 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse Decisions to Dense Reasoning: A Multi-attribute Trajectory Paradigm for Multimodal Moderation
Jan 28, 2026Safety moderation is pivotal for identifying harmful content. Despite the success of textual safety moderation, its multimodal counterparts remain hindered by a dual sparsity of data and supervision. Conventional reliance on binary labels lead to shortcut learning, which obscures the intrinsic classification boundaries necessary for effective multimodal discrimination. Hence, we propose a novel learning paradigm (UniMod) that transitions from sparse decision-making to dense reasoning traces. By constructing structured trajectories encompassing evidence grounding, modality assessment, risk mapping, policy decision, and response generation, we reformulate monolithic decision tasks into a multi-dimensional boundary learning process. This approach forces the model to ground its decision in explicit safety semantics, preventing the model from converging on superficial shortcuts. To facilitate this paradigm, we develop a multi-head scalar reward model (UniRM). UniRM provides multi-dimensional supervision by assigning attribute-level scores to the response generation stage. Furthermore, we introduce specialized optimization strategies to decouple task-specific parameters and rebalance training dynamics, effectively resolving interference between diverse objectives in multi-task learning. Empirical results show UniMod achieves competitive textual moderation performance and sets a new multimodal benchmark using less than 40\% of the training data used by leading baselines. Ablations further validate our multi-attribute trajectory reasoning, offering an effective and efficient framework for multimodal moderation. Supplementary materials are available at \href{https://trustworthylab.github.io/UniMod/}{project website}.
OpenRT: An Open-Source Red Teaming Framework for Multimodal LLMs
Jan 04, 2026The rapid integration of Multimodal Large Language Models (MLLMs) into critical applications is increasingly hindered by persistent safety vulnerabilities. However, existing red-teaming benchmarks are often fragmented, limited to single-turn text interactions, and lack the scalability required for systematic evaluation. To address this, we introduce OpenRT, a unified, modular, and high-throughput red-teaming framework designed for comprehensive MLLM safety evaluation. At its core, OpenRT architects a paradigm shift in automated red-teaming by introducing an adversarial kernel that enables modular separation across five critical dimensions: model integration, dataset management, attack strategies, judging methods, and evaluation metrics. By standardizing attack interfaces, it decouples adversarial logic from a high-throughput asynchronous runtime, enabling systematic scaling across diverse models. Our framework integrates 37 diverse attack methodologies, spanning white-box gradients, multi-modal perturbations, and sophisticated multi-agent evolutionary strategies. Through an extensive empirical study on 20 advanced models (including GPT-5.2, Claude 4.5, and Gemini 3 Pro), we expose critical safety gaps: even frontier models fail to generalize across attack paradigms, with leading models exhibiting average Attack Success Rates as high as 49.14%. Notably, our findings reveal that reasoning models do not inherently possess superior robustness against complex, multi-turn jailbreaks. By open-sourcing OpenRT, we provide a sustainable, extensible, and continuously maintained infrastructure that accelerates the development and standardization of AI safety.
A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports
Oct 02, 2025Artificial intelligence is undergoing the paradigm shift from closed language models to interconnected agent systems capable of external perception and information integration. As a representative embodiment, Deep Research Agents (DRAs) systematically exhibit the capabilities for task decomposition, cross-source retrieval, multi-stage reasoning, and structured output, which markedly enhance performance on complex and open-ended tasks. However, existing benchmarks remain deficient in evaluation dimensions, response formatting, and scoring mechanisms, limiting their capacity to assess such systems effectively. This paper introduces a rigorous benchmark and a multidimensional evaluation framework tailored to DRAs and report-style responses. The benchmark comprises 214 expert-curated challenging queries distributed across 10 broad thematic domains, each accompanied by manually constructed reference bundles to support composite evaluation. The framework enables comprehensive evaluation of long-form reports generated by DRAs, incorporating integrated scoring metrics for semantic quality, topical focus, and retrieval trustworthiness. Extensive experimentation confirms the superior performance of mainstream DRAs over web-search-tool-augmented reasoning models, yet reveals considerable scope for further improvement. This study provides a robust foundation for capability assessment, architectural refinement, and paradigm advancement in DRA systems.
