 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
Sequential LLM Framework for Fashion Recommendation
Oct 15, 2024



The fashion industry is one of the leading domains in the global e-commerce sector, prompting major online retailers to employ recommendation systems for product suggestions and customer convenience. While recommendation systems have been widely studied, most are designed for general e-commerce problems and struggle with the unique challenges of the fashion domain. To address these issues, we propose a sequential fashion recommendation framework that leverages a pre-trained large language model (LLM) enhanced with recommendation-specific prompts. Our framework employs parameter-efficient fine-tuning with extensive fashion data and introduces a novel mix-up-based retrieval technique for translating text into relevant product suggestions. Extensive experiments show our proposed framework significantly enhances fashion recommendation performance.
EIVEN: Efficient Implicit Attribute Value Extraction using Multimodal LLM
Apr 13, 2024
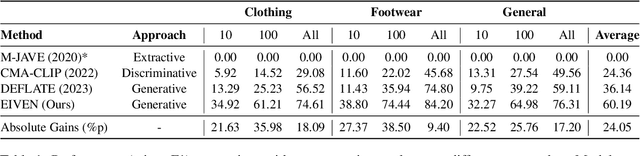
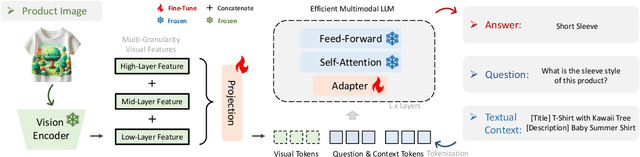
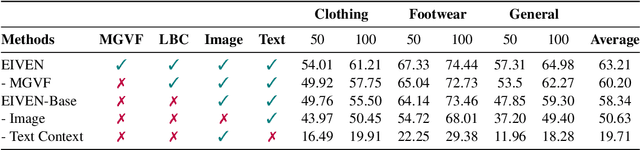
In e-commerce, accurately extracting product attribute values from multimodal data is crucial for improving user experience and operational efficiency of retailers. However, previous approaches to multimodal attribute value extraction often struggle with implicit attribute values embedded in images or text, rely heavily on extensive labeled data, and can easily confuse similar attribute values. To address these issues, we introduce EIVEN, a data- and parameter-efficient generative framework that pioneers the use of multimodal LLM for implicit attribute value extraction. EIVEN leverages the rich inherent knowledge of a pre-trained LLM and vision encoder to reduce reliance on labeled data. We also introduce a novel Learning-by-Comparison technique to reduce model confusion by enforcing attribute value comparison and difference identification. Additionally, we construct initial open-source datasets for multimodal implicit attribute value extraction. Our extensive experiments reveal that EIVEN significantly outperforms existing methods in extracting implicit attribute values while requiring less labeled data.