 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Apr 23, 2026Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
Sparse Growing Transformer: Training-Time Sparse Depth Allocation via Progressive Attention Looping
Mar 25, 2026Existing approaches to increasing the effective depth of Transformers predominantly rely on parameter reuse, extending computation through recursive execution. Under this paradigm, the network structure remains static along the training timeline, and additional computational depth is uniformly assigned to entire blocks at the parameter level. This rigidity across training time and parameter space leads to substantial computational redundancy during training. In contrast, we argue that depth allocation during training should not be a static preset, but rather a progressively growing structural process. Our systematic analysis reveals a deep-to-shallow maturation trajectory across layers, where high-entropy attention heads play a crucial role in semantic integration. Motivated by this observation, we introduce the Sparse Growing Transformer (SGT). SGT is a training-time sparse depth allocation framework that progressively extends recurrence from deeper to shallower layers via targeted attention looping on informative heads. This mechanism induces structural sparsity by selectively increasing depth only for a small subset of parameters as training evolves. Extensive experiments across multiple parameter scales demonstrate that SGT consistently outperforms training-time static block-level looping baselines under comparable settings, while reducing the additional training FLOPs overhead from approximately 16--20% to only 1--3% relative to a standard Transformer backbone.
Mixture of Universal Experts: Scaling Virtual Width via Depth-Width Transformation
Mar 05, 2026Mixture-of-Experts (MoE) decouples model capacity from per-token computation, yet their scalability remains limited by the physical dimensions of depth and width. To overcome this, we propose Mixture of Universal Experts (MOUE),a MoE generalization introducing a novel scaling dimension: Virtual Width. In general, MoUE aims to reuse a universal layer-agnostic expert pool across layers, converting depth into virtual width under a fixed per-token activation budget. However, two challenges remain: a routing path explosion from recursive expert reuse, and a mismatch between the exposure induced by reuse and the conventional load-balancing objectives. We address these with three core components: a Staggered Rotational Topology for structured expert sharing, a Universal Expert Load Balance for depth-aware exposure correction, and a Universal Router with lightweight trajectory state for coherent multi-step routing. Empirically, MoUE consistently outperforms matched MoE baselines by up to 1.3% across scaling regimes, enables progressive conversion of existing MoE checkpoints with up to 4.2% gains, and reveals a new scaling dimension for MoE architectures.
MacrOData: New Benchmarks of Thousands of Datasets for Tabular Outlier Detection
Feb 10, 2026Quality benchmarks are essential for fairly and accurately tracking scientific progress and enabling practitioners to make informed methodological choices. Outlier detection (OD) on tabular data underpins numerous real-world applications, yet existing OD benchmarks remain limited. The prominent OD benchmark AdBench is the de facto standard in the literature, yet comprises only 57 datasets. In addition to other shortcomings discussed in this work, its small scale severely restricts diversity and statistical power. We introduce MacrOData, a large-scale benchmark suite for tabular OD comprising three carefully curated components: OddBench, with 790 datasets containing real-world semantic anomalies; OvrBench, with 856 datasets featuring real-world statistical outliers; and SynBench, with 800 synthetically generated datasets spanning diverse data priors and outlier archetypes. Owing to its scale and diversity, MacrOData enables comprehensive and statistically robust evaluation of tabular OD methods. Our benchmarks further satisfy several key desiderata: We provide standardized train/test splits for all datasets, public/private benchmark partitions with held-out test labels for the latter reserved toward an online leaderboard, and annotate our datasets with semantic metadata. We conduct extensive experiments across all benchmarks, evaluating a broad range of OD methods comprising classical, deep, and foundation models, over diverse hyperparameter configurations. We report detailed empirical findings, practical guidelines, as well as individual performances as references for future research. All benchmarks containing 2,446 datasets combined are open-sourced, along with a publicly accessible leaderboard hosted at https://huggingface.co/MacrOData-CMU.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Blink: Dynamic Visual Token Resolution for Enhanced Multimodal Understanding
Dec 11, 2025Multimodal large language models (MLLMs) have achieved remarkable progress on various vision-language tasks, yet their visual perception remains limited. Humans, in comparison, perceive complex scenes efficiently by dynamically scanning and focusing on salient regions in a sequential "blink-like" process. Motivated by this strategy, we first investigate whether MLLMs exhibit similar behavior. Our pilot analysis reveals that MLLMs naturally attend to different visual regions across layers and that selectively allocating more computation to salient tokens can enhance visual perception. Building on this insight, we propose Blink, a dynamic visual token resolution framework that emulates the human-inspired process within a single forward pass. Specifically, Blink includes two modules: saliency-guided scanning and dynamic token resolution. It first estimates the saliency of visual tokens in each layer based on the attention map, and extends important tokens through a plug-and-play token super-resolution (TokenSR) module. In the next layer, it drops the extended tokens when they lose focus. This dynamic mechanism balances broad exploration and fine-grained focus, thereby enhancing visual perception adaptively and efficiently. Extensive experiments validate Blink, demonstrating its effectiveness in enhancing visual perception and multimodal understanding.
