 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadFM: Foundational Text-Driven Quadruped Motion Dataset for Generation and Control
Mar 25, 2026Despite significant advances in quadrupedal robotics, a critical gap persists in foundational motion resources that holistically integrate diverse locomotion, emotionally expressive behaviors, and rich language semantics-essential for agile, intuitive human-robot interaction. Current quadruped motion datasets are limited to a few mocap primitives (e.g., walk, trot, sit) and lack diverse behaviors with rich language grounding. To bridge this gap, we introduce Quadruped Foundational Motion (QuadFM) , the first large-scale, ultra-high-fidelity dataset designed for text-to-motion generation and general motion control. QuadFM contains 11,784 curated motion clips spanning locomotion, interactive, and emotion-expressive behaviors (e.g., dancing, stretching, peeing), each with three-layer annotation-fine-grained action labels, interaction scenarios, and natural language commands-totaling 35,352 descriptions to support language-conditioned understanding and command execution. We further propose Gen2Control RL, a unified framework that jointly trains a general motion controller and a text-to-motion generator, enabling efficient end-to-end inference on edge hardware. On a real quadruped robot with an NVIDIA Orin, our system achieves real-time motion synthesis (<500 ms latency). Simulation and real-world results show realistic, diverse motions while maintaining robust physical interaction. The dataset will be released at https://github.com/GaoLii/QuadFM.
CoMaTrack: Competitive Multi-Agent Game-Theoretic Tracking with Vision-Language-Action Models
Mar 24, 2026Embodied Visual Tracking (EVT), a core dynamic task in embodied intelligence, requires an agent to precisely follow a language-specified target. Yet most existing methods rely on single-agent imitation learning, suffering from costly expert data and limited generalization due to static training environments. Inspired by competition-driven capability evolution, we propose CoMaTrack, a competitive game-theoretic multi-agent reinforcement learning framework that trains agents in a dynamic adversarial setting with competitive subtasks, yielding stronger adaptive planning and interference-resilient strategies. We further introduce CoMaTrack-Bench, the first benchmark for competitive EVT, featuring game scenarios between a tracker and adaptive opponents across diverse environments and instructions, enabling standardized robustness evaluation under active adversarial interactions. Experiments show that CoMaTrack achieves state-of-the-art results on both standard benchmarks and CoMaTrack-Bench. Notably, a 3B VLM trained with our framework surpasses previous single-agent imitation learning methods based on 7B models on the challenging EVT-Bench, achieving 92.1% in STT, 74.2% in DT, and 57.5% in AT. The benchmark code will be available at https://github.com/wlqcode/CoMaTrack-Bench
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
DiffVL: Diffusion-Based Visual Localization on 2D Maps via BEV-Conditioned GPS Denoising
Sep 18, 2025



Accurate visual localization is crucial for autonomous driving, yet existing methods face a fundamental dilemma: While high-definition (HD) maps provide high-precision localization references, their costly construction and maintenance hinder scalability, which drives research toward standard-definition (SD) maps like OpenStreetMap. Current SD-map-based approaches primarily focus on Bird's-Eye View (BEV) matching between images and maps, overlooking a ubiquitous signal-noisy GPS. Although GPS is readily available, it suffers from multipath errors in urban environments. We propose DiffVL, the first framework to reformulate visual localization as a GPS denoising task using diffusion models. Our key insight is that noisy GPS trajectory, when conditioned on visual BEV features and SD maps, implicitly encode the true pose distribution, which can be recovered through iterative diffusion refinement. DiffVL, unlike prior BEV-matching methods (e.g., OrienterNet) or transformer-based registration approaches, learns to reverse GPS noise perturbations by jointly modeling GPS, SD map, and visual signals, achieving sub-meter accuracy without relying on HD maps. Experiments on multiple datasets demonstrate that our method achieves state-of-the-art accuracy compared to BEV-matching baselines. Crucially, our work proves that diffusion models can enable scalable localization by treating noisy GPS as a generative prior-making a paradigm shift from traditional matching-based methods.
