 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTodyComm: Task-Oriented Dynamic Communication for Multi-Round LLM-based Multi-Agent System
Feb 03, 2026Multi-round LLM-based multi-agent systems rely on effective communication structures to support collaboration across rounds. However, most existing methods employ a fixed communication topology during inference, which falls short in many realistic applications where the agents' roles may change \textit{across rounds} due to dynamic adversary, task progression, or time-varying constraints such as communication bandwidth. In this paper, we propose addressing this issue through TodyComm, a \textbf{t}ask-\textbf{o}riented \textbf{dy}namic \textbf{comm}unication algorithm. It produces behavior-driven collaboration topologies that adapt to the dynamics at each round, optimizing the utility for the task through policy gradient. Experiments on five benchmarks demonstrate that under both dynamic adversary and communications budgets, TodyComm delivers superior task effectiveness while retaining token efficiency and scalability.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Jun 11, 2025Recent improvements in large language models (LLMs) have led many researchers to focus on building fully autonomous AI agents. This position paper questions whether this approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of human. We suggest a different approach: LLM-based Human-Agent Systems (LLM-HAS), where AI works with humans rather than replacing them. By keeping human involved to provide guidance, answer questions, and maintain control, these systems can be more trustworthy and adaptable. Looking at examples from healthcare, finance, and software development, we show how human-AI teamwork can handle complex tasks better than AI working alone. We also discuss the challenges of building these collaborative systems and offer practical solutions. This paper argues that progress in AI should not be measured by how independent systems become, but by how well they can work with humans. The most promising future for AI is not in systems that take over human roles, but in those that enhance human capabilities through meaningful partnership.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
A Survey on Large Language Model based Human-Agent Systems
May 01, 2025Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-LLM-Based-Human-Agent-System-Papers.
