 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeGaussian: High-Fidelity 4D Human Reconstruction in Monocular Videos via Vision Priors
Feb 05, 2026We introduce ShapeGaussian, a high-fidelity, template-free method for 4D human reconstruction from casual monocular videos. Generic reconstruction methods lacking robust vision priors, such as 4DGS, struggle to capture high-deformation human motion without multi-view cues. While template-based approaches, primarily relying on SMPL, such as HUGS, can produce photorealistic results, they are highly susceptible to errors in human pose estimation, often leading to unrealistic artifacts. In contrast, ShapeGaussian effectively integrates template-free vision priors to achieve both high-fidelity and robust scene reconstructions. Our method follows a two-step pipeline: first, we learn a coarse, deformable geometry using pretrained models that estimate data-driven priors, providing a foundation for reconstruction. Then, we refine this geometry using a neural deformation model to capture fine-grained dynamic details. By leveraging 2D vision priors, we mitigate artifacts from erroneous pose estimation in template-based methods and employ multiple reference frames to resolve the invisibility issue of 2D keypoints in a template-free manner. Extensive experiments demonstrate that ShapeGaussian surpasses template-based methods in reconstruction accuracy, achieving superior visual quality and robustness across diverse human motions in casual monocular videos.
DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
Feb 04, 2026Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text--motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps.We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change.Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.
A Two-Stage GPU Kernel Tuner Combining Semantic Refactoring and Search-Based Optimization
Jan 21, 2026GPU code optimization is a key performance bottleneck for HPC workloads as well as large-model training and inference. Although compiler optimizations and hand-written kernels can partially alleviate this issue, achieving near-hardware-limit performance still relies heavily on manual code refactoring and parameter tuning. Recent progress in LLM-agent-based kernel generation and optimization has been reported, yet many approaches primarily focus on direct code rewriting, where parameter choices are often implicit and hard to control, or require human intervention, leading to unstable performance gains. This paper introduces a template-based rewriting layer on top of an agent-driven iterative loop: kernels are semantically refactored into explicitly parameterizable templates, and template parameters are then optimized via search-based autotuning, yielding more stable and higher-quality speedups. Experiments on a set of real-world kernels demonstrate speedups exceeding 3x in the best case. We extract representative CUDA kernels from SGLang as evaluation targets; the proposed agentic tuner iteratively performs templating, testing, analysis, and planning, and leverages profiling feedback to execute constrained parameter search under hardware resource limits. Compared to agent-only direct rewriting, the template-plus-search design significantly reduces the randomness of iterative optimization, making the process more interpretable and enabling a more systematic approach toward high-performance configurations. The proposed method can be further extended to OpenCL, HIP, and other backends to deliver automated performance optimization for real production workloads.
ReasAlign: Reasoning Enhanced Safety Alignment against Prompt Injection Attack
Jan 15, 2026Large Language Models (LLMs) have enabled the development of powerful agentic systems capable of automating complex workflows across various fields. However, these systems are highly vulnerable to indirect prompt injection attacks, where malicious instructions embedded in external data can hijack agent behavior. In this work, we present ReasAlign, a model-level solution to improve safety alignment against indirect prompt injection attacks. The core idea of ReasAlign is to incorporate structured reasoning steps to analyze user queries, detect conflicting instructions, and preserve the continuity of the user's intended tasks to defend against indirect injection attacks. To further ensure reasoning logic and accuracy, we introduce a test-time scaling mechanism