 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Diffusion Guided Knowledge Transfer for Multi-Domain Knowledge Graph Completion
Jul 03, 2026Multi-domain knowledge graph completion (MKGC) aims to improve missing triple prediction in a target KG by transferring knowledge from other support KGs. Existing methods typically enforce consistency constraints on equivalent entities across KGs to transfer knowledge, which risks suppressing domain-specific contextual information of entities. This design can also compromise entity representation information from all KG domains, impeding performance improvements, especially in low-resource data scenarios. To address this, we pioneer a generation-based paradigm for MKGC and propose DMKGC, a conditional diffusion-guided knowledge transfer framework. Our key insight is to treat each KG as a partial view of the entity entire information, and generate informative domain-general entity embeddings through diffusion models conditioned on support KGs. Particularly, we first initialize domain-agnostic entity embeddings as prior entity embeddings, and then encode them within individual KGs. Afterward, we fuse equivalent entities from support KGs as the conditional diffusion generation guidance. We leverage the prior entity embeddings as the proxy generation objective, which ensures this conditional generation to be unbiased towards any conditioned KGs. Simultaneously, we also train the generated embeddings to be predictive across KGs, thus preserving domain-specific information. Extensive experiments on 14 KGs in 3 benchmarks demonstrate a 4.3\% average MRR improvement in tail entity prediction over state-of-the-art methods, with sustained gains in low-resource data settings.
Personalized Multi-Interest Modeling for Cross-Domain Recommendation to Cold-Start Users
Apr 28, 2026Cross-domain recommendation (CDR) has demonstrated to be an effective solution for alleviating the user cold-start issue. By leveraging rich user-item interactions available in a richly informative source domain, CDR could improve the recommendation performance for cold-start users in the target domain. Previous CDR approaches mostly adhere the Embedding and Mapping (EMCDR) paradigm, which learns a user-shared mapping function to transfer users' preference from the source domain to the target domain, neglecting users' personalized preference. Recent CDR approaches further leverage the meta-learning paradigm, considering the CDR task for each user independently and learning user-specific mapping functions for each user. However, they mostly learn representations for each user individually, which ignores the common preference between different users, neglecting valuable information for CDR. In addition, all these approaches usually summarize the user's preference into an overall representation, which can hardly capture the user's multi-interest preference. To this end, we propose a personalized multi-interest modeling framework for CDR to cold-start users, termed as NF-NPCDR. Specifically, we propose a personalized preference encoder that enhances the neural process (NP) with the normalizing flow (NF) to convert the Gaussian (unimodal) distribution to a multimodal distribution, providing a novel way to capture the user's personalized multi-interest preference. Then, we propose a common preference encoder with a preference pool to capture the common preference between different users. Furthermore, we introduce a stochastic adaptive decoder to incorporate both the personalized and common preference for cold-start users, adaptively modulating both preference for better recommendation.
HyperMem: Hypergraph Memory for Long-Term Conversations
Apr 09, 2026Long-term memory is essential for conversational agents to maintain coherence, track persistent tasks, and provide personalized interactions across extended dialogues. However, existing approaches as Retrieval-Augmented Generation (RAG) and graph-based memory mostly rely on pairwise relations, which can hardly capture high-order associations, i.e., joint dependencies among multiple elements, causing fragmented retrieval. To this end, we propose HyperMem, a hypergraph-based hierarchical memory architecture that explicitly models such associations using hyperedges. Particularly, HyperMem structures memory into three levels: topics, episodes, and facts, and groups related episodes and their facts via hyperedges, unifying scattered content into coherent units. Leveraging this structure, we design a hybrid lexical-semantic index and a coarse-to-fine retrieval strategy, supporting accurate and efficient retrieval of high-order associations. Experiments on the LoCoMo benchmark show that HyperMem achieves state-of-the-art performance with 92.73% LLM-as-a-judge accuracy, demonstrating the effectiveness of HyperMem for long-term conversations.
Mixture of Universal Experts: Scaling Virtual Width via Depth-Width Transformation
Mar 05, 2026Mixture-of-Experts (MoE) decouples model capacity from per-token computation, yet their scalability remains limited by the physical dimensions of depth and width. To overcome this, we propose Mixture of Universal Experts (MOUE),a MoE generalization introducing a novel scaling dimension: Virtual Width. In general, MoUE aims to reuse a universal layer-agnostic expert pool across layers, converting depth into virtual width under a fixed per-token activation budget. However, two challenges remain: a routing path explosion from recursive expert reuse, and a mismatch between the exposure induced by reuse and the conventional load-balancing objectives. We address these with three core components: a Staggered Rotational Topology for structured expert sharing, a Universal Expert Load Balance for depth-aware exposure correction, and a Universal Router with lightweight trajectory state for coherent multi-step routing. Empirically, MoUE consistently outperforms matched MoE baselines by up to 1.3% across scaling regimes, enables progressive conversion of existing MoE checkpoints with up to 4.2% gains, and reveals a new scaling dimension for MoE architectures.
