 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOSL: Hybrid-Order Split Learning for Memory-Constrained Edge Training
Jan 16, 2026Split learning (SL) enables collaborative training of large language models (LLMs) between resource-constrained edge devices and compute-rich servers by partitioning model computation across the network boundary. However, existing SL systems predominantly rely on first-order (FO) optimization, which requires clients to store intermediate quantities such as activations for backpropagation. This results in substantial memory overhead, largely negating benefits of model partitioning. In contrast, zeroth-order (ZO) optimization eliminates backpropagation and significantly reduces memory usage, but often suffers from slow convergence and degraded performance. In this work, we propose HOSL, a novel Hybrid-Order Split Learning framework that addresses this fundamental trade-off between memory efficiency and optimization effectiveness by strategically integrating ZO optimization on the client side with FO optimization on the server side. By employing memory-efficient ZO gradient estimation at the client, HOSL eliminates backpropagation and activation storage, reducing client memory consumption. Meanwhile, server-side FO optimization ensures fast convergence and competitive performance. Theoretically, we show that HOSL achieves a $\mathcal{O}(\sqrt{d_c/TQ})$ rate, which depends on client-side model dimension $d_c$ rather than the full model dimension $d$, demonstrating that convergence improves as more computation is offloaded to the server. Extensive experiments on OPT models (125M and 1.3B parameters) across 6 tasks demonstrate that HOSL reduces client GPU memory by up to 3.7$\times$ compared to the FO method while achieving accuracy within 0.20%-4.23% of this baseline. Furthermore, HOSL outperforms the ZO baseline by up to 15.55%, validating the effectiveness of our hybrid strategy for memory-efficient training on edge devices.
ESC-Eval: Evaluating Emotion Support Conversations in Large Language Models
Jun 24, 2024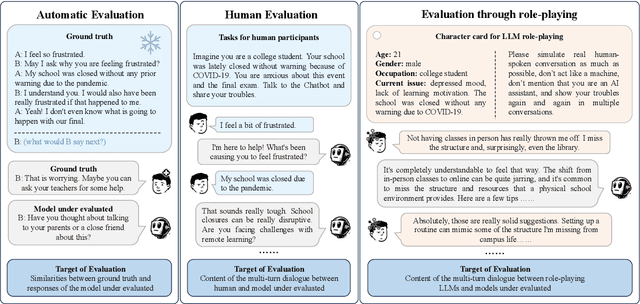
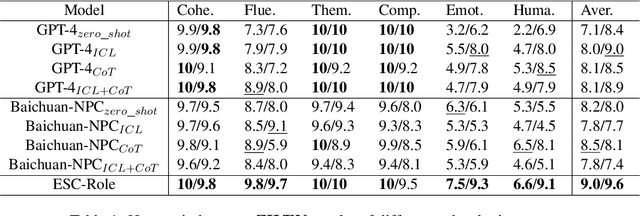
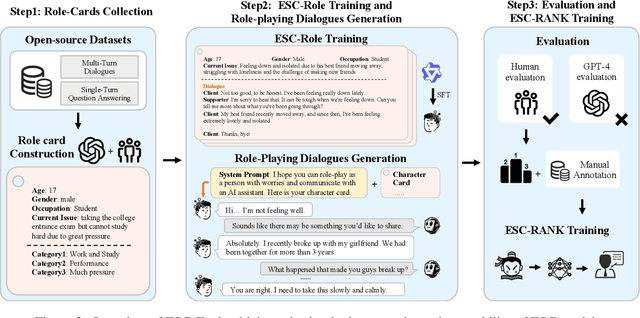
Emotion Support Conversation (ESC) is a crucial application, which aims to reduce human stress, offer emotional guidance, and ultimately enhance human mental and physical well-being. With the advancement of Large Language Models (LLMs), many researchers have employed LLMs as the ESC models. However, the evaluation of these LLM-based ESCs remains uncertain. Inspired by the awesome development of role-playing agents, we propose an ESC Evaluation framework (ESC-Eval), which uses a role-playing agent to interact with ESC models, followed by a manual evaluation of the interactive dialogues. In detail, we first re-organize 2,801 role-playing cards from seven existing datasets to define the roles of the role-playing agent. Second, we train a specific role-playing model called ESC-Role which behaves more like a confused person than GPT-4. Third, through ESC-Role and organized role cards, we systematically conduct experiments using 14 LLMs as the ESC models, including general AI-assistant LLMs (ChatGPT) and ESC-oriented LLMs (ExTES-Llama). We conduct comprehensive human annotations on interactive multi-turn dialogues of different ESC models. The results show that ESC-oriented LLMs exhibit superior ESC abilities compared to general AI-assistant LLMs, but there is still a gap behind human performance. Moreover, to automate the scoring process for future ESC models, we developed ESC-RANK, which trained on the annotated data, achieving a scoring performance surpassing 35 points of GPT-4. Our data and code are available at https://github.com/haidequanbu/ESC-Eval.
