 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
Mar 19, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success in interpreting natural scenes, their ability to process discrete symbols -- the fundamental building blocks of human cognition -- remains a critical open question. Unlike continuous visual data, symbols such as mathematical formulas, chemical structures, and linguistic characters require precise, deeper interpretation. This paper introduces a comprehensive benchmark to evaluate how top-tier MLLMs navigate these "discrete semantic spaces" across five domains: language, culture, mathematics, physics, and chemistry. Our investigation uncovers a counterintuitive phenomenon: models often fail at basic symbol recognition yet succeed in complex reasoning tasks, suggesting they rely on linguistic probability rather than true visual perception. By exposing this "cognitive mismatch", we highlight a significant gap in current AI capabilities: the struggle to truly perceive and understand the symbolic languages that underpin scientific discovery and abstract thought. This work offers a roadmap for developing more rigorous, human-aligned intelligent systems.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
EvoConfig: Self-Evolving Multi-Agent Systems for Efficient Autonomous Environment Configuration
Jan 23, 2026A reliable executable environment is the foundation for ensuring that large language models solve software engineering tasks. Due to the complex and tedious construction process, large-scale configuration is relatively inefficient. However, most methods always overlook fine-grained analysis of the actions performed by the agent, making it difficult to handle complex errors and resulting in configuration failures. To address this bottleneck, we propose EvoConfig, an efficient environment configuration framework that optimizes multi-agent collaboration to build correct runtime environments. EvoConfig features an expert diagnosis module for fine-grained post-execution analysis, and a self-evolving mechanism that lets expert agents self-feedback and dynamically adjust error-fixing priorities in real time. Empirically, EvoConfig matches the previous state-of-the-art Repo2Run on Repo2Run's 420 repositories, while delivering clear gains on harder cases: on the more challenging Envbench, EvoConfig achieves a 78.1% success rate, outperforming Repo2Run by 7.1%. Beyond end-to-end success, EvoConfig also demonstrates stronger debugging competence, achieving higher accuracy in error identification and producing more effective repair recommendations than existing methods.
TangramPuzzle: Evaluating Multimodal Large Language Models with Compositional Spatial Reasoning
Jan 23, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual recognition and semantic understanding. Nevertheless, their ability to perform precise compositional spatial reasoning remains largely unexplored. Existing benchmarks often involve relatively simple tasks and rely on semantic approximations or coarse relative positioning, while their evaluation metrics are typically limited and lack rigorous mathematical formulations. To bridge this gap, we introduce TangramPuzzle, a geometry-grounded benchmark designed to evaluate compositional spatial reasoning through the lens of the classic Tangram game. We propose the Tangram Construction Expression (TCE), a symbolic geometric framework that grounds tangram assemblies in exact, machine-verifiable coordinate specifications, to mitigate the ambiguity of visual approximation. We design two complementary tasks: Outline Prediction, which demands inferring global shapes from local components, and End-to-End Code Generation, which requires solving inverse geometric assembly problems. We conduct extensive evaluation experiments on advanced open-source and proprietary models, revealing an interesting insight: MLLMs tend to prioritize matching the target silhouette while neglecting geometric constraints, leading to distortions or deformations of the pieces.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Jun 11, 2025Recent improvements in large language models (LLMs) have led many researchers to focus on building fully autonomous AI agents. This position paper questions whether this approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of human. We suggest a different approach: LLM-based Human-Agent Systems (LLM-HAS), where AI works with humans rather than replacing them. By keeping human involved to provide guidance, answer questions, and maintain control, these systems can be more trustworthy and adaptable. Looking at examples from healthcare, finance, and software development, we show how human-AI teamwork can handle complex tasks better than AI working alone. We also discuss the challenges of building these collaborative systems and offer practical solutions. This paper argues that progress in AI should not be measured by how independent systems become, but by how well they can work with humans. The most promising future for AI is not in systems that take over human roles, but in those that enhance human capabilities through meaningful partnership.
A Survey on Large Language Model based Human-Agent Systems
May 01, 2025Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-LLM-Based-Human-Agent-System-Papers.