S2CDR: Smoothing-Sharpening Process Model for Cross-Domain Recommendation
Mar 03, 2026User cold-start problem is a long-standing challenge in recommendation systems. Fortunately, cross-domain recommendation (CDR) has emerged as a highly effective remedy for the user cold-start challenge, with recently developed diffusion models (DMs) demonstrating exceptional performance. However, these DMs-based CDR methods focus on dealing with user-item interactions, overlooking correlations between items across the source and target domains. Meanwhile, the Gaussian noise added in the forward process of diffusion models would hurt user's personalized preference, leading to the difficulty in transferring user preference across domains. To this end, we propose a novel paradigm of Smoothing-Sharpening Process Model for CDR to cold-start users, termed as S2CDR which features a corruption-recovery architecture and is solved with respect to ordinary differential equations (ODEs). Specifically, the smoothing process gradually corrupts the original user-item/item-item interaction matrices derived from both domains into smoothed preference signals in a noise-free manner, and the sharpening process iteratively sharpens the preference signals to recover the unknown interactions for cold-start users. Wherein, for the smoothing process, we introduce the heat equation on the item-item similarity graph to better capture the correlations between items across domains, and further build the tailor-designed low-pass filter to filter out the high-frequency noise information for capturing user's intrinsic preference, in accordance with the graph signal processing (GSP) theory. Extensive experiments on three real-world CDR scenarios confirm that our S2CDR significantly outperforms previous SOTA methods in a training-free manner.
From Agnostic to Specific: Latent Preference Diffusion for Multi-Behavior Sequential Recommendation
Feb 26, 2026Multi-behavior sequential recommendation (MBSR) aims to learn the dynamic and heterogeneous interactions of users' multi-behavior sequences, so as to capture user preferences under target behavior for the next interacted item prediction. Unlike previous methods that adopt unidirectional modeling by mapping auxiliary behaviors to target behavior, recent concerns are shifting from behavior-fixed to behavior-specific recommendation. However, these methods still ignore the user's latent preference that underlying decision-making, leading to suboptimal solutions. Meanwhile, due to the asymmetric deterministic between items and behaviors, discriminative paradigm based on preference scoring is unsuitable to capture the uncertainty from low-entropy behaviors to high-entropy items, failing to provide efficient and diverse recommendation. To address these challenges, we propose \textbf{FatsMB}, a framework based diffusion model that guides preference generation \textit{\textbf{F}rom Behavior-\textbf{A}gnostic \textbf{T}o Behavior-\textbf{S}pecific} in latent spaces, enabling diverse and accurate \textit{\textbf{M}ulti-\textbf{B}ehavior Sequential Recommendation}. Specifically, we design a Multi-Behavior AutoEncoder (MBAE) to construct a unified user latent preference space, facilitating interaction and collaboration across Behaviors, within Behavior-aware RoPE (BaRoPE) employed for multiple information fusion. Subsequently, we conduct target behavior-specific preference transfer in the latent space, enriching with informative priors. A Multi-Condition Guided Layer Normalization (MCGLN) is introduced for the denoising. Extensive experiments on real-world datasets demonstrate the effectiveness of our model.
Hyperbolic-PDE GNN: Spectral Graph Neural Networks in the Perspective of A System of Hyperbolic Partial Differential Equations
May 29, 2025Graph neural networks (GNNs) leverage message passing mechanisms to learn the topological features of graph data. Traditional GNNs learns node features in a spatial domain unrelated to the topology, which can hardly ensure topological features. In this paper, we formulates message passing as a system of hyperbolic partial differential equations (hyperbolic PDEs), constituting a dynamical system that explicitly maps node representations into a particular solution space. This solution space is spanned by a set of eigenvectors describing the topological structure of graphs. Within this system, for any moment in time, a node features can be decomposed into a superposition of the basis of eigenvectors. This not only enhances the interpretability of message passing but also enables the explicit extraction of fundamental characteristics about the topological structure. Furthermore, by solving this system of hyperbolic partial differential equations, we establish a connection with spectral graph neural networks (spectral GNNs), serving as a message passing enhancement paradigm for spectral GNNs.We further introduce polynomials to approximate arbitrary filter functions. Extensive experiments demonstrate that the paradigm of hyperbolic PDEs not only exhibits strong flexibility but also significantly enhances the performance of various spectral GNNs across diverse graph tasks.
