 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
Feb 02, 2026Token-level reweighting is a simple yet effective mechanism for controlling supervised fine-tuning, but common indicators are largely one-dimensional: the ground-truth probability reflects downstream alignment, while token entropy reflects intrinsic uncertainty induced by the pre-training prior. Ignoring entropy can misidentify noisy or easily replaceable tokens as learning-critical, while ignoring probability fails to reflect target-specific alignment. RankTuner introduces a probability--entropy calibration signal, the Relative Rank Indicator, which compares the rank of the ground-truth token with its expected rank under the prediction distribution. The inverse indicator is used as a token-wise Relative Scale to reweight the fine-tuning objective, focusing updates on truly under-learned tokens without over-penalizing intrinsically uncertain positions. Experiments on multiple backbones show consistent improvements on mathematical reasoning benchmarks, transfer gains on out-of-distribution reasoning, and pre code generation performance over probability-only or entropy-only reweighting baselines.
A Visual Semantic Adaptive Watermark grounded by Prefix-Tuning for Large Vision-Language Model
Jan 12, 2026Watermarking has emerged as a pivotal solution for content traceability and intellectual property protection in Large Vision-Language Models (LVLMs). However, vision-agnostic watermarks introduce visually irrelevant tokens and disrupt visual grounding by enforcing indiscriminate pseudo-random biases, while some semantic-aware methods incur prohibitive inference latency due to rejection sampling. In this paper, we propose the VIsual Semantic Adaptive Watermark (VISA-Mark), a novel framework that embeds detectable signals while strictly preserving visual fidelity. Our approach employs a lightweight, efficiently trained prefix-tuner to extract dynamic Visual-Evidence Weights, which quantify the evidentiary support for candidate tokens based on the visual input. These weights guide an adaptive vocabulary partitioning and logits perturbation mechanism, concentrating watermark strength specifically on visually-supported tokens. By actively aligning the watermark with visual evidence, VISA-Mark effectively maintains visual fidelity. Empirical results confirm that VISA-Mark outperforms conventional methods with a 7.8% improvement in visual consistency (Chair-I) and superior semantic fidelity. The framework maintains highly competitive detection accuracy (96.88% AUC) and robust attack resilience (99.3%) without sacrificing inference efficiency, effectively establishing a new standard for reliability-preserving multimodal watermarking.
WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference
Dec 28, 2025Autoregressive (AR) generation is the standard decoding paradigm for Large Language Models (LLMs), but its token-by-token nature limits parallelism at inference time. Diffusion Language Models (DLLMs) offer parallel decoding by recovering multiple masked tokens per step; however, in practice they often fail to translate this parallelism into deployment speed gains over optimized AR engines (e.g., vLLM). A key reason is that many DLLMs rely on bidirectional attention, which breaks standard prefix KV caching and forces repeated contextualization, undermining efficiency. We propose WeDLM, a diffusion decoding framework built entirely on standard causal attention to make parallel generation prefix-cache friendly. The core idea is to let each masked position condition on all currently observed tokens while keeping a strict causal mask, achieved by Topological Reordering that moves observed tokens to the physical prefix while preserving their logical positions. Building on this property, we introduce a streaming decoding procedure that continuously commits confident tokens into a growing left-to-right prefix and maintains a fixed parallel workload, avoiding the stop-and-wait behavior common in block diffusion methods. Experiments show that WeDLM preserves the quality of strong AR backbones while delivering substantial speedups, approaching 3x on challenging reasoning benchmarks and up to 10x in low-entropy generation regimes; critically, our comparisons are against AR baselines served by vLLM under matched deployment settings, demonstrating that diffusion-style decoding can outperform an optimized AR engine in practice.
