 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg-ReSearch: Segmentation with Interleaved Reasoning and External Search
Feb 04, 2026Segmentation based on language has been a popular topic in computer vision. While recent advances in multimodal large language models (MLLMs) have endowed segmentation systems with reasoning capabilities, these efforts remain confined by the frozen internal knowledge of MLLMs, which limits their potential for real-world scenarios that involve up-to-date information or domain-specific concepts. In this work, we propose \textbf{Seg-ReSearch}, a novel segmentation paradigm that overcomes the knowledge bottleneck of existing approaches. By enabling interleaved reasoning and external search, Seg-ReSearch empowers segmentation systems to handle dynamic, open-world queries that extend beyond the frozen knowledge of MLLMs. To effectively train this capability, we introduce a hierarchical reward design that harmonizes initial guidance with progressive incentives, mitigating the dilemma between sparse outcome signals and rigid step-wise supervision. For evaluation, we construct OK-VOS, a challenging benchmark that explicitly requires outside knowledge for video object segmentation. Experiments on OK-VOS and two existing reasoning segmentation benchmarks demonstrate that our Seg-ReSearch improves state-of-the-art approaches by a substantial margin. Code and data will be released at https://github.com/iSEE-Laboratory/Seg-ReSearch.
URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
Jan 08, 2025



Chain-of-thought (CoT) reasoning has been widely applied in the mathematical reasoning of Large Language Models (LLMs). Recently, the introduction of derivative process supervision on CoT trajectories has sparked discussions on enhancing scaling capabilities during test time, thereby boosting the potential of these models. However, in multimodal mathematical reasoning, the scarcity of high-quality CoT training data has hindered existing models from achieving high-precision CoT reasoning and has limited the realization of reasoning potential during test time. In this work, we propose a three-module synthesis strategy that integrates CoT distillation, trajectory-format rewriting, and format unification. It results in a high-quality CoT reasoning instruction fine-tuning dataset in multimodal mathematics, MMathCoT-1M. We comprehensively validate the state-of-the-art (SOTA) performance of the trained URSA-7B model on multiple multimodal mathematical benchmarks. For test-time scaling, we introduce a data synthesis strategy that automatically generates process annotation datasets, known as DualMath-1.1M, focusing on both interpretation and logic. By further training URSA-7B on DualMath-1.1M, we transition from CoT reasoning capabilities to robust supervision abilities. The trained URSA-RM-7B acts as a verifier, effectively enhancing the performance of URSA-7B at test time. URSA-RM-7B also demonstrates excellent out-of-distribution (OOD) verifying capabilities, showcasing its generalization. Model weights, training data and code will be open-sourced.
Beamforming Design for Wideband Near-Field Communications With Reconfigurable Refractive Surfaces
Jan 02, 2025



To meet the growing demand for high data rates, cellular systems are expected to evolve towards higher carrier frequencies and larger antenna arrays, but conventional phased arrays face challenges in supporting such a prospection due to their excessive power consumption induced by numerous phase shifters required. Reconfigurable Refractive Surface (RRS) is an energy efficient solution to address this issue without relying on phase shifters. However, the increased radiation aperture size extends the range of the Fresnel region, leading the users to lie in the near-field zone. Moreover, given the wideband communications in higher frequency bands, we cannot ignore the frequency selectivity of the RRS. These two effects collectively exacerbate the beam-split issue, where different frequency components fail to converge on the user simultaneously, and finally result in a degradation of the data rate. In this paper, we investigate an RRS-based wideband near-field multi-user communication system. Unlike most existing studies on wideband communications, which consider the beam-split effect only with the near-field condition, we study the beam-split effect under the influence of both the near-field condition and the frequency selectivity of the RRS. To mitigate the beam-split effect, we propose a Delayed-RRS structure, based on which a beamforming scheme is proposed to optimize the user's data rate. Through theoretical analysis and simulation results, we analyze the influence of the RRS's frequency selectivity, demonstrate the effectiveness of the proposed beamforming scheme, and reveal the importance of jointly considering the near-field condition and the frequency selectivity of RRS.
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability
Dec 02, 2024



