 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025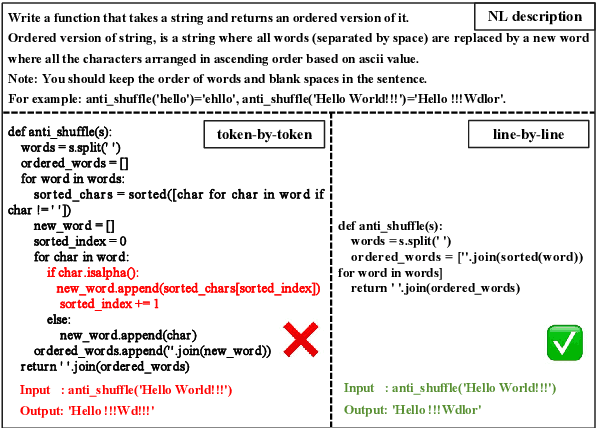
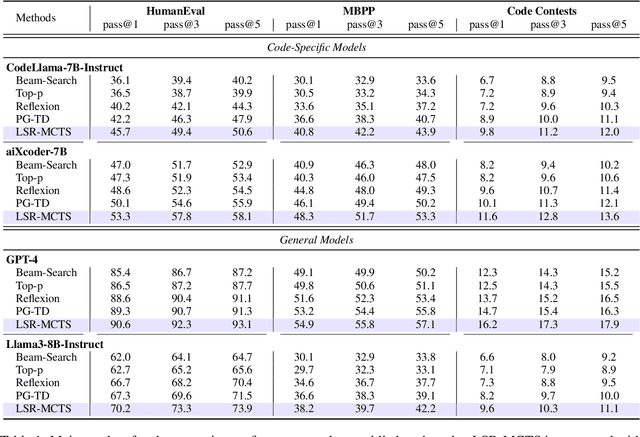
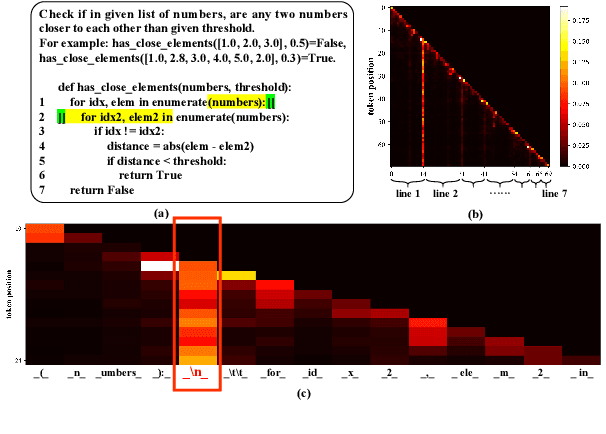
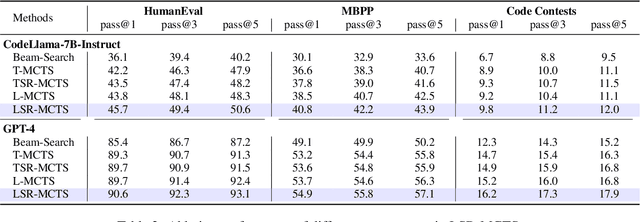
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL
Sep 21, 2024

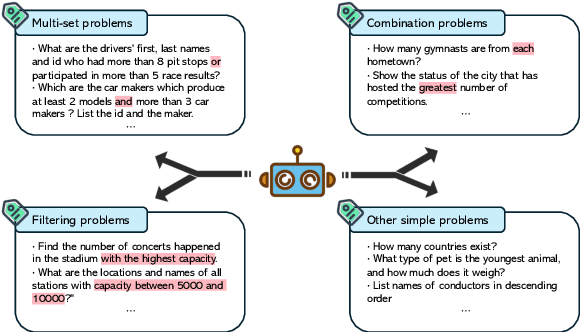
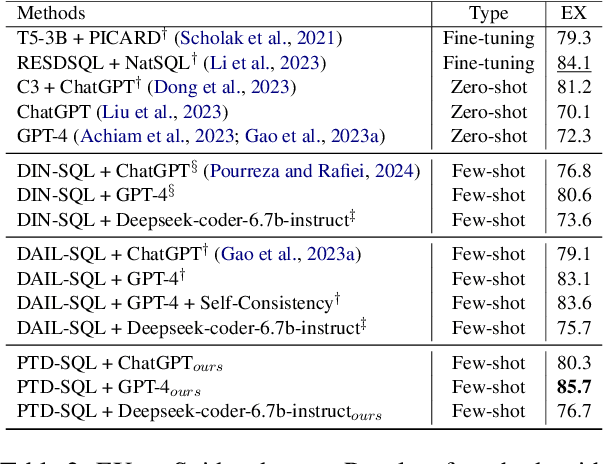
Large Language Models (LLMs) have emerged as powerful tools for Text-to-SQL tasks, exhibiting remarkable reasoning capabilities. Different from tasks such as math word problems and commonsense reasoning, SQL solutions have a relatively fixed pattern. This facilitates the investigation of whether LLMs can benefit from categorical thinking, mirroring how humans acquire knowledge through inductive reasoning based on comparable examples. In this study, we propose that employing query group partitioning allows LLMs to focus on learning the thought processes specific to a single problem type, consequently enhancing their reasoning abilities across diverse difficulty levels and problem categories. Our experiments reveal that multiple advanced LLMs, when equipped with PTD-SQL, can either surpass or match previous state-of-the-art (SOTA) methods on the Spider and BIRD datasets. Intriguingly, models with varying initial performances have exhibited significant improvements, mainly at the boundary of their capabilities after targeted drilling, suggesting a parallel with human progress. Code is available at https://github.com/lrlbbzl/PTD-SQL.