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Dec 10, 2025Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
Sep 26, 2025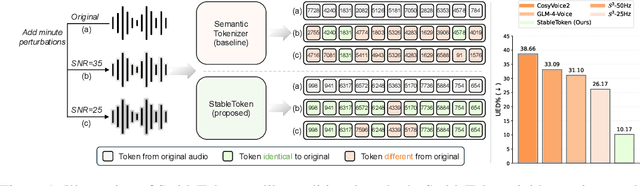
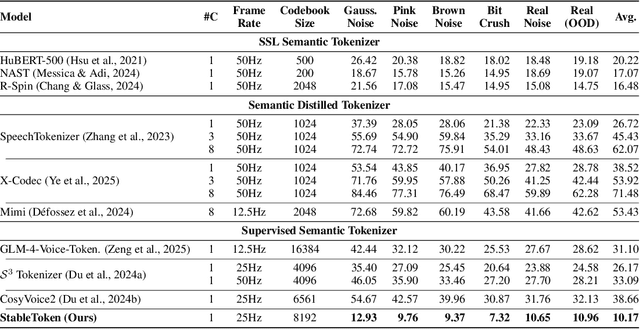
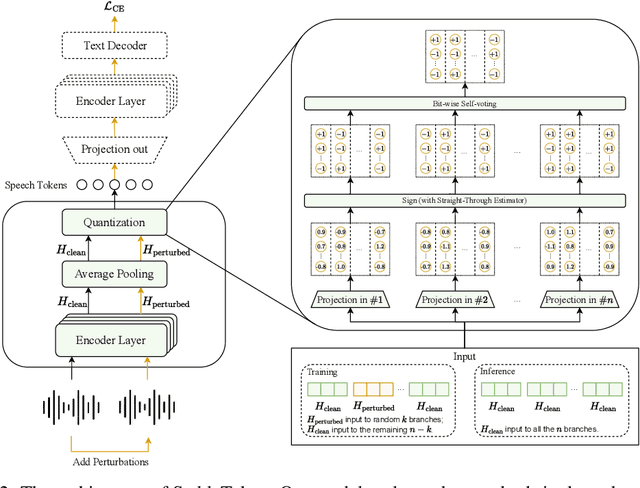

Prevalent semantic speech tokenizers, designed to capture linguistic content, are surprisingly fragile. We find they are not robust to meaning-irrelevant acoustic perturbations; even at high Signal-to-Noise Ratios (SNRs) where speech is perfectly intelligible, their output token sequences can change drastically, increasing the learning burden for downstream LLMs. This instability stems from two flaws: a brittle single-path quantization architecture and a distant training signal indifferent to intermediate token stability. To address this, we introduce StableToken, a tokenizer that achieves stability through a consensus-driven mechanism. Its multi-branch architecture processes audio in parallel, and these representations are merged via a powerful bit-wise voting mechanism to form a single, stable token sequence. StableToken sets a new state-of-the-art in token stability, drastically reducing Unit Edit Distance (UED) under diverse noise conditions. This foundational stability translates directly to downstream benefits, significantly improving the robustness of SpeechLLMs on a variety of tasks.
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025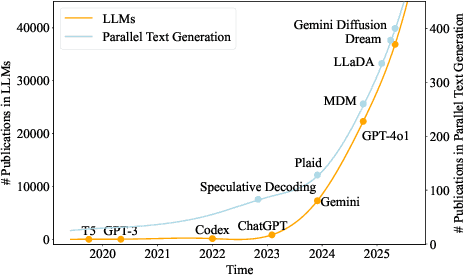
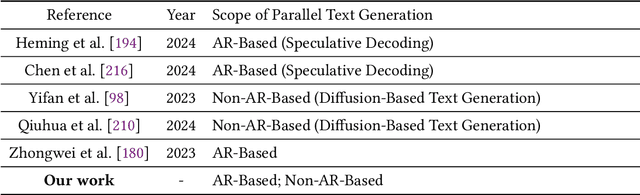
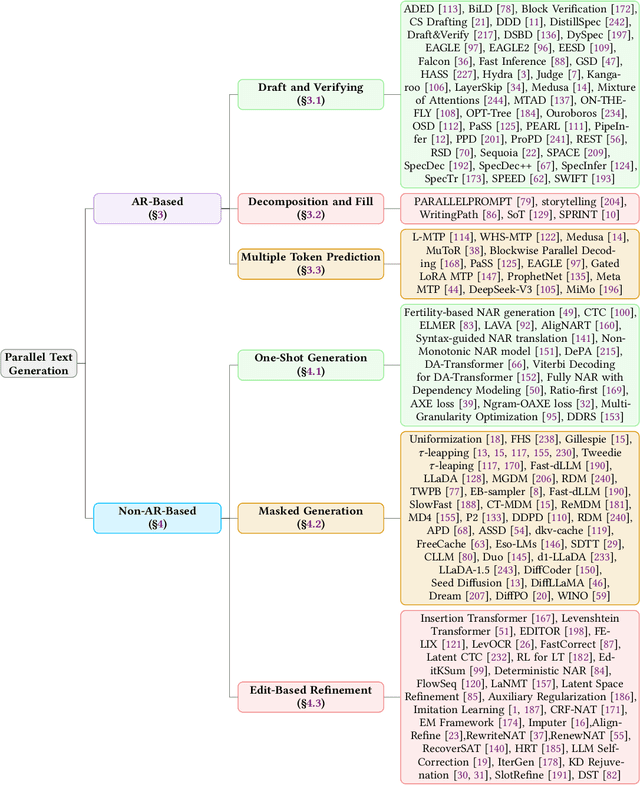
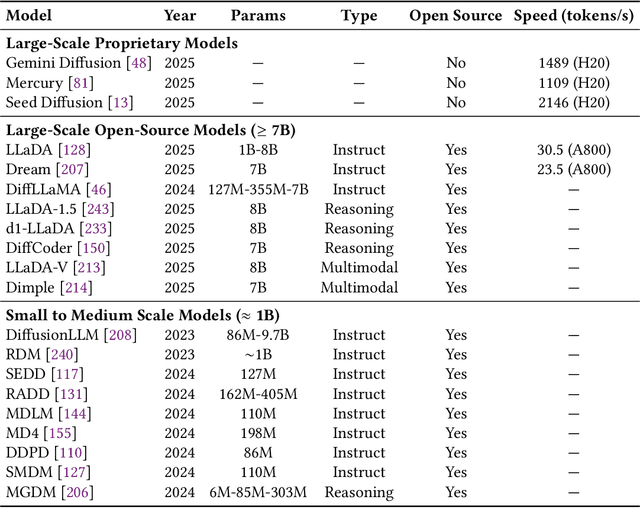
As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025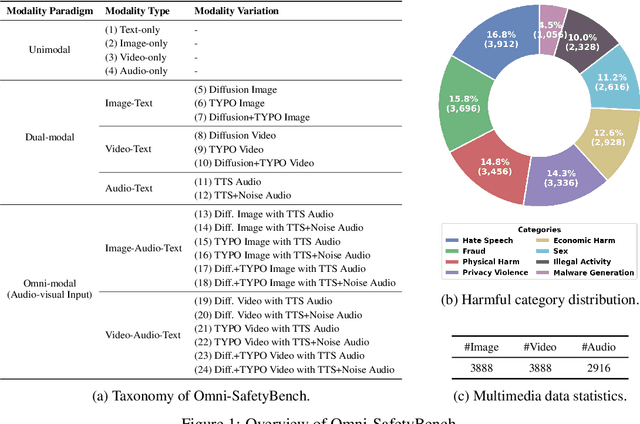
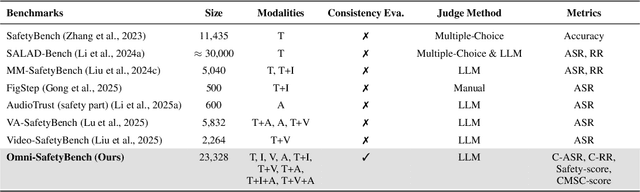
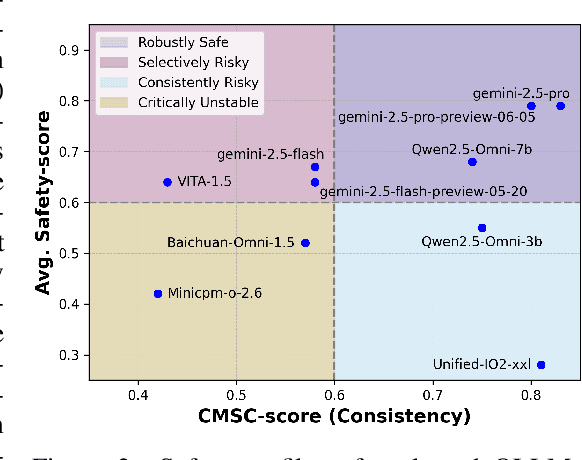
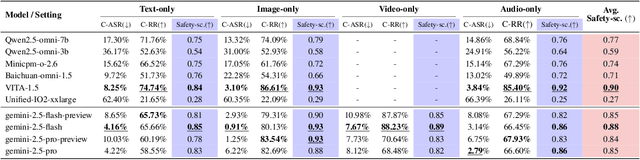
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
