 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised In-Context Learning: A Baseline Study
Mar 04, 2025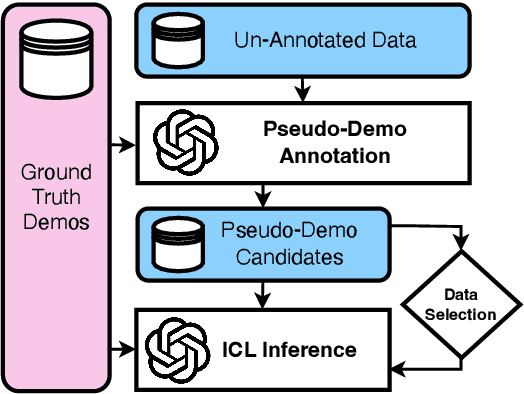
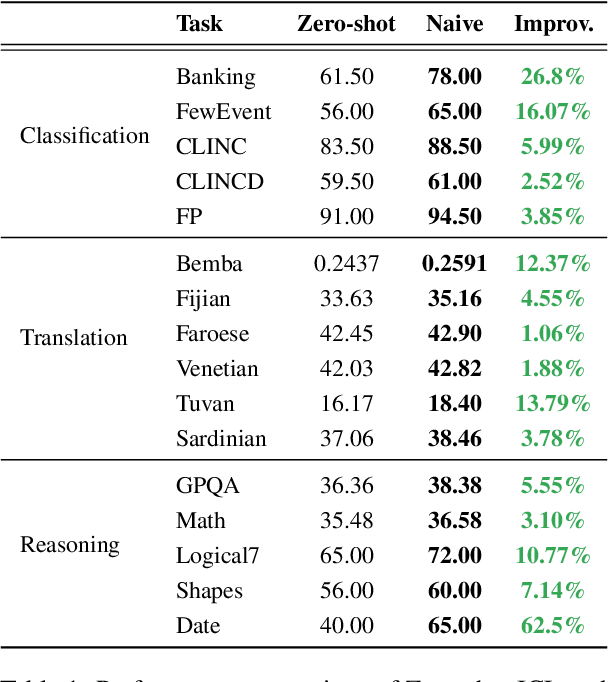
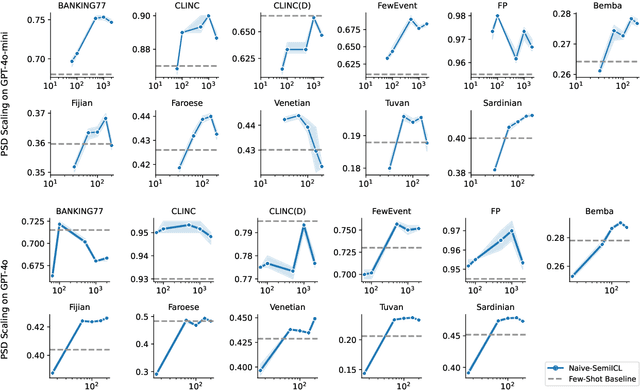
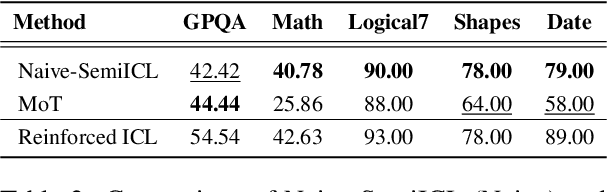
Most existing work in data selection for In-Context Learning (ICL) has focused on constructing demonstrations from ground truth annotations, with limited attention given to selecting reliable self-generated annotations. In this work, we propose a three-step semi-supervised ICL framework: annotation generation, demonstration selection, and semi-supervised inference. Our baseline, Naive-SemiICL, which prompts select high-confidence self-generated demonstrations for ICL prompting, outperforms a 16-shot baseline by an average of 9.94% across 16 datasets. We further introduce IterPSD, an annotation approach that refines pseudo-demonstrations iteratively, achieving up to 6.8% additional gains in classification tasks. Lastly, we reveal a scaling law for semi-supervised ICL, where models achieve optimal performance with over 1,000 demonstrations.