with a preference-optimized judge model that scores reasoning steps and selects the best trajectory. Comprehensive evaluations across various benchmarks show that ReasAlign maintains utility comparable to an undefended model while consistently outperforming Meta SecAlign, the strongest prior guardrail. On the representative open-ended CyberSecEval2 benchmark, which includes multiple prompt-injected tasks, ReasAlign achieves 94.6% utility and only 3.6% ASR, far surpassing the state-of-the-art defensive model of Meta SecAlign (56.4% utility and 74.4% ASR). These results demonstrate that ReasAlign achieves the best trade-off between security and utility, establishing a robust and practical defense against prompt injection attacks in real-world agentic systems. Our code and experimental results could be found at https://github.com/leolee99/ReasAlign.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
CogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
Jan 05, 2026Despite significant progress, multimodal large language models continue to struggle with visual mathematical problem solving. Some recent works recognize that visual perception is a bottleneck in visual mathematical reasoning, but their solutions are limited to improving the extraction and interpretation of visual inputs. Notably, they all ignore the key issue of whether the extracted visual cues are faithfully integrated and properly utilized in subsequent reasoning. Motivated by this, we present CogFlow, a novel cognitive-inspired three-stage framework that incorporates a knowledge internalization stage, explicitly simulating the hierarchical flow of human reasoning: perception$\Rightarrow$internalization$\Rightarrow$reasoning. Inline with this hierarchical flow, we holistically enhance all its stages. We devise Synergistic Visual Rewards to boost perception capabilities in parametric and semantic spaces, jointly improving visual information extraction from symbols and diagrams. To guarantee faithful integration of extracted visual cues into subsequent reasoning, we introduce a Knowledge Internalization Reward model in the internalization stage, bridging perception and reasoning. Moreover, we design a Visual-Gated Policy Optimization algorithm to further enforce the reasoning is grounded with the visual knowledge, preventing models seeking shortcuts that appear coherent but are visually ungrounded reasoning chains. Moreover, we contribute a new dataset MathCog for model training, which contains samples with over 120K high-quality perception-reasoning aligned annotations. Comprehensive experiments and analysis on commonly used visual mathematical reasoning benchmarks validate the superiority of the proposed CogFlow.
Rethinking Jailbreak Detection of Large Vision Language Models with Representational Contrastive Scoring
Dec 12, 2025



Large Vision-Language Models (LVLMs) are vulnerable to a growing array of multimodal jailbreak attacks, necessitating defenses that are both generalizable to novel threats and efficient for practical deployment. Many current strategies fall short, either targeting specific attack patterns, which limits generalization, or imposing high computational overhead. While lightweight anomaly-detection methods offer a promising direction, we find that their common one-class design tends to confuse novel benign inputs with malicious ones, leading to unreliable over-rejection. To address this, we propose Representational Contrastive Scoring (RCS), a framework built on a key insight: the most potent safety signals reside within the LVLM's own internal representations. Our approach inspects the internal geometry of these representations, learning a lightweight projection to maximally separate benign and malicious inputs in safety-critical layers. This enables a simple yet powerful contrastive score that differentiates true malicious intent from mere novelty. Our instantiations, MCD (Mahalanobis Contrastive Detection) and KCD (K-nearest Contrastive Detection), achieve state-of-the-art performance on a challenging evaluation protocol designed to test generalization to unseen attack types. This work demonstrates that effective jailbreak detection can be achieved by applying simple, interpretable statistical methods to the appropriate internal representations, offering a practical path towards safer LVLM deployment. Our code is available on Github https://github.com/sarendis56/Jailbreak_Detection_RCS.
MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Dec 11, 2025Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/
SWiT-4D: Sliding-Window Transformer for Lossless and Parameter-Free Temporal 4D Generation
Dec 11, 2025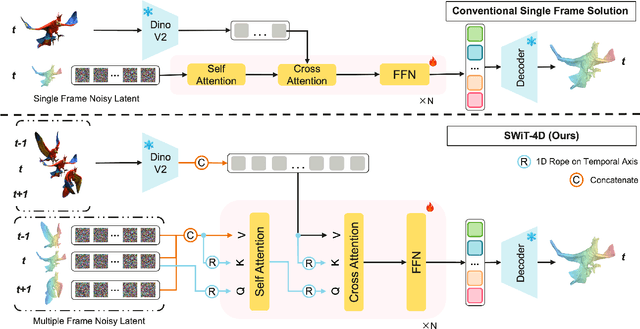
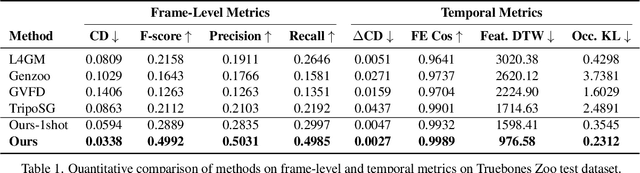
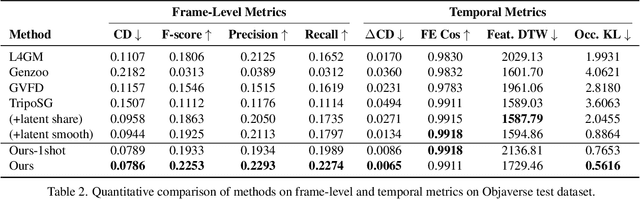

Despite significant progress in 4D content generation, the conversion of monocular videos into high-quality animated 3D assets with explicit 4D meshes remains considerably challenging. The scarcity of large-scale, naturally captured 4D mesh datasets further limits the ability to train generalizable video-to-4D models from scratch in a purely data-driven manner. Meanwhile, advances in image-to-3D generation, supported by extensive datasets, offer powerful prior models that can be leveraged. To better utilize these priors while minimizing reliance on 4D supervision, we introduce SWiT-4D, a Sliding-Window Transformer for lossless, parameter-free temporal 4D mesh generation. SWiT-4D integrates seamlessly with any Diffusion Transformer (DiT)-based image-to-3D generator, adding spatial-temporal modeling across video frames while preserving the original single-image forward process, enabling 4D mesh reconstruction from videos of arbitrary length. To recover global translation, we further introduce an optimization-based trajectory module tailored for static-camera monocular videos. SWiT-4D demonstrates strong data efficiency: with only a single short (<10s) video for fine-tuning, it achieves high-fidelity geometry and stable temporal consistency, indicating practical deployability under extremely limited 4D supervision. Comprehensive experiments on both in-domain zoo-test sets and challenging out-of-domain benchmarks (C4D, Objaverse, and in-the-wild videos) show that SWiT-4D consistently outperforms existing baselines in temporal smoothness. Project page: https://animotionlab.github.io/SWIT4D/
MoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025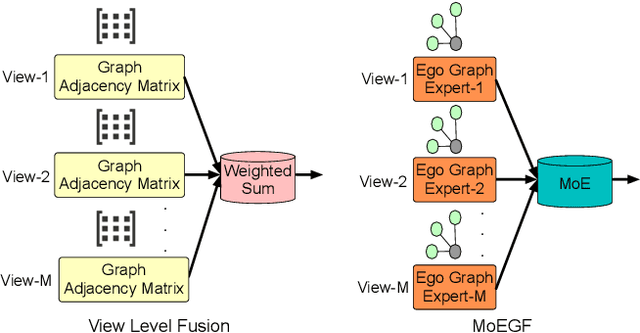
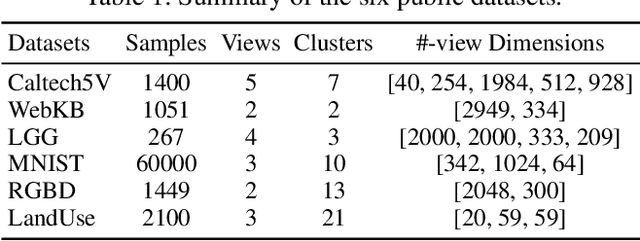
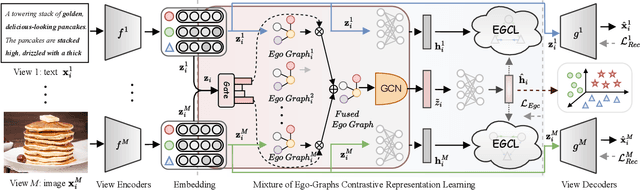
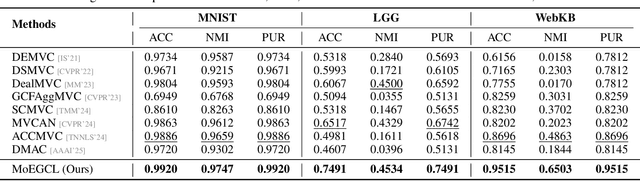
In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.