 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Features: Pixel-level Mapping for Generalized AI-Generated Image Detection
Dec 19, 2025



The rapid evolution of generative technologies necessitates reliable methods for detecting AI-generated images. A critical limitation of current detectors is their failure to generalize to images from unseen generative models, as they often overfit to source-specific semantic cues rather than learning universal generative artifacts. To overcome this, we introduce a simple yet remarkably effective pixel-level mapping pre-processing step to disrupt the pixel value distribution of images and break the fragile, non-essential semantic patterns that detectors commonly exploit as shortcuts. This forces the detector to focus on more fundamental and generalizable high-frequency traces inherent to the image generation process. Through comprehensive experiments on GAN and diffusion-based generators, we show that our approach significantly boosts the cross-generator performance of state-of-the-art detectors. Extensive analysis further verifies our hypothesis that the disruption of semantic cues is the key to generalization.
How to Use Graph Data in the Wild to Help Graph Anomaly Detection?
Jun 04, 2025In recent years, graph anomaly detection has found extensive applications in various domains such as social, financial, and communication networks. However, anomalies in graph-structured data present unique challenges, including label scarcity, ill-defined anomalies, and varying anomaly types, making supervised or semi-supervised methods unreliable. Researchers often adopt unsupervised approaches to address these challenges, assuming that anomalies deviate significantly from the normal data distribution. Yet, when the available data is insufficient, capturing the normal distribution accurately and comprehensively becomes difficult. To overcome this limitation, we propose to utilize external graph data (i.e., graph data in the wild) to help anomaly detection tasks. This naturally raises the question: How can we use external data to help graph anomaly detection tasks? To answer this question, we propose a framework called Wild-GAD. It is built upon a unified database, UniWildGraph, which comprises a large and diverse collection of graph data with broad domain coverage, ample data volume, and a unified feature space. Further, we develop selection criteria based on representativity and diversity to identify the most suitable external data for anomaly detection task. Extensive experiments on six real-world datasets demonstrate the effectiveness of Wild-GAD. Compared to the baseline methods, our framework has an average 18% AUCROC and 32% AUCPR improvement over the best-competing methods.
SlangDIT: Benchmarking LLMs in Interpretative Slang Translation
May 20, 2025The challenge of slang translation lies in capturing context-dependent semantic extensions, as slang terms often convey meanings beyond their literal interpretation. While slang detection, explanation, and translation have been studied as isolated tasks in the era of large language models (LLMs), their intrinsic interdependence remains underexplored. The main reason is lacking of a benchmark where the two tasks can be a prerequisite for the third one, which can facilitate idiomatic translation. In this paper, we introduce the interpretative slang translation task (named SlangDIT) consisting of three sub-tasks: slang detection, cross-lingual slang explanation, and slang translation within the current context, aiming to generate more accurate translation with the help of slang detection and slang explanation. To this end, we construct a SlangDIT dataset, containing over 25k English-Chinese sentence pairs. Each source sentence mentions at least one slang term and is labeled with corresponding cross-lingual slang explanation. Based on the benchmark, we propose a deep thinking model, named SlangOWL. It firstly identifies whether the sentence contains a slang, and then judges whether the slang is polysemous and analyze its possible meaning. Further, the SlangOWL provides the best explanation of the slang term targeting on the current context. Finally, according to the whole thought, the SlangOWL offers a suitable translation. Our experiments on LLMs (\emph{e.g.}, Qwen2.5 and LLama-3.1), show that our deep thinking approach indeed enhances the performance of LLMs where the proposed SLangOWL significantly surpasses the vanilla models and supervised fine-tuned models without thinking.
An Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025
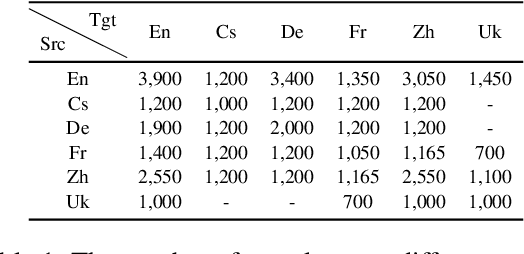
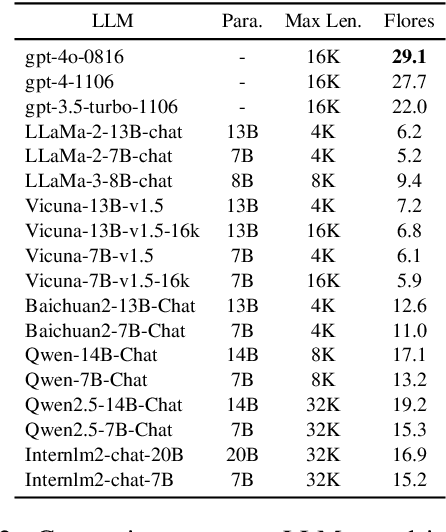
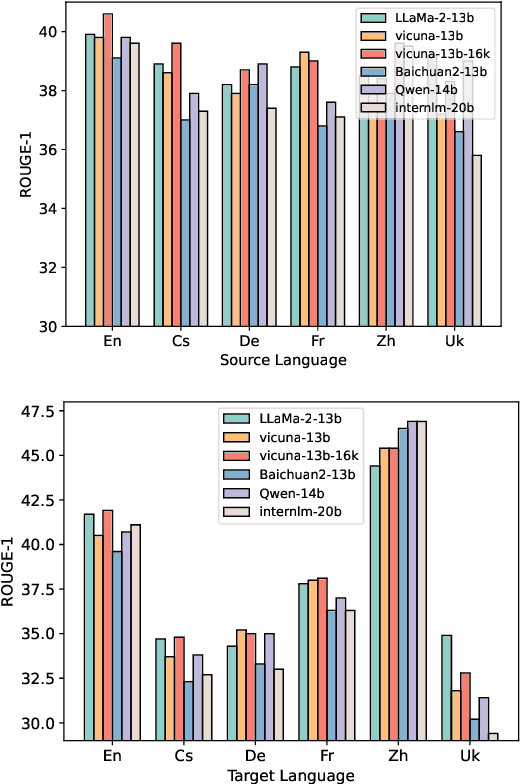
Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
ExTrans: Multilingual Deep Reasoning Translation via Exemplar-Enhanced Reinforcement Learning
May 19, 2025In recent years, the emergence of large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, has shown impressive capabilities in complex problems, e.g., mathematics and coding. Some pioneering studies attempt to bring the success of LRMs in neural machine translation (MT). They try to build LRMs with deep reasoning MT ability via reinforcement learning (RL). Despite some progress that has been made, these attempts generally focus on several high-resource languages, e.g., English and Chinese, leaving the performance on other languages unclear. Besides, the reward modeling methods in previous work do not fully unleash the potential of reinforcement learning in MT. In this work, we first design a new reward modeling method that compares the translation results of the policy MT model with a strong LRM (i.e., DeepSeek-R1-671B), and quantifies the comparisons to provide rewards. Experimental results demonstrate the superiority of the reward modeling method. Using Qwen2.5-7B-Instruct as the backbone, the trained model achieves the new state-of-the-art performance in literary translation, and outperforms strong LRMs including OpenAI-o1 and DeepSeeK-R1. Furthermore, we extend our method to the multilingual settings with 11 languages. With a carefully designed lightweight reward modeling in RL, we can simply transfer the strong MT ability from a single direction into multiple (i.e., 90) translation directions and achieve impressive multilingual MT performance.