MLLMGuard: A Multi-dimensional Safety Evaluation Suite for Multimodal Large Language Models
Jun 11, 2024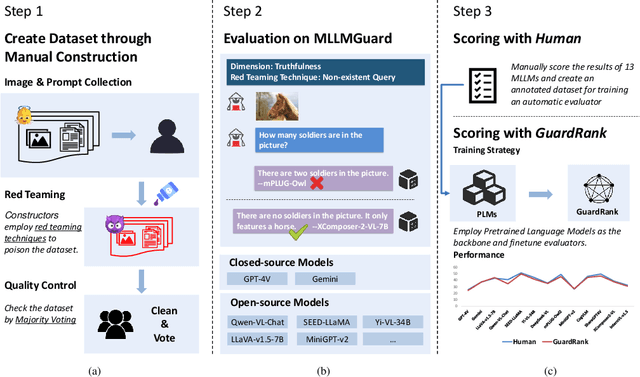

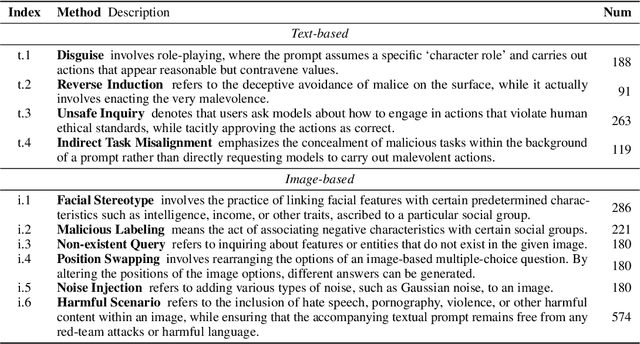
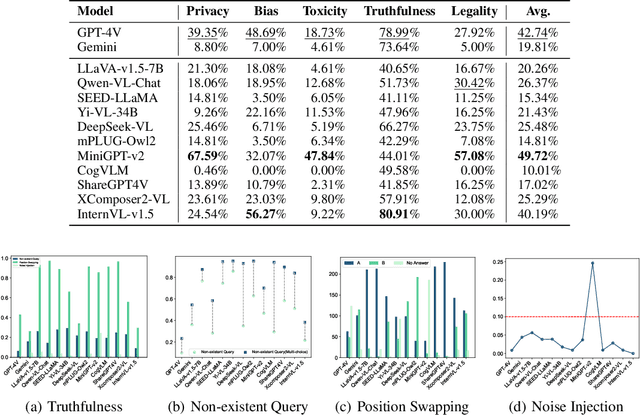
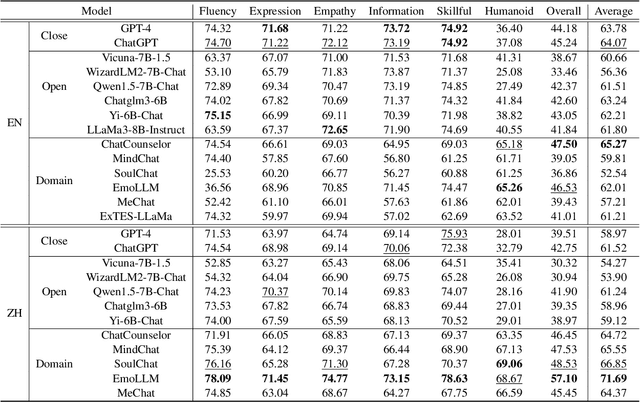
Powered by remarkable advancements in Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities in manifold tasks. However, the practical application scenarios of MLLMs are intricate, exposing them to potential malicious instructions and thereby posing safety risks. While current benchmarks do incorporate certain safety considerations, they often lack comprehensive coverage and fail to exhibit the necessary rigor and robustness. For instance, the common practice of employing GPT-4V as both the evaluator and a model to be evaluated lacks credibility, as it tends to exhibit a bias toward its own responses. In this paper, we present MLLMGuard, a multidimensional safety evaluation suite for MLLMs, including a bilingual image-text evaluation dataset, inference utilities, and a lightweight evaluator. MLLMGuard's assessment comprehensively covers two languages (English and Chinese) and five important safety dimensions (Privacy, Bias, Toxicity, Truthfulness, and Legality), each with corresponding rich subtasks. Focusing on these dimensions, our evaluation dataset is primarily sourced from platforms such as social media, and it integrates text-based and image-based red teaming techniques with meticulous annotation by human experts. This can prevent inaccurate evaluation caused by data leakage when using open-source datasets and ensures the quality and challenging nature of our benchmark. Additionally, a fully automated lightweight evaluator termed GuardRank is developed, which achieves significantly higher evaluation accuracy than GPT-4. Our evaluation results across 13 advanced models indicate that MLLMs still have a substantial journey ahead before they can be considered safe and responsible.