S2J: Bridging the Gap Between Solving and Judging Ability in Generative Reward Models
Sep 26, 2025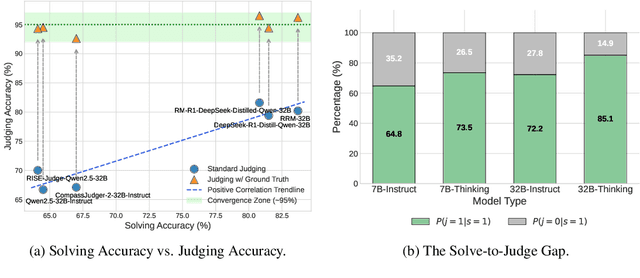
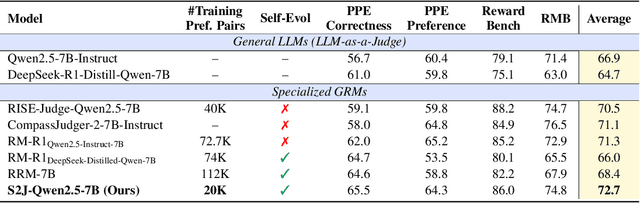
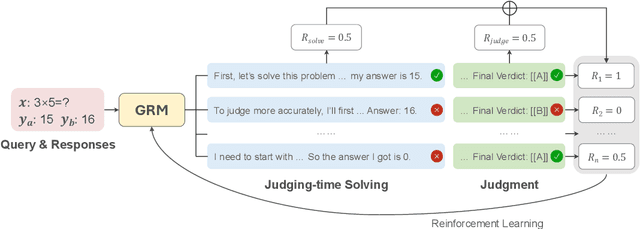
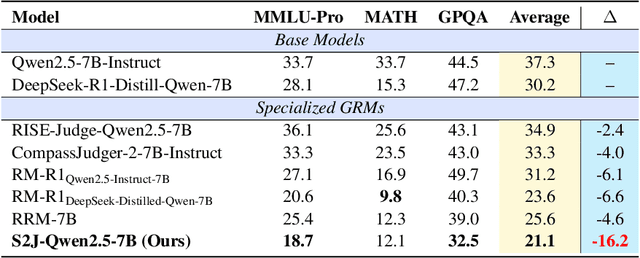
With the rapid development of large language models (LLMs), generative reward models (GRMs) have been widely adopted for reward modeling and evaluation. Previous studies have primarily focused on training specialized GRMs by optimizing them on preference datasets with the judgment correctness as supervision. While it's widely accepted that GRMs with stronger problem-solving capabilities typically exhibit superior judgment abilities, we first identify a significant solve-to-judge gap when examining individual queries. Specifically, the solve-to-judge gap refers to the phenomenon where GRMs struggle to make correct judgments on some queries (14%-37%), despite being fully capable of solving them. In this paper, we propose the Solve-to-Judge (S2J) approach to address this problem. Specifically, S2J simultaneously leverages both the solving and judging capabilities on a single GRM's output for supervision, explicitly linking the GRM's problem-solving and evaluation abilities during model optimization, thereby narrowing the gap. Our comprehensive experiments demonstrate that S2J effectively reduces the solve-to-judge gap by 16.2%, thereby enhancing the model's judgment performance by 5.8%. Notably, S2J achieves state-of-the-art (SOTA) performance among GRMs built on the same base model while utilizing a significantly smaller training dataset. Moreover, S2J accomplishes this through self-evolution without relying on more powerful external models for distillation.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Invisible Entropy: Towards Safe and Efficient Low-Entropy LLM Watermarking
May 20, 2025Logit-based LLM watermarking traces and verifies AI-generated content by maintaining green and red token lists and increasing the likelihood of green tokens during generation. However, it fails in low-entropy scenarios, where predictable outputs make green token selection difficult without disrupting natural text flow. Existing approaches address this by assuming access to the original LLM to calculate entropy and selectively watermark high-entropy tokens. However, these methods face two major challenges: (1) high computational costs and detection delays due to reliance on the original LLM, and (2) potential risks of model leakage. To address these limitations, we propose Invisible Entropy (IE), a watermarking paradigm designed to enhance both safety and efficiency. Instead of relying on the original LLM, IE introduces a lightweight feature extractor and an entropy tagger to predict whether the entropy of the next token is high or low. Furthermore, based on theoretical analysis, we develop a threshold navigator that adaptively sets entropy thresholds. It identifies a threshold where the watermark ratio decreases as the green token count increases, enhancing the naturalness of the watermarked text and improving detection robustness. Experiments on HumanEval and MBPP datasets demonstrate that IE reduces parameter size by 99\% while achieving performance on par with state-of-the-art methods. Our work introduces a safe and efficient paradigm for low-entropy watermarking. https://github.com/Carol-gutianle/IE https://huggingface.co/datasets/Carol0110/IE-Tagger
From Rankings to Insights: Evaluation Should Shift Focus from Leaderboard to Feedback
May 10, 2025Automatic evaluation benchmarks such as MT-Bench, Arena-Hard, and Auto-Arena are seeing growing adoption for the evaluation of Large Language Models (LLMs). Existing research has primarily focused on approximating human-based model rankings using limited data and LLM-as-a-Judge. However, the fundamental premise of these studies, which attempts to replicate human rankings, is flawed. Specifically, these benchmarks typically offer only overall scores, limiting their utility to leaderboard rankings, rather than providing feedback that can guide model optimization and support model profiling. Therefore, we advocate for an evaluation paradigm shift from approximating human-based model rankings to providing feedback with analytical value. To this end, we introduce Feedbacker, an evaluation framework that provides comprehensive and fine-grained results, thereby enabling thorough identification of a model's specific strengths and weaknesses. Such feedback not only supports the targeted optimization of the model but also enhances the understanding of its behavior. Feedbacker comprises three key components: an extensible tree-based query taxonomy builder, an automated query synthesis scheme, and a suite of visualization and analysis tools. Furthermore, we propose a novel LLM-as-a-Judge method: PC2 (Pre-Comparison-derived Criteria) pointwise evaluation. This method derives evaluation criteria by pre-comparing the differences between several auxiliary responses, achieving the accuracy of pairwise evaluation while maintaining the time complexity of pointwise evaluation. Finally, leveraging the evaluation results of 17 mainstream LLMs, we demonstrate the usage of Feedbacker and highlight its effectiveness and potential. Our homepage project is available at https://liudan193.github.io/Feedbacker.
