 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
ClearAIR: A Human-Visual-Perception-Inspired All-in-One Image Restoration
Jan 06, 2026All-in-One Image Restoration (AiOIR) has advanced significantly, offering promising solutions for complex real-world degradations. However, most existing approaches rely heavily on degradation-specific representations, often resulting in oversmoothing and artifacts. To address this, we propose ClearAIR, a novel AiOIR framework inspired by Human Visual Perception (HVP) and designed with a hierarchical, coarse-to-fine restoration strategy. First, leveraging the global priority of early HVP, we employ a Multimodal Large Language Model (MLLM)-based Image Quality Assessment (IQA) model for overall evaluation. Unlike conventional IQA, our method integrates cross-modal understanding to more accurately characterize complex, composite degradations. Building upon this overall assessment, we then introduce a region awareness and task recognition pipeline. A semantic cross-attention, leveraging semantic guidance unit, first produces coarse semantic prompts. Guided by this regional context, a degradation-aware module implicitly captures region-specific degradation characteristics, enabling more precise local restoration. Finally, to recover fine details, we propose an internal clue reuse mechanism. It operates in a self-supervised manner to mine and leverage the intrinsic information of the image itself, substantially enhancing detail restoration. Experimental results show that ClearAIR achieves superior performance across diverse synthetic and real-world datasets.
OFL-SAM2: Prompt SAM2 with Online Few-shot Learner for Efficient Medical Image Segmentation
Dec 31, 2025The Segment Anything Model 2 (SAM2) has demonstrated remarkable promptable visual segmentation capabilities in video data, showing potential for extension to medical image segmentation (MIS) tasks involving 3D volumes and temporally correlated 2D image sequences. However, adapting SAM2 to MIS presents several challenges, including the need for extensive annotated medical data for fine-tuning and high-quality manual prompts, which are both labor-intensive and require intervention from medical experts. To address these challenges, we introduce OFL-SAM2, a prompt-free SAM2 framework for label-efficient MIS. Our core idea is to leverage limited annotated samples to train a lightweight mapping network that captures medical knowledge and transforms generic image features into target features, thereby providing additional discriminative target representations for each frame and eliminating the need for manual prompts. Crucially, the mapping network supports online parameter update during inference, enhancing the model's generalization across test sequences. Technically, we introduce two key components: (1) an online few-shot learner that trains the mapping network to generate target features using limited data, and (2) an adaptive fusion module that dynamically integrates the target features with the memory-attention features generated by frozen SAM2, leading to accurate and robust target representation. Extensive experiments on three diverse MIS datasets demonstrate that OFL-SAM2 achieves state-of-the-art performance with limited training data.
TGC-Net: A Structure-Aware and Semantically-Aligned Framework for Text-Guided Medical Image Segmentation
Dec 24, 2025Text-guided medical segmentation enhances segmentation accuracy by utilizing clinical reports as auxiliary information. However, existing methods typically rely on unaligned image and text encoders, which necessitate complex interaction modules for multimodal fusion. While CLIP provides a pre-aligned multimodal feature space, its direct application to medical imaging is limited by three main issues: insufficient preservation of fine-grained anatomical structures, inadequate modeling of complex clinical descriptions, and domain-specific semantic misalignment. To tackle these challenges, we propose TGC-Net, a CLIP-based framework focusing on parameter-efficient, task-specific adaptations. Specifically, it incorporates a Semantic-Structural Synergy Encoder (SSE) that augments CLIP's ViT with a CNN branch for multi-scale structural refinement, a Domain-Augmented Text Encoder (DATE) that injects large-language-model-derived medical knowledge, and a Vision-Language Calibration Module (VLCM) that refines cross-modal correspondence in a unified feature space. Experiments on five datasets across chest X-ray and thoracic CT modalities demonstrate that TGC-Net achieves state-of-the-art performance with substantially fewer trainable parameters, including notable Dice gains on challenging benchmarks.
ClusIR: Towards Cluster-Guided All-in-One Image Restoration
Dec 11, 2025All-in-One Image Restoration (AiOIR) aims to recover high-quality images from diverse degradations within a unified framework. However, existing methods often fail to explicitly model degradation types and struggle to adapt their restoration behavior to complex or mixed degradations. To address these issues, we propose ClusIR, a Cluster-Guided Image Restoration framework that explicitly models degradation semantics through learnable clustering and propagates cluster-aware cues across spatial and frequency domains for adaptive restoration. Specifically, ClusIR comprises two key components: a Probabilistic Cluster-Guided Routing Mechanism (PCGRM) and a Degradation-Aware Frequency Modulation Module (DAFMM). The proposed PCGRM disentangles degradation recognition from expert activation, enabling discriminative degradation perception and stable expert routing. Meanwhile, DAFMM leverages the cluster-guided priors to perform adaptive frequency decomposition and targeted modulation, collaboratively refining structural and textural representations for higher restoration fidelity. The cluster-guided synergy seamlessly bridges semantic cues with frequency-domain modulation, empowering ClusIR to attain remarkable restoration results across a wide range of degradations. Extensive experiments on diverse benchmarks validate that ClusIR reaches competitive performance under several scenarios.