Large Language Models (LLMs) have exhibited remarkable performance on reasoning tasks. They utilize autoregressive token generation to construct reasoning trajectories, enabling the development of a coherent chain of thought. In this work, we explore the impact of individual tokens on the final outcomes of reasoning tasks. We identify the existence of ``critical tokens'' that lead to incorrect reasoning trajectories in LLMs. Specifically, we find that LLMs tend to produce positive outcomes when forced to decode other tokens instead of critical tokens. Motivated by this observation, we propose a novel approach - cDPO - designed to automatically recognize and conduct token-level rewards for the critical tokens during the alignment process. Specifically, we develop a contrastive estimation approach to automatically identify critical tokens. It is achieved by comparing the generation likelihood of positive and negative models. To achieve this, we separately fine-tune the positive and negative models on various reasoning trajectories, consequently, they are capable of identifying identify critical tokens within incorrect trajectories that contribute to erroneous outcomes. Moreover, to further align the model with the critical token information during the alignment process, we extend the conventional DPO algorithms to token-level DPO and utilize the differential likelihood from the aforementioned positive and negative model as important weight for token-level DPO learning.Experimental results on GSM8K and MATH500 benchmarks with two-widely used models Llama-3 (8B and 70B) and deepseek-math (7B) demonstrate the effectiveness of the propsoed approach cDPO.
PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL
Sep 21, 2024

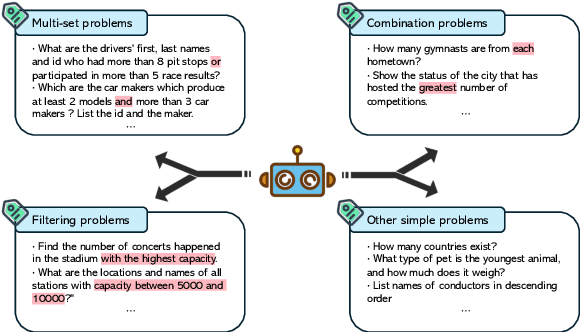
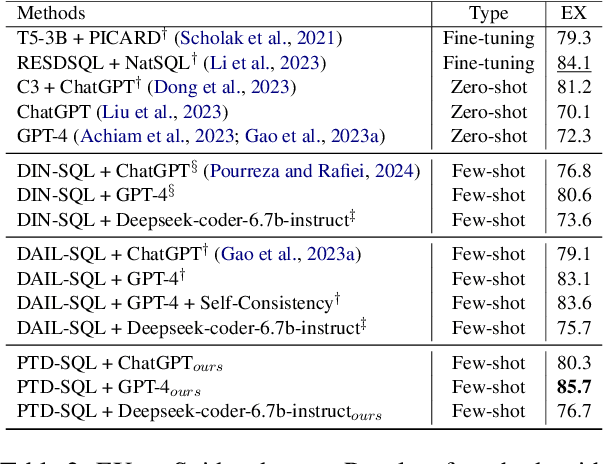
Large Language Models (LLMs) have emerged as powerful tools for Text-to-SQL tasks, exhibiting remarkable reasoning capabilities. Different from tasks such as math word problems and commonsense reasoning, SQL solutions have a relatively fixed pattern. This facilitates the investigation of whether LLMs can benefit from categorical thinking, mirroring how humans acquire knowledge through inductive reasoning based on comparable examples. In this study, we propose that employing query group partitioning allows LLMs to focus on learning the thought processes specific to a single problem type, consequently enhancing their reasoning abilities across diverse difficulty levels and problem categories. Our experiments reveal that multiple advanced LLMs, when equipped with PTD-SQL, can either surpass or match previous state-of-the-art (SOTA) methods on the Spider and BIRD datasets. Intriguingly, models with varying initial performances have exhibited significant improvements, mainly at the boundary of their capabilities after targeted drilling, suggesting a parallel with human progress. Code is available at https://github.com/lrlbbzl/PTD-SQL.
FFAA: Multimodal Large Language Model based Explainable Open-World Face Forgery Analysis Assistant
Aug 19, 2024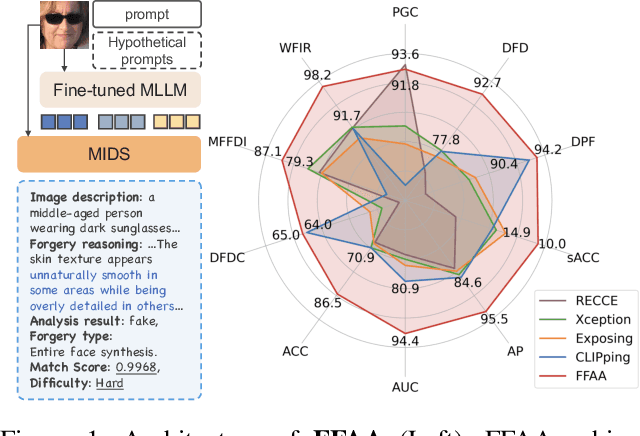
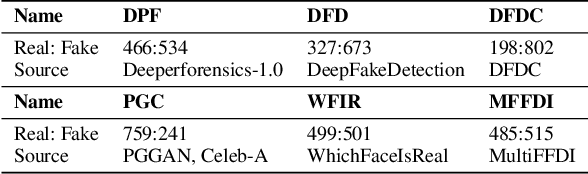
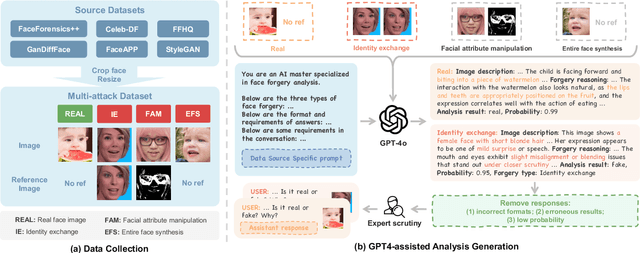
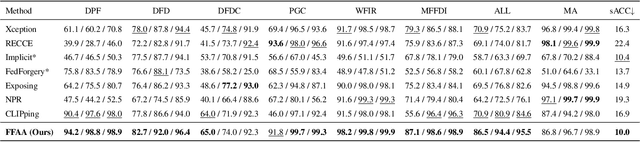
The rapid advancement of deepfake technologies has sparked widespread public concern, particularly as face forgery poses a serious threat to public information security. However, the unknown and diverse forgery techniques, varied facial features and complex environmental factors pose significant challenges for face forgery analysis. Existing datasets lack descriptions of these aspects, making it difficult for models to distinguish between real and forged faces using only visual information amid various confounding factors. In addition, existing methods do not yield user-friendly and explainable results, complicating the understanding of the model's decision-making process. To address these challenges, we introduce a novel Open-World Face Forgery Analysis VQA (OW-FFA-VQA) task and the corresponding benchmark. To tackle this task, we first establish a dataset featuring a diverse collection of real and forged face images with essential descriptions and reliable forgery reasoning. Base on this dataset, we introduce FFAA: Face Forgery Analysis Assistant, consisting of a fine-tuned Multimodal Large Language Model (MLLM) and Multi-answer Intelligent Decision System (MIDS). By integrating hypothetical prompts with MIDS, the impact of fuzzy classification boundaries is effectively mitigated, enhancing the model's robustness. Extensive experiments demonstrate that our method not only provides user-friendly explainable results but also significantly boosts accuracy and robustness compared to previous methods.
CriticBench: Benchmarking LLMs for Critique-Correct Reasoning
Mar 08, 2024