Proactive Guidance of Multi-Turn Conversation in Industrial Search
May 30, 2025



The evolution of Large Language Models (LLMs) has significantly advanced multi-turn conversation systems, emphasizing the need for proactive guidance to enhance users' interactions. However, these systems face challenges in dynamically adapting to shifts in users' goals and maintaining low latency for real-time interactions. In the Baidu Search AI assistant, an industrial-scale multi-turn search system, we propose a novel two-phase framework to provide proactive guidance. The first phase, Goal-adaptive Supervised Fine-Tuning (G-SFT), employs a goal adaptation agent that dynamically adapts to user goal shifts and provides goal-relevant contextual information. G-SFT also incorporates scalable knowledge transfer to distill insights from LLMs into a lightweight model for real-time interaction. The second phase, Click-oriented Reinforcement Learning (C-RL), adopts a generate-rank paradigm, systematically constructs preference pairs from user click signals, and proactively improves click-through rates through more engaging guidance. This dual-phase architecture achieves complementary objectives: G-SFT ensures accurate goal tracking, while C-RL optimizes interaction quality through click signal-driven reinforcement learning. Extensive experiments demonstrate that our framework achieves 86.10% accuracy in offline evaluation (+23.95% over baseline) and 25.28% CTR in online deployment (149.06% relative improvement), while reducing inference latency by 69.55% through scalable knowledge distillation.
MLLM-Enhanced Face Forgery Detection: A Vision-Language Fusion Solution
May 04, 2025Reliable face forgery detection algorithms are crucial for countering the growing threat of deepfake-driven disinformation. Previous research has demonstrated the potential of Multimodal Large Language Models (MLLMs) in identifying manipulated faces. However, existing methods typically depend on either the Large Language Model (LLM) alone or an external detector to generate classification results, which often leads to sub-optimal integration of visual and textual modalities. In this paper, we propose VLF-FFD, a novel Vision-Language Fusion solution for MLLM-enhanced Face Forgery Detection. Our key contributions are twofold. First, we present EFF++, a frame-level, explainability-driven extension of the widely used FaceForensics++ (FF++) dataset. In EFF++, each manipulated video frame is paired with a textual annotation that describes both the forgery artifacts and the specific manipulation technique applied, enabling more effective and informative MLLM training. Second, we design a Vision-Language Fusion Network (VLF-Net) that promotes bidirectional interaction between visual and textual features, supported by a three-stage training pipeline to fully leverage its potential. VLF-FFD achieves state-of-the-art (SOTA) performance in both cross-dataset and intra-dataset evaluations, underscoring its exceptional effectiveness in face forgery detection.
Exploring Preference-Guided Diffusion Model for Cross-Domain Recommendation
Jan 20, 2025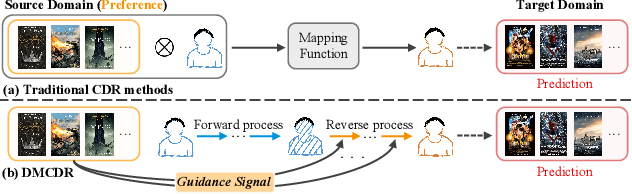
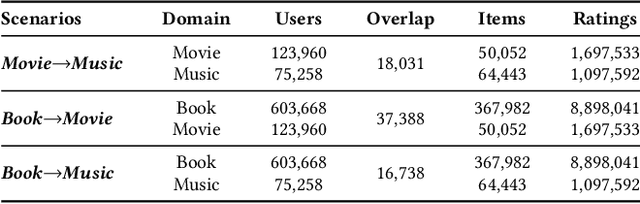
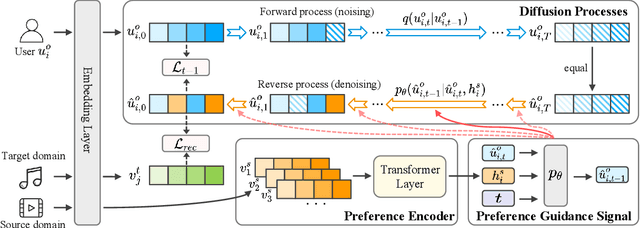
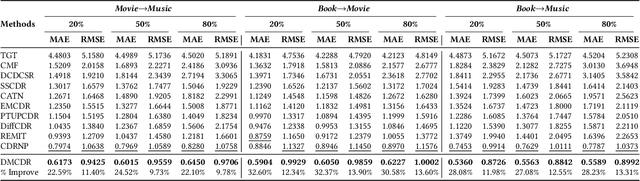
Cross-domain recommendation (CDR) has been proven as a promising way to alleviate the cold-start issue, in which the most critical problem is how to draw an informative user representation in the target domain via the transfer of user preference existing in the source domain. Prior efforts mostly follow the embedding-and-mapping paradigm, which first integrate the preference into user representation in the source domain, and then perform a mapping function on this representation to the target domain. However, they focus on mapping features across domains, neglecting to explicitly model the preference integration process, which may lead to learning coarse user representation. Diffusion models (DMs), which contribute to more accurate user/item representations due to their explicit information injection capability, have achieved promising performance in recommendation systems. Nevertheless, these DMs-based methods cannot directly account for valuable user preference in other domains, leading to challenges in adapting to the transfer of preference for cold-start users. Consequently, the feasibility of DMs for CDR remains underexplored. To this end, we explore to utilize the explicit information injection capability of DMs for user preference integration and propose a Preference-Guided Diffusion Model for CDR to cold-start users, termed as DMCDR. Specifically, we leverage a preference encoder to establish the preference guidance signal with the user's interaction history in the source domain. Then, we explicitly inject the preference guidance signal into the user representation step by step to guide the reverse process, and ultimately generate the personalized user representation in the target domain, thus achieving the transfer of user preference across domains. Furthermore, we comprehensively explore the impact of six DMs-based variants on CDR.