Semi-Supervised In-Context Learning: A Baseline Study
Mar 04, 2025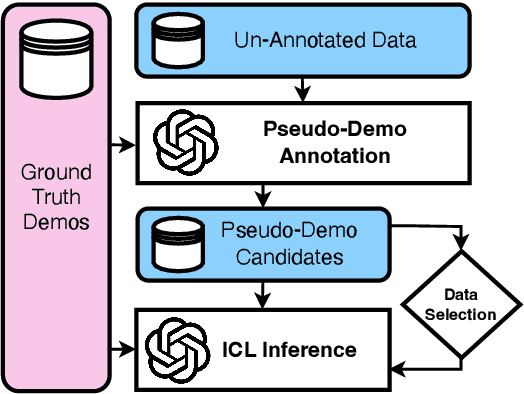
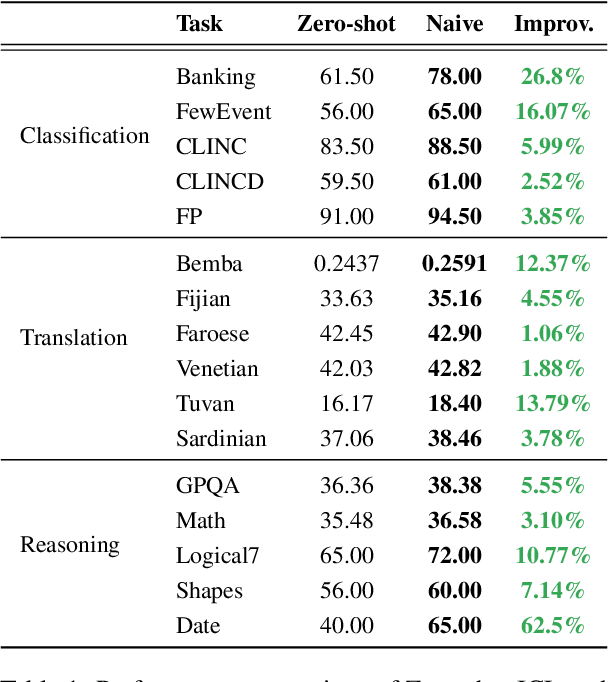
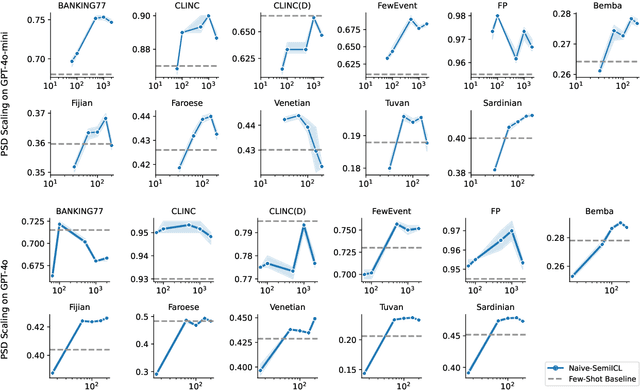
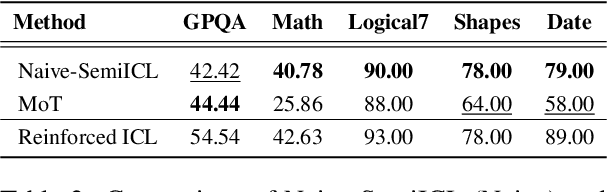
Most existing work in data selection for In-Context Learning (ICL) has focused on constructing demonstrations from ground truth annotations, with limited attention given to selecting reliable self-generated annotations. In this work, we propose a three-step semi-supervised ICL framework: annotation generation, demonstration selection, and semi-supervised inference. Our baseline, Naive-SemiICL, which prompts select high-confidence self-generated demonstrations for ICL prompting, outperforms a 16-shot baseline by an average of 9.94% across 16 datasets. We further introduce IterPSD, an annotation approach that refines pseudo-demonstrations iteratively, achieving up to 6.8% additional gains in classification tasks. Lastly, we reveal a scaling law for semi-supervised ICL, where models achieve optimal performance with over 1,000 demonstrations.
LLMInit: A Free Lunch from Large Language Models for Selective Initialization of Recommendation
Mar 03, 2025Collaborative filtering models, particularly graph-based approaches, have demonstrated strong performance in capturing user-item interactions for recommendation systems. However, they continue to struggle in cold-start and data-sparse scenarios. The emergence of large language models (LLMs) like GPT and LLaMA presents new possibilities for enhancing recommendation performance, especially in cold-start settings. Despite their promise, LLMs pose challenges related to scalability and efficiency due to their high computational demands and limited ability to model complex user-item relationships effectively. In this work, we introduce a novel perspective on leveraging LLMs for CF model initialization. Through experiments, we uncover an embedding collapse issue when scaling CF models to larger embedding dimensions. To effectively harness large-scale LLM embeddings, we propose innovative selective initialization strategies utilizing random, uniform, and variance-based index sampling. Our comprehensive evaluation on multiple real-world datasets demonstrates significant performance gains across various CF models while maintaining a lower computational cost compared to existing LLM-based recommendation approaches.