Making Large Language Models Better Reasoners with Alignment
Sep 05, 2023Reasoning is a cognitive process of using evidence to reach a sound conclusion. The reasoning capability is essential for large language models (LLMs) to serve as the brain of the artificial general intelligence agent. Recent studies reveal that fine-tuning LLMs on data with the chain of thought (COT) reasoning process can significantly enhance their reasoning capabilities. However, we find that the fine-tuned LLMs suffer from an \textit{Assessment Misalignment} problem, i.e., they frequently assign higher scores to subpar COTs, leading to potential limitations in their reasoning abilities. To address this problem, we introduce an \textit{Alignment Fine-Tuning (AFT)} paradigm, which involves three steps: 1) fine-tuning LLMs with COT training data; 2) generating multiple COT responses for each question, and categorizing them into positive and negative ones based on whether they achieve the correct answer; 3) calibrating the scores of positive and negative responses given by LLMs with a novel constraint alignment loss. Specifically, the constraint alignment loss has two objectives: a) Alignment, which guarantees that positive scores surpass negative scores to encourage answers with high-quality COTs; b) Constraint, which keeps the negative scores confined to a reasonable range to prevent the model degradation. Beyond just the binary positive and negative feedback, the constraint alignment loss can be seamlessly adapted to the ranking situations when ranking feedback is accessible. Furthermore, we also delve deeply into recent ranking-based alignment methods, such as DPO, RRHF, and PRO, and discover that the constraint, which has been overlooked by these approaches, is also crucial for their performance. Extensive experiments on four reasoning benchmarks with both binary and ranking feedback demonstrate the effectiveness of AFT.
Soft Language Clustering for Multilingual Model Pre-training
Jun 13, 2023
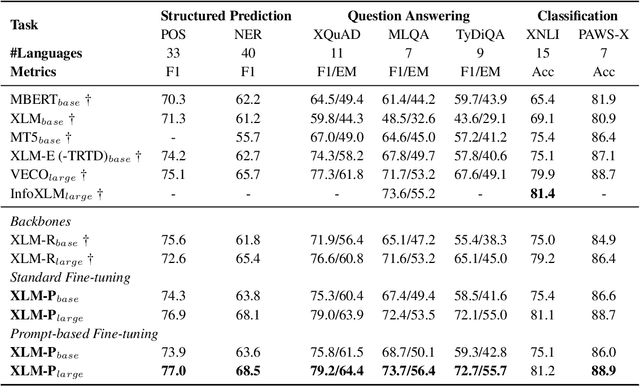
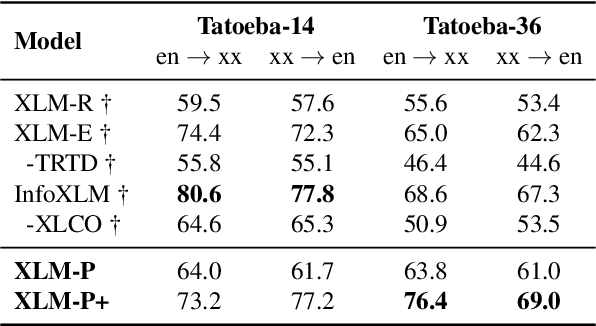
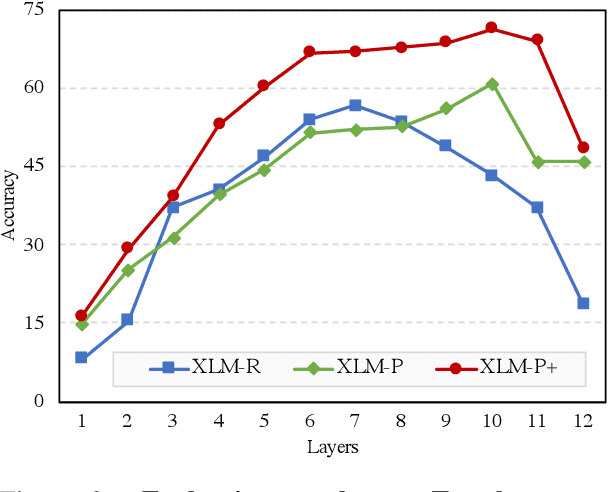
Multilingual pre-trained language models have demonstrated impressive (zero-shot) cross-lingual transfer abilities, however, their performance is hindered when the target language has distant typology from source languages or when pre-training data is limited in size. In this paper, we propose XLM-P, which contextually retrieves prompts as flexible guidance for encoding instances conditionally. Our XLM-P enables (1) lightweight modeling of language-invariant and language-specific knowledge across languages, and (2) easy integration with other multilingual pre-training methods. On the tasks of XTREME including text classification, sequence labeling, question answering, and sentence retrieval, both base- and large-size language models pre-trained with our proposed method exhibit consistent performance improvement. Furthermore, it provides substantial advantages for low-resource languages in unsupervised sentence retrieval and for target languages that differ greatly from the source language in cross-lingual transfer.
Rhythm-controllable Attention with High Robustness for Long Sentence Speech Synthesis
Jun 05, 2023