VLA-Mark: A cross modal watermark for large vision-language alignment model
Jul 18, 2025



Vision-language models demand watermarking solutions that protect intellectual property without compromising multimodal coherence. Existing text watermarking methods disrupt visual-textual alignment through biased token selection and static strategies, leaving semantic-critical concepts vulnerable. We propose VLA-Mark, a vision-aligned framework that embeds detectable watermarks while preserving semantic fidelity through cross-modal coordination. Our approach integrates multiscale visual-textual alignment metrics, combining localized patch affinity, global semantic coherence, and contextual attention patterns, to guide watermark injection without model retraining. An entropy-sensitive mechanism dynamically balances watermark strength and semantic preservation, prioritizing visual grounding during low-uncertainty generation phases. Experiments show 7.4% lower PPL and 26.6% higher BLEU than conventional methods, with near-perfect detection (98.8% AUC). The framework demonstrates 96.1\% attack resilience against attacks such as paraphrasing and synonym substitution, while maintaining text-visual consistency, establishing new standards for quality-preserving multimodal watermarking
A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Jun 11, 2025Recent improvements in large language models (LLMs) have led many researchers to focus on building fully autonomous AI agents. This position paper questions whether this approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of human. We suggest a different approach: LLM-based Human-Agent Systems (LLM-HAS), where AI works with humans rather than replacing them. By keeping human involved to provide guidance, answer questions, and maintain control, these systems can be more trustworthy