Intelligent Reflecting Surfaces for Integrated Sensing and Communications: A Survey
Nov 14, 2025
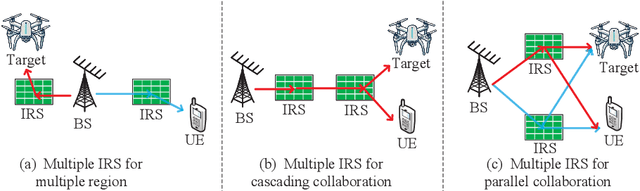
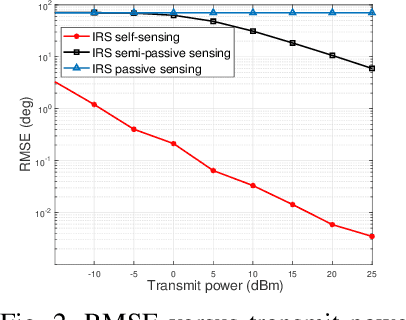
The rapid development of sixth-generation (6G) wireless networks requires seamless integration of communication and sensing to support ubiquitous intelligence and real-time, high-reliability applications. Integrated sensing and communication (ISAC) has emerged as a key solution for achieving this convergence, offering joint utilization of spectral, hardware, and computing resources. However, realizing high-performance ISAC remains challenging due to environmental line-of-sight (LoS) blockage, limited spatial resolution, and the inherent coverage asymmetry and resource coupling between sensing and communication. Intelligent reflecting surfaces (IRSs), featuring low-cost, energy-efficient, and programmable electromagnetic reconfiguration, provide a promising solution to overcome these limitations. This article presents a comprehensive overview of IRS-aided wireless sensing and ISAC technologies, including IRS architectures, target detection and estimation techniques, beamforming designs, and performance metrics. It further explores IRS-enabled new opportunities for more efficient performance balancing, coexistence, and networking in ISAC systems, focuses on current design bottlenecks, and outlines future research directions. This article aims to offer a unified design framework that guides the development of practical and scalable IRS-aided ISAC systems for the next-generation wireless network.
StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
Nov 10, 2025



Video Large Language Models (Video-LLMs) have demonstrated significant potential in the areas of video captioning, search, and summarization. However, current Video-LLMs still face challenges with long real-world videos. Recent methods have introduced a retrieval mechanism that retrieves query-relevant KV caches for question answering, enhancing the efficiency and accuracy of long real-world videos. However, the compression and retrieval of KV caches are still not fully explored. In this paper, we propose \textbf{StreamKV}, a training-free framework that seamlessly equips Video-LLMs with advanced KV cache retrieval and compression. Compared to previous methods that used uniform partitioning, StreamKV dynamically partitions video streams into semantic segments, which better preserves semantic information. For KV cache retrieval, StreamKV calculates a summary vector for each segment to retain segment-level information essential for retrieval. For KV cache compression, StreamKV introduces a guidance prompt designed to capture the key semantic elements within each segment, ensuring only the most informative KV caches are retained for answering questions. Moreover, StreamKV unifies KV cache retrieval and compression within a single module, performing both in a layer-adaptive manner, thereby further improving the effectiveness of streaming video question answering. Extensive experiments on public StreamingVQA benchmarks demonstrate that StreamKV significantly outperforms existing Online Video-LLMs, achieving superior accuracy while substantially improving both memory efficiency and computational latency. The code has been released at https://github.com/sou1p0wer/StreamKV.