* 18 pages, 2 figures, published to ICML 2025
Graph Wave Networks
May 26, 2025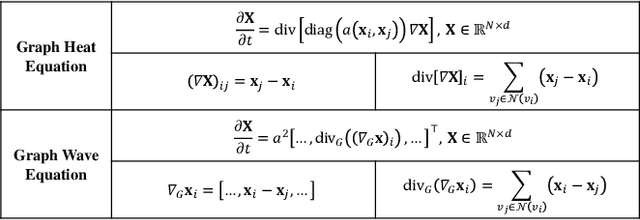
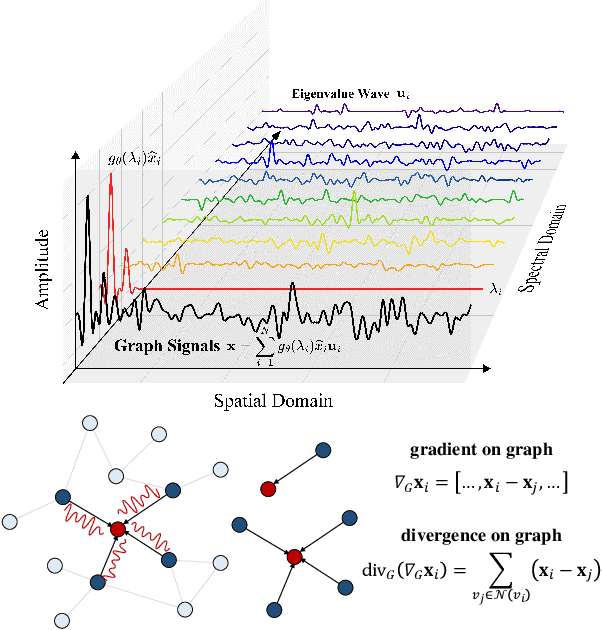
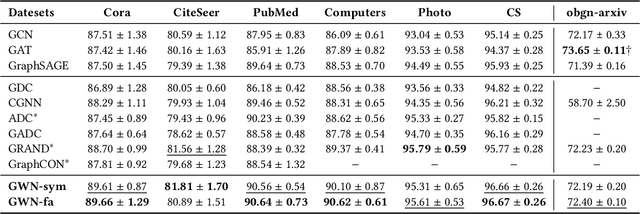
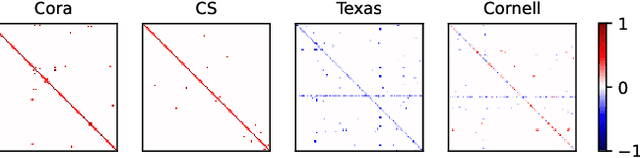
Dynamics modeling has been introduced as a novel paradigm in message passing (MP) of graph neural networks (GNNs). Existing methods consider MP between nodes as a heat diffusion process, and leverage heat equation to model the temporal evolution of nodes in the embedding space. However, heat equation can hardly depict the wave nature of graph signals in graph signal processing. Besides, heat equation is essentially a partial differential equation (PDE) involving a first partial derivative of time, whose numerical solution usually has low stability, and leads to inefficient model training. In this paper, we would like to depict more wave details in MP, since graph signals are essentially wave signals that can be seen as a superposition of a series of waves in the form of eigenvector. This motivates us to consider MP as a wave propagation process to capture the temporal evolution of wave signals in the space. Based on wave equation in physics, we innovatively develop a graph wave equation to leverage the wave propagation on graphs. In details, we demonstrate that the graph wave equation can be connected to traditional spectral GNNs, facilitating the design of graph wave networks based on various Laplacians and enhancing the performance of the spectral GNNs. Besides, the graph wave equation is particularly a PDE involving a second partial derivative of time, which has stronger stability on graphs than the heat equation that involves a first partial derivative of time. Additionally, we theoretically prove that the numerical solution derived from the graph wave equation are constantly stable, enabling to significantly enhance model efficiency while ensuring its performance. Extensive experiments show that GWNs achieve SOTA and efficient performance on benchmark datasets, and exhibit outstanding performance in addressing challenging graph problems, such as over-smoothing and heterophily.
