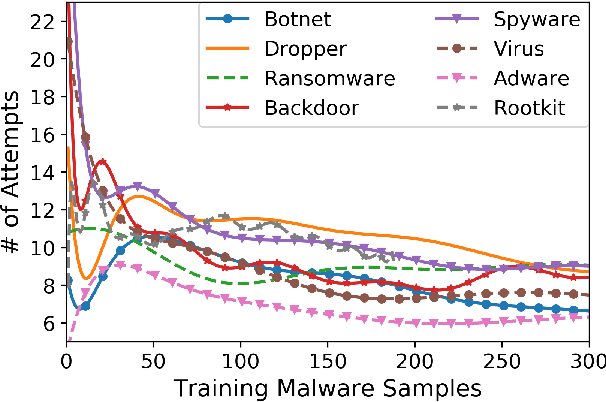
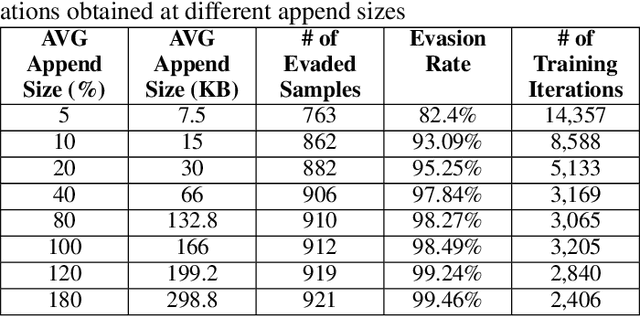
Anti-malware engines are the first line of defense against malicious software. While widely used, feature engineering-based anti-malware engines are vulnerable to unseen (zero-day) attacks. Recently, deep learning-based static anti-malware detectors have achieved success in identifying unseen attacks without requiring feature engineering and dynamic analysis. However, these detectors are susceptible to malware variants with slight perturbations, known as adversarial examples. Generating effective adversarial examples is useful to reveal the vulnerabilities of such systems. Current methods for launching such attacks require accessing either the specifications of the targeted anti-malware model, the confidence score of the anti-malware response, or dynamic malware analysis, which are either unrealistic or expensive. We propose MalRNN, a novel deep learning-based approach to automatically generate evasive malware variants without any of these restrictions. Our approach features an adversarial example generation process, which learns a language model via a generative sequence-to-sequence recurrent neural network to augment malware binaries. MalRNN effectively evades three recent deep learning-based malware detectors and outperforms current benchmark methods. Findings from applying our MalRNN on a real dataset with eight malware categories are discussed.
* Accepted in 35th AAAI Conference on Artificial Intelligence, Workshop on Robust, Secure, and Efficient Machine Learning (RSEML)