WMamba: Wavelet-based Mamba for Face Forgery Detection
Jan 16, 2025



With the rapid advancement of deepfake generation technologies, the demand for robust and accurate face forgery detection algorithms has become increasingly critical. Recent studies have demonstrated that wavelet analysis can uncover subtle forgery artifacts that remain imperceptible in the spatial domain. Wavelets effectively capture important facial contours, which are often slender, fine-grained, and global in nature. However, existing wavelet-based approaches fail to fully leverage these unique characteristics, resulting in sub-optimal feature extraction and limited generalizability. To address this challenge, we introduce WMamba, a novel wavelet-based feature extractor built upon the Mamba architecture. WMamba maximizes the utility of wavelet information through two key innovations. First, we propose Dynamic Contour Convolution (DCConv), which employs specially crafted deformable kernels to adaptively model slender facial contours. Second, by leveraging the Mamba architecture, our method captures long-range spatial relationships with linear computational complexity. This efficiency allows for the extraction of fine-grained, global forgery artifacts from small image patches. Extensive experimental results show that WMamba achieves state-of-the-art (SOTA) performance, highlighting its effectiveness and superiority in face forgery detection.
Research on environment perception and behavior prediction of intelligent UAV based on semantic communication
Jan 08, 2025The convergence of drone delivery systems, virtual worlds, and blockchain has transformed logistics and supply chain management, providing a fast, and environmentally friendly alternative to traditional ground transportation methods;Provide users with a real-world experience, virtual service providers need to collect up-to-the-minute delivery information from edge devices. To address this challenge, 1) a reinforcement learning approach is introduced to enable drones with fast training capabilities and the ability to autonomously adapt to new virtual scenarios for effective resource allocation.2) A semantic communication framework for meta-universes is proposed, which utilizes the extraction of semantic information to reduce the communication cost and incentivize the transmission of information for meta-universe services.3) In order to ensure that user information security, a lightweight authentication and key agreement scheme is designed between the drone and the user by introducing blockchain technology. In our experiments, the drone adaptation performance is improved by about 35\%, and the local offloading rate can reach 90\% with the increase of the number of base stations. The semantic communication system proposed in this paper is compared with the Cross Entropy baseline model. Introducing blockchain technology the throughput of the transaction is maintained at a stable value with different number of drones.