Regressive Text-to-Speech (TTS) system utilizes attention mechanism to generate alignment between text and acoustic feature sequence. Alignment determines synthesis robustness (e.g, the occurence of skipping, repeating, and collapse) and rhythm via duration control. However, current attention algorithms used in speech synthesis cannot control rhythm using external duration information to generate natural speech while ensuring robustness. In this study, we propose Rhythm-controllable Attention (RC-Attention) based on Tracotron2, which improves robustness and naturalness simultaneously. Proposed attention adopts a trainable scalar learned from four kinds of information to achieve rhythm control, which makes rhythm control more robust and natural, even when synthesized sentences are extremely longer than training corpus. We use word errors counting and AB preference test to measure robustness of proposed method and naturalness of synthesized speech, respectively. Results shows that RC-Attention has the lowest word error rate of nearly 0.6%, compared with 11.8% for baseline system. Moreover, nearly 60% subjects prefer to the speech synthesized with RC-Attention to that with Forward Attention, because the former has more natural rhythm.
Large Language Models are not Fair Evaluators
May 29, 2023



We uncover a systematic bias in the evaluation paradigm of adopting large language models~(LLMs), e.g., GPT-4, as a referee to score the quality of responses generated by candidate models. We find that the quality ranking of candidate responses can be easily hacked by simply altering their order of appearance in the context. This manipulation allows us to skew the evaluation result, making one model appear considerably superior to the other, e.g., vicuna could beat ChatGPT on 66 over 80 tested queries. To address this issue, we propose two simple yet effective calibration strategies: 1) Multiple Evidence Calibration, which requires the evaluator model to generate multiple detailed pieces of evidence before assigning ratings; 2) Balanced Position Calibration, which aggregates results across various orders to determine the final score. Extensive experiments demonstrate that our approach successfully mitigates evaluation bias, resulting in closer alignment with human judgments. To facilitate future research on more robust large language model comparison, we integrate the techniques in the paper into an easy-to-use toolkit \emph{FairEval}, along with the human annotations.\footnote{\url{https://github.com/i-Eval/FairEval}}
Denoising Bottleneck with Mutual Information Maximization for Video Multimodal Fusion
May 25, 2023



Video multimodal fusion aims to integrate multimodal signals in videos, such as visual, audio and text, to make a complementary prediction with multiple modalities contents. However, unlike other image-text multimodal tasks, video has longer multimodal sequences with more redundancy and noise in both visual and audio modalities. Prior denoising methods like forget gate are coarse in the granularity of noise filtering. They often suppress the redundant and noisy information at the risk of losing critical information. Therefore, we propose a denoising bottleneck fusion (DBF) model for fine-grained video multimodal fusion. On the one hand, we employ a bottleneck mechanism to filter out noise and redundancy with a restrained receptive field. On the other hand, we use a mutual information maximization module to regulate the filter-out module to preserve key information within different modalities. Our DBF model achieves significant improvement over current state-of-the-art baselines on multiple benchmarks covering multimodal sentiment analysis and multimodal summarization tasks. It proves that our model can effectively capture salient features from noisy and redundant video, audio, and text inputs. The code for this paper is publicly available at https://github.com/WSXRHFG/DBF.
