 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised In-Context Learning: A Baseline Study
Paper and Code
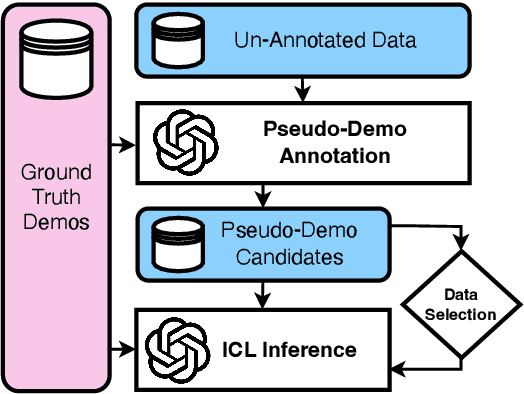
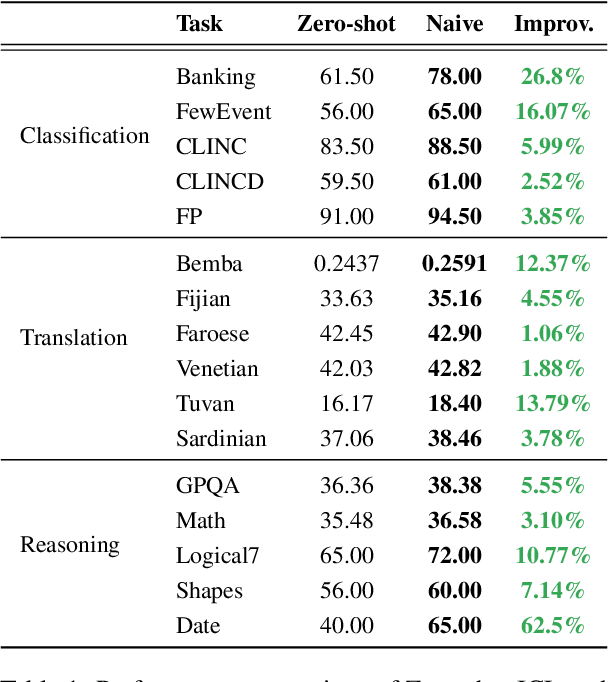
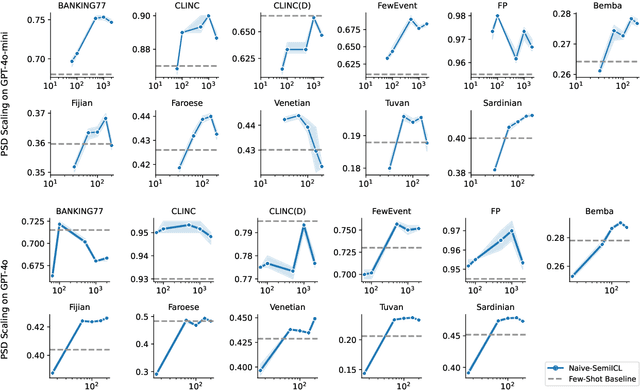
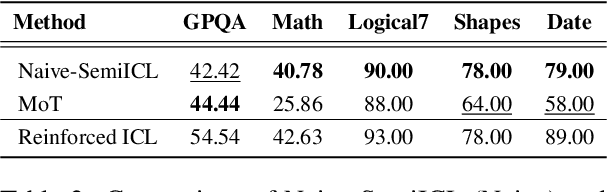
Most existing work in data selection for In-Context Learning (ICL) has focused on constructing demonstrations from ground truth annotations, with limited attention given to selecting reliable self-generated annotations. In this work, we propose a three-step semi-supervised ICL framework: annotation generation, demonstration selection, and semi-supervised inference. Our baseline, Naive-SemiICL, which prompts select high-confidence self-generated demonstrations for ICL prompting, outperforms a 16-shot baseline by an average of 9.94% across 16 datasets. We further introduce IterPSD, an annotation approach that refines pseudo-demonstrations iteratively, achieving up to 6.8% additional gains in classification tasks. Lastly, we reveal a scaling law for semi-supervised ICL, where models achieve optimal performance with over 1,000 demonstrations.