Concept Discovery in Deep Neural Networks for Explainable Face Anti-Spoofing
Dec 23, 2024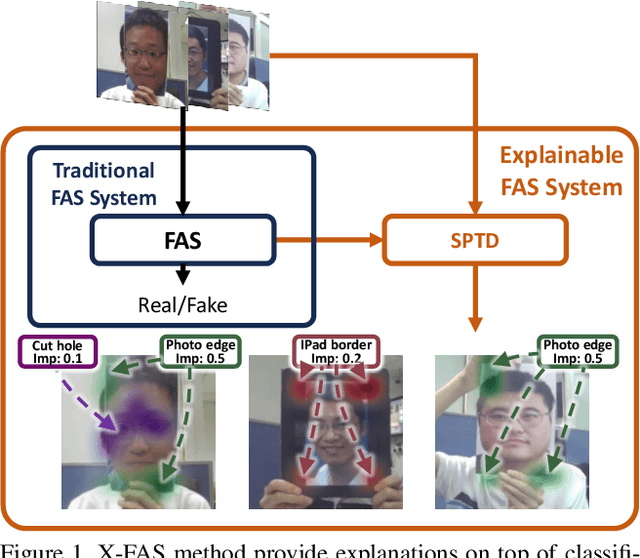
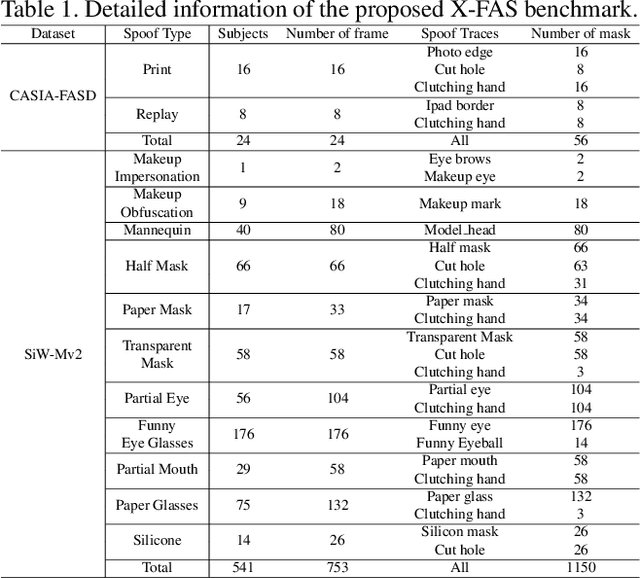
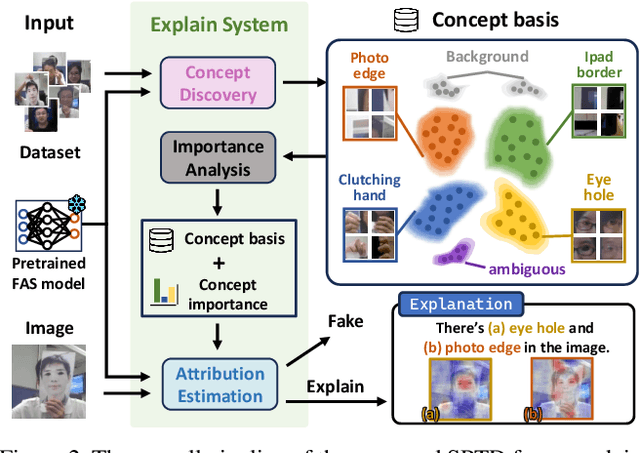
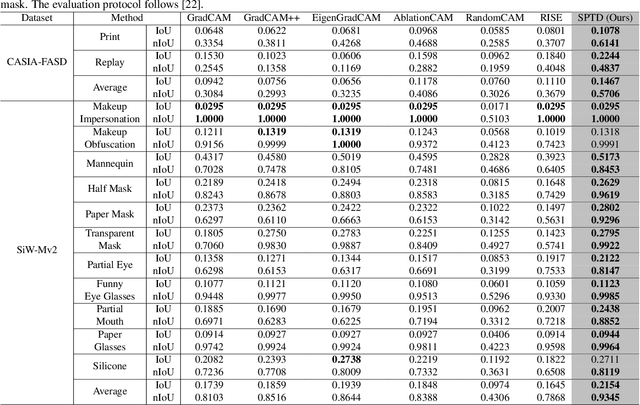
With the rapid growth usage of face recognition in people's daily life, face anti-spoofing becomes increasingly important to avoid malicious attacks. Recent face anti-spoofing models can reach a high classification accuracy on multiple datasets but these models can only tell people ``this face is fake'' while lacking the explanation to answer ``why it is fake''. Such a system undermines trustworthiness and causes user confusion, as it denies their requests without providing any explanations. In this paper, we incorporate XAI into face anti-spoofing and propose a new problem termed X-FAS (eXplainable Face Anti-Spoofing) empowering face anti-spoofing models to provide an explanation. We propose SPED (SPoofing Evidence Discovery), an X-FAS method which can discover spoof concepts and provide reliable explanations on the basis of discovered concepts. To evaluate the quality of X-FAS methods, we propose an X-FAS benchmark with annotated spoofing evidence by experts. We analyze SPED explanations on face anti-spoofing dataset and compare SPED quantitatively and qualitatively with previous XAI methods on proposed X-FAS benchmark. Experimental results demonstrate SPED's ability to generate reliable explanations.