TestNUC: Enhancing Test-Time Computing Approaches through Neighboring Unlabeled Data Consistency
Feb 26, 2025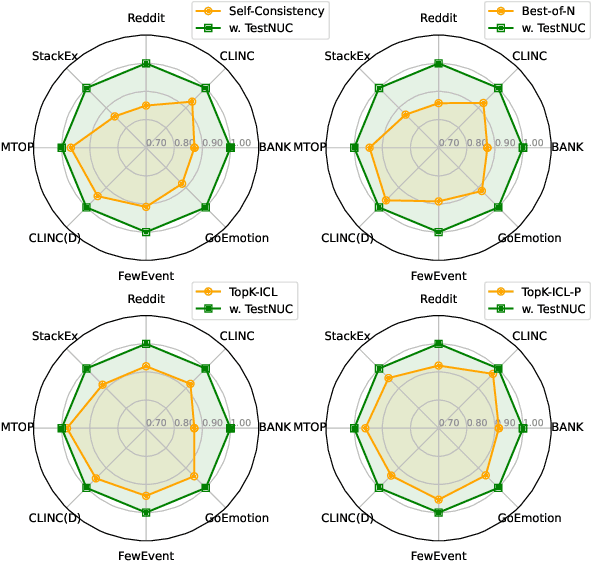
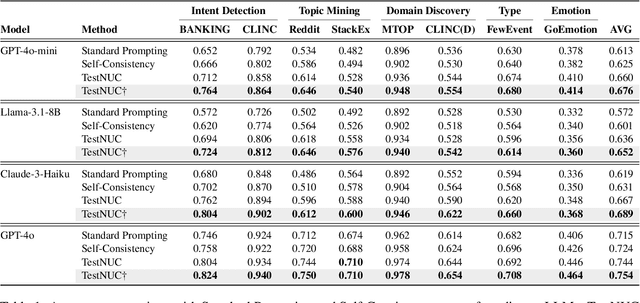
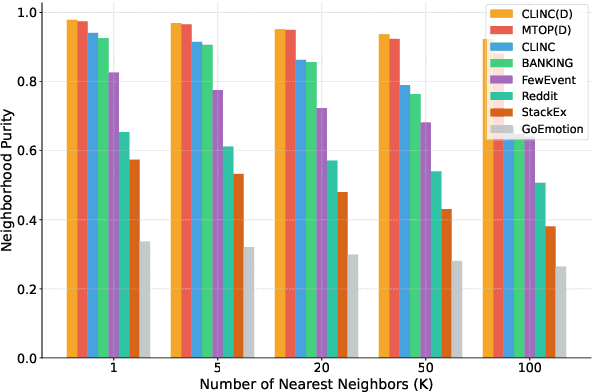
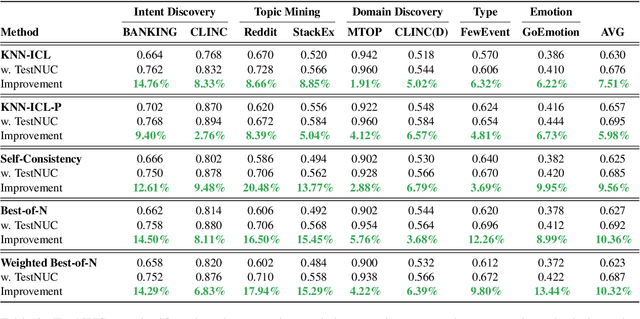
Test-time computing approaches, which leverage additional computational resources during inference, have been proven effective in enhancing large language model performance. This work introduces a novel, linearly scaling approach, TestNUC, that improves test-time predictions by leveraging the local consistency of neighboring unlabeled data-it classifies an input instance by considering not only the model's prediction on that instance but also on neighboring unlabeled instances. We evaluate TestNUC across eight diverse datasets, spanning intent classification, topic mining, domain discovery, and emotion detection, demonstrating its consistent superiority over baseline methods such as standard prompting and self-consistency. Furthermore, TestNUC can be seamlessly integrated with existing test-time computing approaches, substantially boosting their performance. Our analysis reveals that TestNUC scales effectively with increasing amounts of unlabeled data and performs robustly across different embedding models, making it practical for real-world applications. Our code is available at https://github.com/HenryPengZou/TestNUC.