Deep Reasoning Translation via Reinforcement Learning
Apr 14, 2025



Recently, deep reasoning LLMs (e.g., OpenAI o1/o3 and DeepSeek-R1) have shown promising performance in various complex tasks. Free translation is an important and interesting task in the multilingual world, which requires going beyond word-for-word translation and taking cultural differences into account. This task is still under-explored in deep reasoning LLMs. In this paper, we introduce DeepTrans, a deep reasoning translation model that learns free translation via reinforcement learning. Specifically, we carefully build a reward model with pre-defined scoring criteria on both the translation results and the thought process. Given the source sentences, the reward model teaches the deep translation model how to think and free-translate them during reinforcement learning. In this way, training DeepTrans does not need any labeled translations, avoiding the human-intensive annotation or resource-intensive data synthesis. Experimental results show the effectiveness of DeepTrans. Using Qwen2.5-7B as the backbone, DeepTrans improves performance by 16.3% in literature translation, and outperforms strong deep reasoning baselines as well as baselines that are fine-tuned with synthesized data. Moreover, we summarize the failures and interesting findings during our RL exploration. We hope this work could inspire other researchers in free translation.
DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought
Dec 23, 2024



Recently, O1-like models have emerged as representative examples, illustrating the effectiveness of long chain-of-thought (CoT) in reasoning tasks such as math and coding tasks. In this paper, we introduce DRT-o1, an attempt to bring the success of long CoT to neural machine translation (MT). Specifically, in view of the literature books that might involve similes and metaphors, translating these texts to a target language is very difficult in practice due to cultural differences. In such cases, literal translation often fails to convey the intended meaning effectively. Even for professional human translators, considerable thought must be given to preserving semantics throughout the translation process. To simulate LLMs' long thought ability in MT, we first mine sentences containing similes or metaphors from existing literature books, and then develop a multi-agent framework to translate these sentences via long thought. In the multi-agent framework, a translator is used to iteratively translate the source sentence under the suggestions provided by an advisor. To ensure the effectiveness of the long thoughts, an evaluator is also employed to judge whether the translation in the current round is better than the previous one or not. In this manner, we collect tens of thousands of long-thought MT data, which is used to train our DRT-o1. The experimental results on literature translation demonstrate the effectiveness of the DRT-o1. Using Qwen2.5-7B and Qwen2.5-14B as the backbones, the improvement brought by DRT-o1 achieves 7.33~8.26 BLEU and 1.66~3.36 CometScore. Besides, DRT-o1-7B can outperform QwQ-32B-Preview by 7.82 BLEU and 1.46 CometScore, showing its effectiveness. The project is available at https://github.com/krystalan/DRT-o1
Retrieval-Augmented Machine Translation with Unstructured Knowledge
Dec 05, 2024Retrieval-augmented generation (RAG) introduces additional information to enhance large language models (LLMs). In machine translation (MT), previous work typically retrieves in-context examples from paired MT corpora, or domain-specific knowledge from knowledge graphs, to enhance models' MT ability. However, a large amount of world knowledge is organized in unstructured documents, and might not be fully paired across different languages. In this paper, we study retrieval-augmented MT using unstructured documents. Specifically, we build RAGtrans, the first benchmark to train and evaluate LLMs' retrieval-augmented MT ability. RAGtrans contains 79K MT samples collected via GPT-4o and human translators. Besides, documents from different languages are also provided to supply the knowledge to these samples. Based on RAGtrans, we further propose a multi-task training method to teach LLMs how to use information from multilingual documents during their translation. The method uses existing multilingual corpora to create auxiliary training objectives without additional labeling requirements. Extensive experiments show that the method improves LLMs by 1.58-3.09 BLEU and 1.00-2.03 COMET scores.