TestNUC: Enhancing Test-Time Computing Approaches through Neighboring Unlabeled Data Consistency
Feb 26, 2025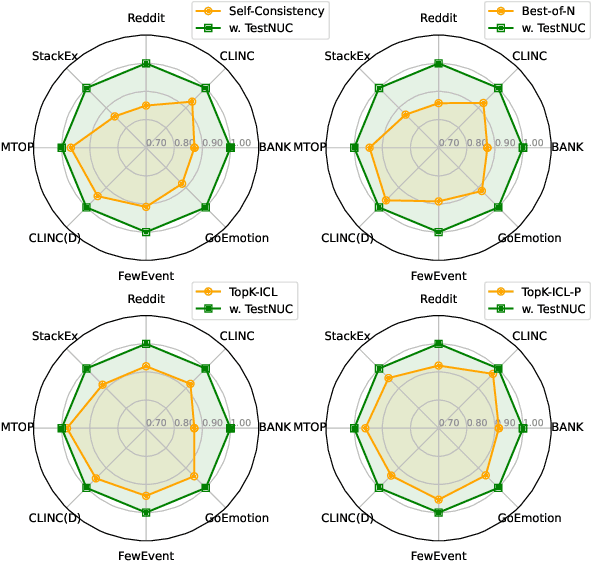
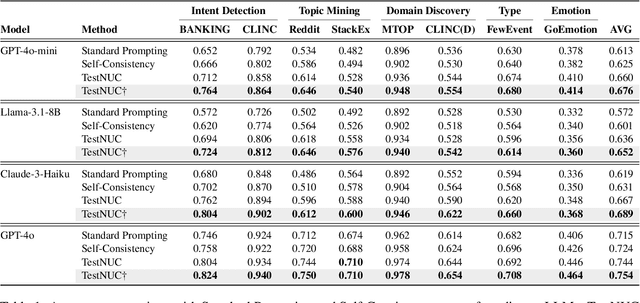
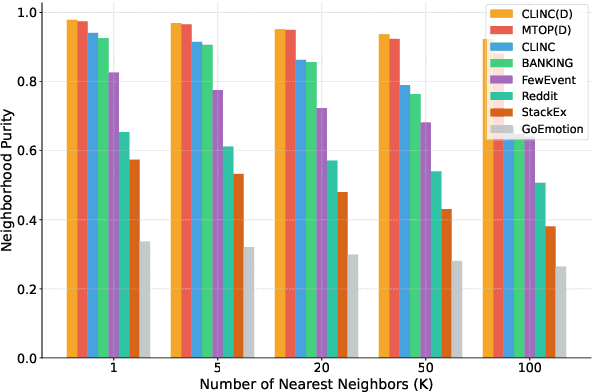
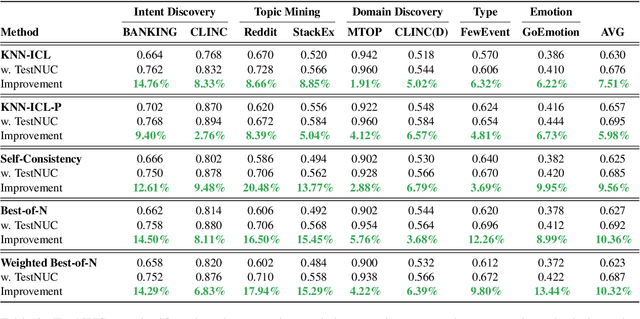
Test-time computing approaches, which leverage additional computational resources during inference, have been proven effective in enhancing large language model performance. This work introduces a novel, linearly scaling approach, TestNUC, that improves test-time predictions by leveraging the local consistency of neighboring unlabeled data-it classifies an input instance by considering not only the model's prediction on that instance but also on neighboring unlabeled instances. We evaluate TestNUC across eight diverse datasets, spanning intent classification, topic mining, domain discovery, and emotion detection, demonstrating its consistent superiority over baseline methods such as standard prompting and self-consistency. Furthermore, TestNUC can be seamlessly integrated with existing test-time computing approaches, substantially boosting their performance. Our analysis reveals that TestNUC scales effectively with increasing amounts of unlabeled data and performs robustly across different embedding models, making it practical for real-world applications. Our code is available at https://github.com/HenryPengZou/TestNUC.