Bi-Drop: Generalizable Fine-tuning for Pre-trained Language Models via Adaptive Subnetwork Optimization
May 24, 2023



Pretrained language models have achieved remarkable success in a variety of natural language understanding tasks. Nevertheless, finetuning large pretrained models on downstream tasks is susceptible to overfitting if the training set is limited, which will lead to diminished performance. In this work, we propose a dynamic fine-tuning strategy for pretrained language models called Bi-Drop. It utilizes the gradient information of various sub-models generated by dropout to update the model parameters selectively. Experiments on the GLUE benchmark show that Bi-Drop outperforms previous fine-tuning methods by a considerable margin, and exhibits consistent superiority over vanilla fine-tuning across various pretrained models. Furthermore, empirical results indicate that Bi-Drop yields substantial improvements in the multiple task or domain transfer, data imbalance, and low-resource scenarios, demonstrating superb generalization ability and robustness.
DialogVCS: Robust Natural Language Understanding in Dialogue System Upgrade
May 24, 2023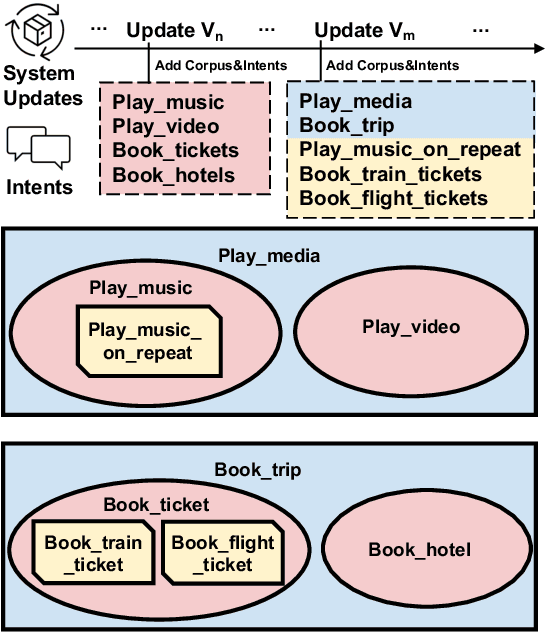


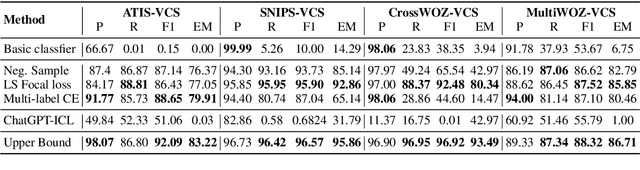
In the constant updates of the product dialogue systems, we need to retrain the natural language understanding (NLU) model as new data from the real users would be merged into the existent data accumulated in the last updates. Within the newly added data, new intents would emerge and might have semantic entanglement with the existing intents, e.g. new intents that are semantically too specific or generic are actually subset or superset of some existing intents in the semantic space, thus impairing the robustness of the NLU model. As the first attempt to solve this problem, we setup a new benchmark consisting of 4 Dialogue Version Control dataSets (DialogVCS). We formulate the intent detection with imperfect data in the system update as a multi-label classification task with positive but unlabeled intents, which asks the models to recognize all the proper intents, including the ones with semantic entanglement, in the inference. We also propose comprehensive baseline models and conduct in-depth analyses for the benchmark, showing that the semantically entangled intents can be effectively recognized with an automatic workflow.
Enhancing Continual Relation Extraction via Classifier Decomposition
May 08, 2023Continual relation extraction (CRE) models aim at handling emerging new relations while avoiding catastrophically forgetting old ones in the streaming data. Though improvements have been shown by previous CRE studies, most of them only adopt a vanilla strategy when models first learn representations of new relations. In this work, we point out that there exist two typical biases after training of this vanilla strategy: classifier bias and representation bias, which causes the previous knowledge that the model learned to be shaded. To alleviate those biases, we propose a simple yet effective classifier decomposition framework that splits the last FFN layer into separated previous and current classifiers, so as to maintain previous knowledge and encourage the model to learn more robust representations at this training stage. Experimental results on two standard benchmarks show that our proposed framework consistently outperforms the state-of-the-art CRE models, which indicates that the importance of the first training stage to CRE models may be underestimated. Our code is available at https://github.com/hemingkx/CDec.