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025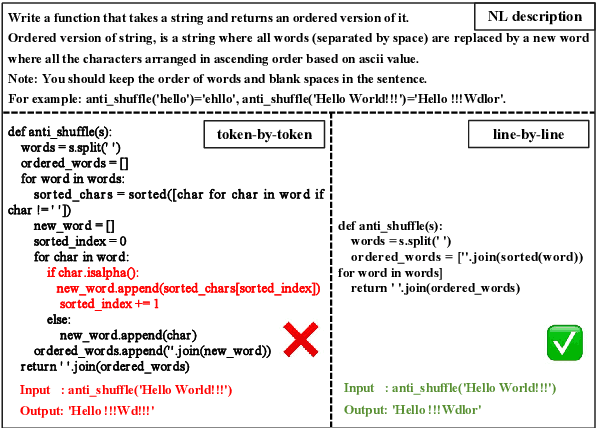
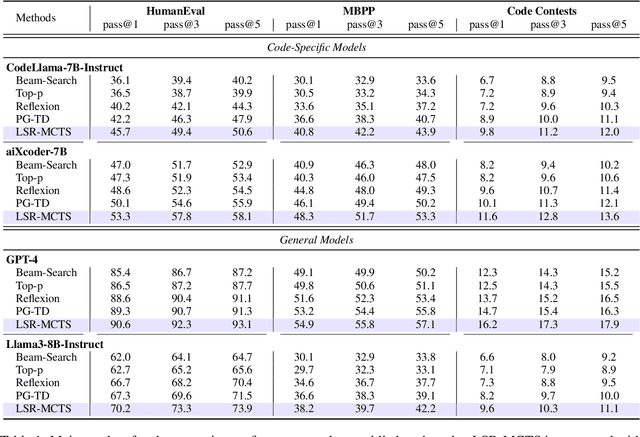
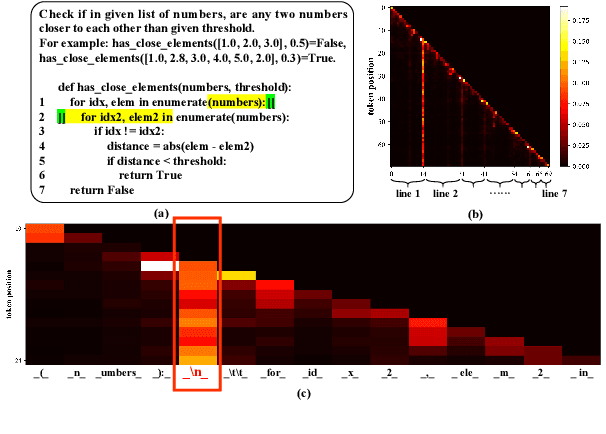
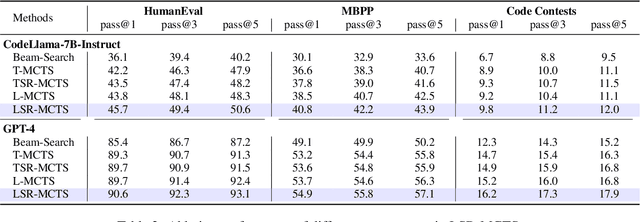
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
RAISE: Reinforenced Adaptive Instruction Selection For Large Language Models
Apr 09, 2025In the instruction fine-tuning of large language models (LLMs), it has become a consensus that a few high-quality instructions are superior to a large number of low-quality instructions. At present, many instruction selection methods have been proposed, but most of these methods select instruction based on heuristic quality metrics, and only consider data selection before training. These designs lead to insufficient optimization of instruction fine-tuning, and fixed heuristic indicators are often difficult to optimize for specific tasks. So we designed a dynamic, task-objective-driven instruction selection framework RAISE(Reinforenced Adaptive Instruction SElection), which incorporates the entire instruction fine-tuning process into optimization, selecting instruction at each step based on the expected impact of instruction on model performance improvement. Our approach is well interpretable and has strong task-specific optimization capabilities. By modeling dynamic instruction selection as a sequential decision-making process, we use RL to train our selection strategy. Extensive experiments and result analysis prove the superiority of our method compared with other instruction selection methods. Notably, RAISE achieves superior performance by updating only 1\% of the training steps compared to full-data training, demonstrating its efficiency and effectiveness.