GLEAN: Generalized Category Discovery with Diverse and Quality-Enhanced LLM Feedback
Feb 25, 2025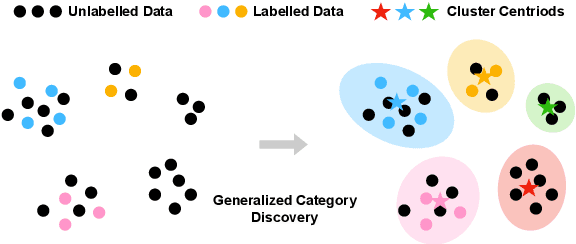
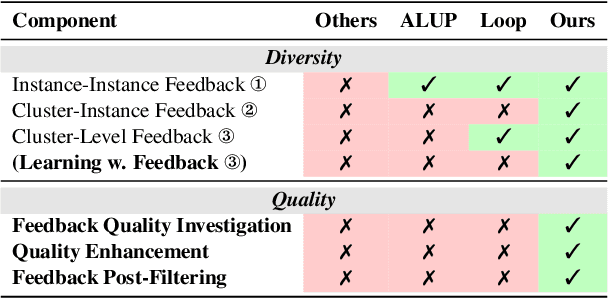
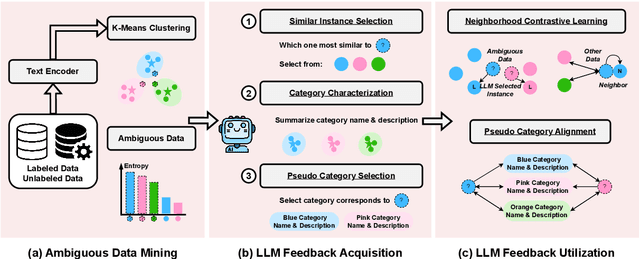
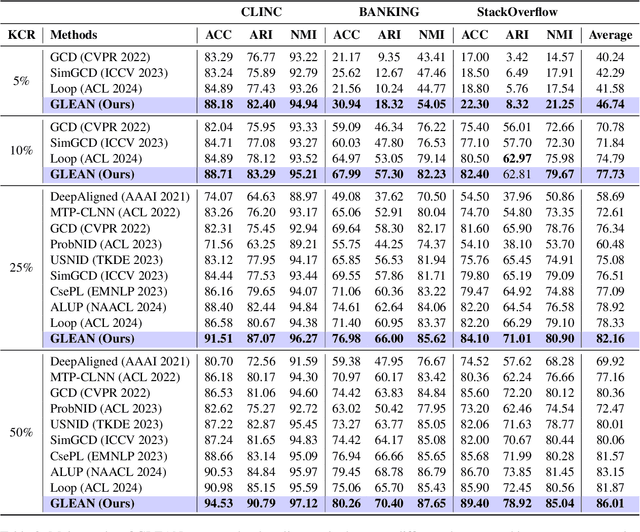
Generalized Category Discovery (GCD) is a practical and challenging open-world task that aims to recognize both known and novel categories in unlabeled data using limited labeled data from known categories. Due to the lack of supervision, previous GCD methods face significant challenges, such as difficulty in rectifying errors for confusing instances, and inability to effectively uncover and leverage the semantic meanings of discovered clusters. Therefore, additional annotations are usually required for real-world applicability. However, human annotation is extremely costly and inefficient. To address these issues, we propose GLEAN, a unified framework for generalized category discovery that actively learns from diverse and quality-enhanced LLM feedback. Our approach leverages three different types of LLM feedback to: (1) improve instance-level contrastive features, (2) generate category descriptions, and (3) align uncertain instances with LLM-selected category descriptions. Extensive experiments demonstrate the superior performance of \MethodName over state-of-the-art models across diverse datasets, metrics, and supervision settings. Our code is available at https://github.com/amazon-science/Glean.
Multi-Agent Autonomous Driving Systems with Large Language Models: A Survey of Recent Advances
Feb 24, 2025Autonomous Driving Systems (ADSs) are revolutionizing transportation by reducing human intervention, improving operational efficiency, and enhancing safety. Large Language Models (LLMs), known for their exceptional planning and reasoning capabilities, have been integrated into ADSs to assist with driving decision-making. However, LLM-based single-agent ADSs face three major challenges: limited perception, insufficient collaboration, and high computational demands. To address these issues, recent advancements in LLM-based multi-agent ADSs have focused on improving inter-agent communication and cooperation. This paper provides a frontier survey of LLM-based multi-agent ADSs. We begin with a background introduction to related concepts, followed by a categorization of existing LLM-based approaches based on different agent interaction modes. We then discuss agent-human interactions in scenarios where LLM-based agents engage with humans. Finally, we summarize key applications, datasets, and challenges in this field to support future research (https://anonymous.4open.science/r/LLM-based_Multi-agent_ADS-3A5C/README.md).