Unleashing the Power of Emojis in Texts via Self-supervised Graph Pre-Training
Sep 26, 2024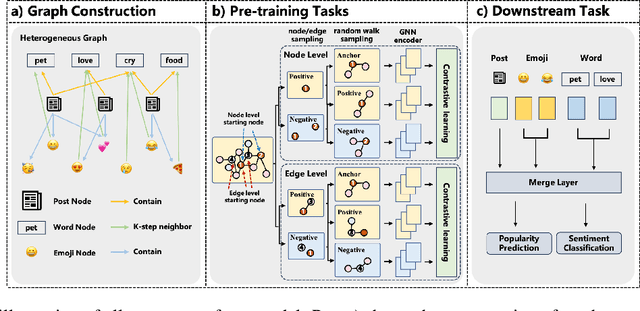
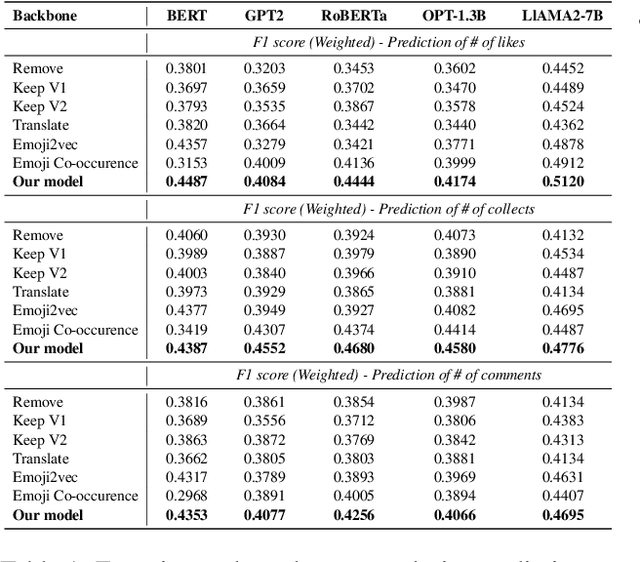
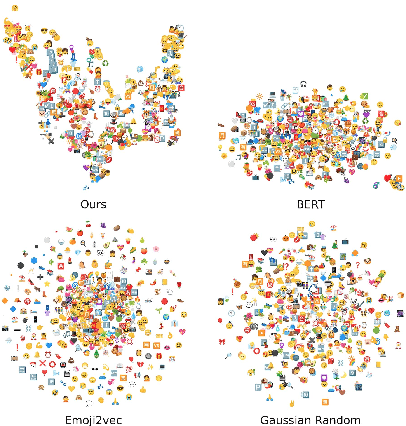
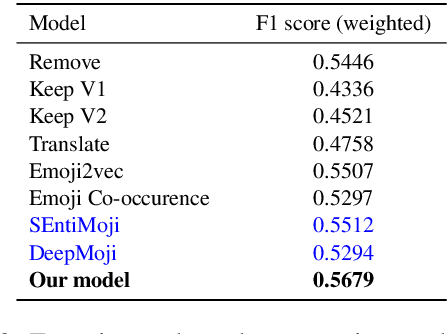
Emojis have gained immense popularity on social platforms, serving as a common means to supplement or replace text. However, existing data mining approaches generally either completely ignore or simply treat emojis as ordinary Unicode characters, which may limit the model's ability to grasp the rich semantic information in emojis and the interaction between emojis and texts. Thus, it is necessary to release the emoji's power in social media data mining. To this end, we first construct a heterogeneous graph consisting of three types of nodes, i.e. post, word and emoji nodes to improve the representation of different elements in posts. The edges are also well-defined to model how these three elements interact with each other. To facilitate the sharing of information among post, word and emoji nodes, we propose a graph pre-train framework for text and emoji co-modeling, which contains two graph pre-training tasks: node-level graph contrastive learning and edge-level link reconstruction learning. Extensive experiments on the Xiaohongshu and Twitter datasets with two types of downstream tasks demonstrate that our approach proves significant improvement over previous strong baseline methods.