* 15 pages, 8 figures, published to WWW 2025
Mitigating Modality Bias in Multi-modal Entity Alignment from a Causal Perspective
Apr 29, 2025



Multi-Modal Entity Alignment (MMEA) aims to retrieve equivalent entities from different Multi-Modal Knowledge Graphs (MMKGs), a critical information retrieval task. Existing studies have explored various fusion paradigms and consistency constraints to improve the alignment of equivalent entities, while overlooking that the visual modality may not always contribute positively. Empirically, entities with low-similarity images usually generate unsatisfactory performance, highlighting the limitation of overly relying on visual features. We believe the model can be biased toward the visual modality, leading to a shortcut image-matching task. To address this, we propose a counterfactual debiasing framework for MMEA, termed CDMEA, which investigates visual modality bias from a causal perspective. Our approach aims to leverage both visual and graph modalities to enhance MMEA while suppressing the direct causal effect of the visual modality on model predictions. By estimating the Total Effect (TE) of both modalities and excluding the Natural Direct Effect (NDE) of the visual modality, we ensure that the model predicts based on the Total Indirect Effect (TIE), effectively utilizing both modalities and reducing visual modality bias. Extensive experiments on 9 benchmark datasets show that CDMEA outperforms 14 state-of-the-art methods, especially in low-similarity, high-noise, and low-resource data scenarios.
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
Feb 19, 2025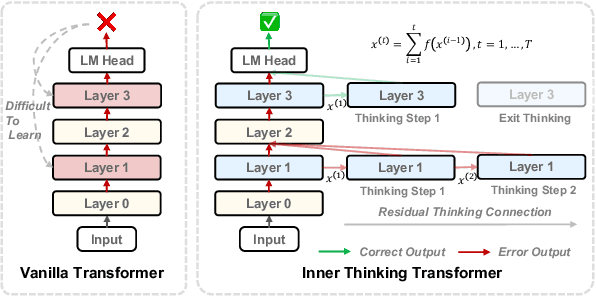
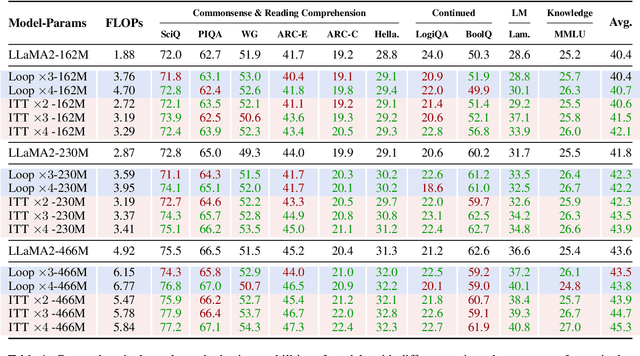
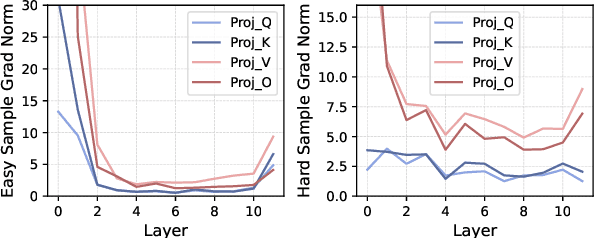
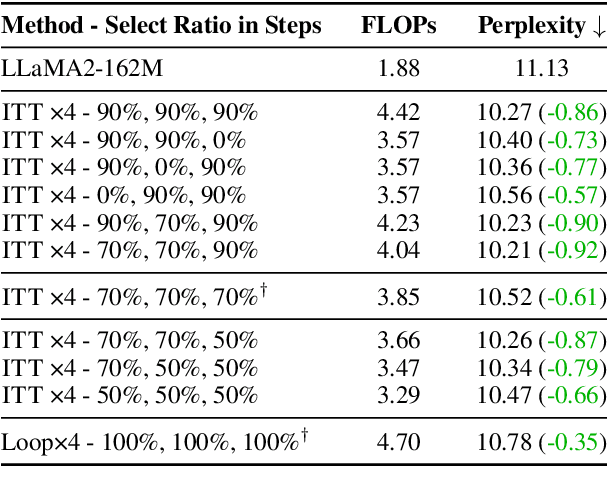
Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals challenging tokens induce abrupt gradient spikes across layers, exposing architectural stress points in standard Transformers. Building on this insight, we propose Inner Thinking Transformer (ITT), which reimagines layer computations as implicit thinking steps. ITT dynamically allocates computation through Adaptive Token Routing, iteratively refines representations via Residual Thinking Connections, and distinguishes reasoning phases using Thinking Step Encoding. ITT enables deeper processing of critical tokens without parameter expansion. Evaluations across 162M-466M parameter models show ITT achieves 96.5\% performance of a 466M Transformer using only 162M parameters, reduces training data by 43.2\%, and outperforms Transformer/Loop variants in 11 benchmarks. By enabling elastic computation allocation during inference, ITT balances performance and efficiency through architecture-aware optimization of implicit thinking pathways.