The ability of Large Language Models (LLMs) to critique and refine their reasoning is crucial for their application in evaluation, feedback provision, and self-improvement. This paper introduces CriticBench, a comprehensive benchmark designed to assess LLMs' abilities to critique and rectify their reasoning across a variety of tasks. CriticBench encompasses five reasoning domains: mathematical, commonsense, symbolic, coding, and algorithmic. It compiles 15 datasets and incorporates responses from three LLM families. Utilizing CriticBench, we evaluate and dissect the performance of 17 LLMs in generation, critique, and correction reasoning, i.e., GQC reasoning. Our findings reveal: (1) a linear relationship in GQC capabilities, with critique-focused training markedly enhancing performance; (2) a task-dependent variation in correction effectiveness, with logic-oriented tasks being more amenable to correction; (3) GQC knowledge inconsistencies that decrease as model size increases; and (4) an intriguing inter-model critiquing dynamic, where stronger models are better at critiquing weaker ones, while weaker models can surprisingly surpass stronger ones in their self-critique. We hope these insights into the nuanced critique-correct reasoning of LLMs will foster further research in LLM critique and self-improvement.
Chain of History: Learning and Forecasting with LLMs for Temporal Knowledge Graph Completion
Jan 11, 2024



Temporal Knowledge Graph Completion (TKGC) is a challenging task of predicting missing event links at future timestamps by leveraging established temporal structural knowledge. Given the formidable generative capabilities inherent in LLMs (LLMs), this paper proposes a novel approach to conceptualize temporal link prediction as an event generation task within the context of a historical event chain. We employ efficient fine-tuning methods to make LLMs adapt to specific graph textual information and patterns discovered in temporal timelines. Furthermore, we introduce structure-based historical data augmentation and the integration of reverse knowledge to emphasize LLMs' awareness of structural information, thereby enhancing their reasoning capabilities. We conduct thorough experiments on multiple widely used datasets and find that our fine-tuned model outperforms existing embedding-based models on multiple metrics, achieving SOTA results. We also carry out sufficient ablation experiments to explore the key influencing factors when LLMs perform structured temporal knowledge inference tasks.