ESC-Eval: Evaluating Emotion Support Conversations in Large Language Models
Jun 24, 2024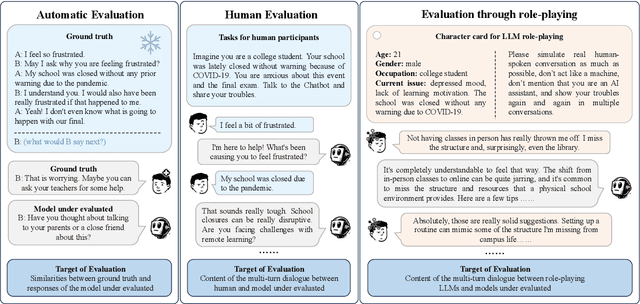
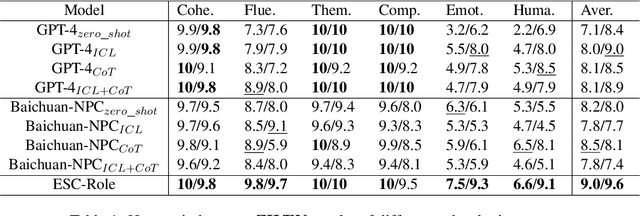
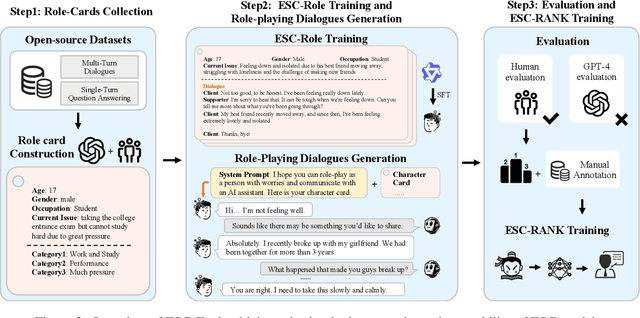
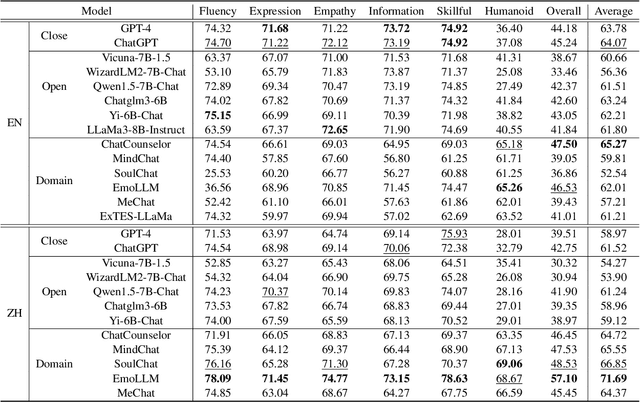
Emotion Support Conversation (ESC) is a crucial application, which aims to reduce human stress, offer emotional guidance, and ultimately enhance human mental and physical well-being. With the advancement of Large Language Models (LLMs), many researchers have employed LLMs as the ESC models. However, the evaluation of these LLM-based ESCs remains uncertain. Inspired by the awesome development of role-playing agents, we propose an ESC Evaluation framework (ESC-Eval), which uses a role-playing agent to interact with ESC models, followed by a manual evaluation of the interactive dialogues. In detail, we first re-organize 2,801 role-playing cards from seven existing datasets to define the roles of the role-playing agent. Second, we train a specific role-playing model called ESC-Role which behaves more like a confused person than GPT-4. Third, through ESC-Role and organized role cards, we systematically conduct experiments using 14 LLMs as the ESC models, including general AI-assistant LLMs (ChatGPT) and ESC-oriented LLMs (ExTES-Llama). We conduct comprehensive human annotations on interactive multi-turn dialogues of different ESC models. The results show that ESC-oriented LLMs exhibit superior ESC abilities compared to general AI-assistant LLMs, but there is still a gap behind human performance. Moreover, to automate the scoring process for future ESC models, we developed ESC-RANK, which trained on the annotated data, achieving a scoring performance surpassing 35 points of GPT-4. Our data and code are available at https://github.com/haidequanbu/ESC-Eval.