Word Form Matters: LLMs' Semantic Reconstruction under Typoglycemia
Mar 03, 2025Human readers can efficiently comprehend scrambled words, a phenomenon known as Typoglycemia, primarily by relying on word form; if word form alone is insufficient, they further utilize contextual cues for interpretation. While advanced large language models (LLMs) exhibit similar abilities, the underlying mechanisms remain unclear. To investigate this, we conduct controlled experiments to analyze the roles of word form and contextual information in semantic reconstruction and examine LLM attention patterns. Specifically, we first propose SemRecScore, a reliable metric to quantify the degree of semantic reconstruction, and validate its effectiveness. Using this metric, we study how word form and contextual information influence LLMs' semantic reconstruction ability, identifying word form as the core factor in this process. Furthermore, we analyze how LLMs utilize word form and find that they rely on specialized attention heads to extract and process word form information, with this mechanism remaining stable across varying levels of word scrambling. This distinction between LLMs' fixed attention patterns primarily focused on word form and human readers' adaptive strategy in balancing word form and contextual information provides insights into enhancing LLM performance by incorporating human-like, context-aware mechanisms.
Recent Advances in Large Langauge Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation
Feb 23, 2025Data contamination has received increasing attention in the era of large language models (LLMs) due to their reliance on vast Internet-derived training corpora. To mitigate the risk of potential data contamination, LLM benchmarking has undergone a transformation from static to dynamic benchmarking. In this work, we conduct an in-depth analysis of existing static to dynamic benchmarking methods aimed at reducing data contamination risks. We first examine methods that enhance static benchmarks and identify their inherent limitations. We then highlight a critical gap-the lack of standardized criteria for evaluating dynamic benchmarks. Based on this observation, we propose a series of optimal design principles for dynamic benchmarking and analyze the limitations of existing dynamic benchmarks. This survey provides a concise yet comprehensive overview of recent advancements in data contamination research, offering valuable insights and a clear guide for future research efforts. We maintain a GitHub repository to continuously collect both static and dynamic benchmarking methods for LLMs. The repository can be found at this link.
A Cognitive Writing Perspective for Constrained Long-Form Text Generation
Feb 19, 2025Like humans, Large Language Models (LLMs) struggle to generate high-quality long-form text that adheres to strict requirements in a single pass. This challenge is unsurprising, as successful human writing, according to the Cognitive Writing Theory, is a complex cognitive process involving iterative planning, translating, reviewing, and monitoring. Motivated by these cognitive principles, we aim to equip LLMs with human-like cognitive writing capabilities through CogWriter, a novel training-free framework that transforms LLM constrained long-form text generation into a systematic cognitive writing paradigm. Our framework consists of two key modules: (1) a Planning Agent that performs hierarchical planning to decompose the task, and (2) multiple Generation Agents that execute these plans in parallel. The system maintains quality via continuous monitoring and reviewing mechanisms, which evaluate outputs against specified requirements and trigger necessary revisions. CogWriter demonstrates exceptional performance on LongGenBench, a benchmark for complex constrained long-form text generation. Even when using Qwen-2.5-14B as its backbone, CogWriter surpasses GPT-4o by 22% in complex instruction completion accuracy while reliably generating texts exceeding 10,000 words. We hope this cognitive science-inspired approach provides a paradigm for LLM writing advancements: \href{https://github.com/KaiyangWan/CogWriter}{CogWriter}.