Environment-Aware IRS Deployment via Channel Knowledge Map: Joint Sensing-Communications Coverage Optimization
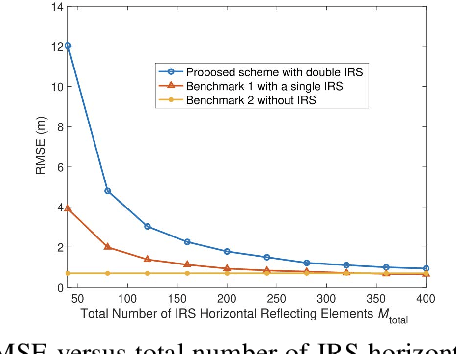
Sep 05, 2025This paper studies the intelligent reflecting surface (IRS) deployment optimization problem for IRS-enabled integrated sensing and communications (ISAC) systems, in which multiple IRSs are strategically deployed at candidate locations to assist a base station (BS) to enhance the coverage of both sensing and communications. We present an environment-aware IRS deployment design via exploiting the channel knowledge map (CKM), which provides the channel state information (CSI) between each candidate IRS location and BS or targeted sensing/communication points. Based on the obtained CSI from CKM, we optimize the deployment of IRSs, jointly with the BS's transmit beamforming and IRSs' reflective beamforming during operation, with the objective of minimizing the system cost, while guaranteeing the minimum illumination power requirements at sensing areas and the minimum signal-to-noise ratio (SNR) requirements at communication areas. In particular, we consider two cases when the IRSs' reflective beamforming optimization can be implemented dynamically in real time and quasi-stationarily over the whole operation period, respectively. For both cases, the joint IRS deployment and transmit/reflective beamforming designs are formulated as mixed-integer non-convex optimization problems, which are solved via the successive convex approximation (SCA)-based relax-and-bound method. Specifically, we first relax the binary IRS deployment indicators into continuous variables, then find converged solutions via SCA, and finally round relaxed indicators back to binary values. Numerical results demonstrate the effectiveness of our proposed algorithms in reducing the system cost while meeting the sensing and communication requirements.
Advantageous Parameter Expansion Training Makes Better Large Language Models
May 30, 2025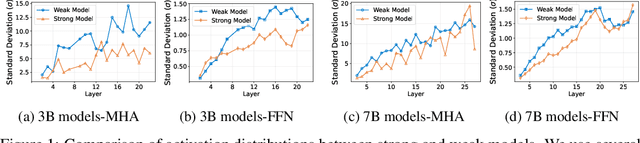
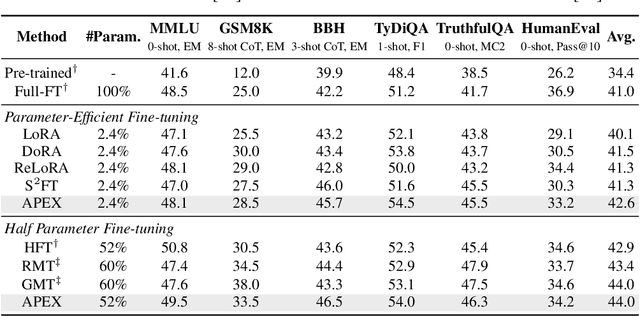
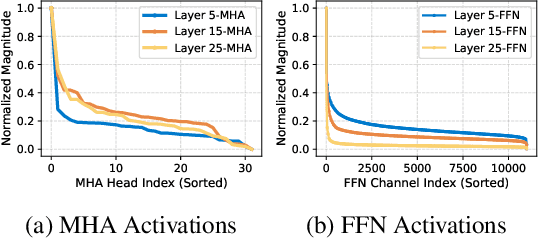
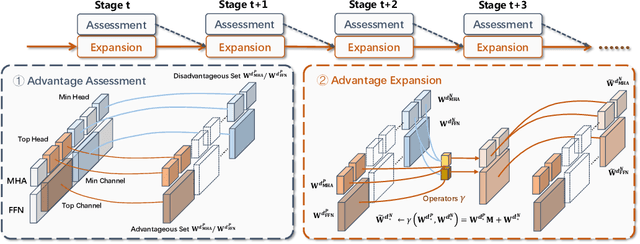
Although scaling up the number of trainable parameters in both pre-training and fine-tuning can effectively improve the performance of large language models, it also leads to increased computational overhead. When delving into the parameter difference, we find that a subset of parameters, termed advantageous parameters, plays a crucial role in determining model performance. Further analysis reveals that stronger models tend to possess more such parameters. In this paper, we propose Advantageous Parameter EXpansion Training (APEX), a method that progressively expands advantageous parameters into the space of disadvantageous ones, thereby increasing their proportion and enhancing training effectiveness. Further theoretical analysis from the perspective of matrix effective rank explains the performance gains of APEX. Extensive experiments on both instruction tuning and continued pre-training demonstrate that, in instruction tuning, APEX outperforms full-parameter tuning while using only 52% of the trainable parameters. In continued pre-training, APEX achieves the same perplexity level as conventional training with just 33% of the training data, and yields significant improvements on downstream tasks.