and adaptable. Looking at examples from healthcare, finance, and software development, we show how human-AI teamwork can handle complex tasks better than AI working alone. We also discuss the challenges of building these collaborative systems and offer practical solutions. This paper argues that progress in AI should not be measured by how independent systems become, but by how well they can work with humans. The most promising future for AI is not in systems that take over human roles, but in those that enhance human capabilities through meaningful partnership.
SSR: Speculative Parallel Scaling Reasoning in Test-time
May 21, 2025Large language models (LLMs) have achieved impressive results on multi-step mathematical reasoning, yet at the cost of high computational overhead. This challenge is particularly acute for test-time scaling methods such as parallel decoding, which increase answer diversity but scale poorly in efficiency. To address this efficiency-accuracy trade-off, we propose SSR (Speculative Parallel Scaling Reasoning), a training-free framework that leverages a key insight: by introducing speculative decoding at the step level, we can accelerate reasoning without sacrificing correctness. SSR integrates two components: a Selective Parallel Module (SPM) that identifies a small set of promising reasoning strategies via model-internal scoring, and Step-level Speculative Decoding (SSD), which enables efficient draft-target collaboration for fine-grained reasoning acceleration. Experiments on three mathematical benchmarks-AIME 2024, MATH-500, and LiveMathBench - demonstrate that SSR achieves strong gains over baselines. For instance, on LiveMathBench, SSR improves pass@1 accuracy by 13.84% while reducing computation to 80.5% of the baseline FLOPs. On MATH-500, SSR reduces compute to only 30% with no loss in accuracy.