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025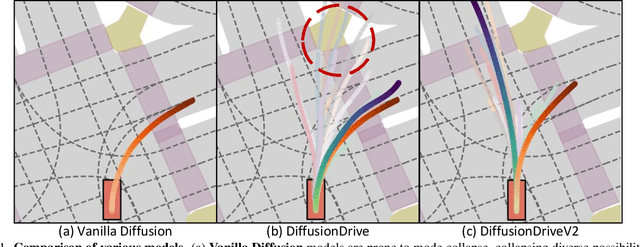
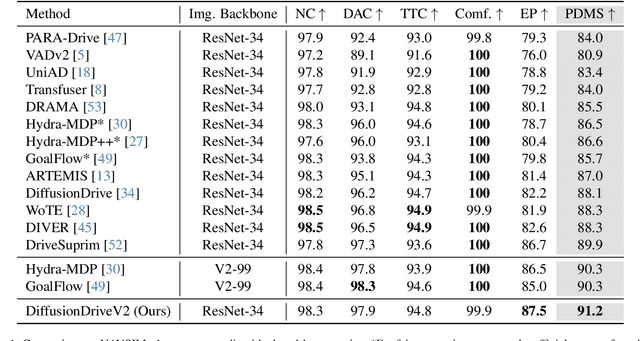
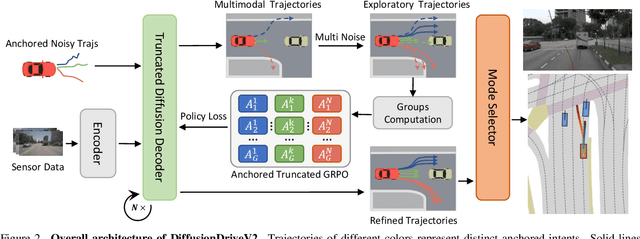
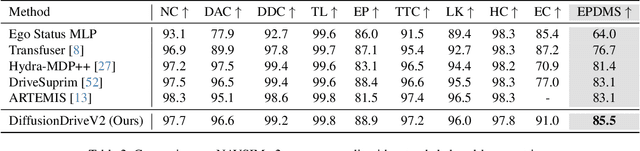
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
CoViPAL: Layer-wise Contextualized Visual Token Pruning for Large Vision-Language Models
Aug 24, 2025Large Vision-Language Models (LVLMs) process multimodal inputs consisting of text tokens and vision tokens extracted from images or videos. Due to the rich visual information, a single image can generate thousands of vision tokens, leading to high computational costs during the prefilling stage and significant memory overhead during decoding. Existing methods attempt to prune redundant vision tokens, revealing substantial redundancy in visual representations. However, these methods often struggle in shallow layers due to the lack of sufficient contextual information. We argue that many visual tokens are inherently redundant even in shallow layers and can be safely and effectively pruned with appropriate contextual signals. In this work, we propose CoViPAL, a layer-wise contextualized visual token pruning method that employs a Plug-and-Play Pruning Module (PPM) to predict and remove redundant vision tokens before they are processed by the LVLM. The PPM is lightweight, model-agnostic, and operates independently of the LVLM architecture, ensuring seamless integration with various models. Extensive experiments on multiple benchmarks demonstrate that CoViPAL outperforms training-free pruning methods under equal token budgets and surpasses training-based methods with comparable supervision. CoViPAL offers a scalable and efficient solution to improve inference efficiency in LVLMs without compromising accuracy.
S5: Scalable Semi-Supervised Semantic Segmentation in Remote Sensing
Aug 17, 2025Semi-supervised semantic segmentation (S4) has advanced remote sensing (RS) analysis by leveraging unlabeled data through pseudo-labeling and consistency learning. However, existing S4 studies often rely on small-scale datasets and models, limiting their practical applicability. To address this, we propose S5, the first scalable framework for semi-supervised semantic segmentation in RS, which unlocks the potential of vast unlabeled Earth observation data typically underutilized due to costly pixel-level annotations. Built upon existing large-scale RS datasets, S5 introduces a data selection strategy that integrates entropy-based filtering and diversity expansion, resulting in the RS4P-1M dataset. Using this dataset, we systematically scales S4 methods by pre-training RS foundation models (RSFMs) of varying sizes on this extensive corpus, significantly boosting their performance on land cover segmentation and object detection tasks. Furthermore, during fine-tuning, we incorporate a Mixture-of-Experts (MoE)-based multi-dataset fine-tuning approach, which enables efficient adaptation to multiple RS benchmarks with fewer parameters. This approach improves the generalization and versatility of RSFMs across diverse RS benchmarks. The resulting RSFMs achieve state-of-the-art performance across all benchmarks, underscoring the viability of scaling semi-supervised learning for RS applications. All datasets, code, and models will be released at https://github.com/MiliLab/S5
SpindleKV: A Novel KV Cache Reduction Method Balancing Both Shallow and Deep Layers
Jul 09, 2025Large Language Models (LLMs) have achieved impressive accomplishments in recent years. However, the increasing memory consumption of KV cache has possessed a significant challenge to the inference system. Eviction methods have revealed the inherent redundancy within the KV cache, demonstrating its potential for reduction, particularly in deeper layers. However, KV cache reduction for shallower layers has been found to be insufficient. Based on our observation that, the KV cache exhibits a high degree of similarity. Based on this observation, we proposed a novel KV cache reduction method, SpindleKV, which balances both shallow and deep layers. For deep layers, we employ an attention weight based eviction method, while for shallow layers, we apply a codebook based replacement approach which is learnt by similarity and merging policy. Moreover, SpindleKV addressed the Grouped-Query Attention (GQA) dilemma faced by other attention based eviction methods. Experiments on two common benchmarks with three different LLMs shown that SpindleKV obtained better KV cache reduction effect compared to baseline methods, while preserving similar or even better model performance.
Segment First or Comprehend First? Explore the Limit of Unsupervised Word Segmentation with Large Language Models
May 26, 2025Word segmentation stands as a cornerstone of Natural Language Processing (NLP). Based on the concept of "comprehend first, segment later", we propose a new framework to explore the limit of unsupervised word segmentation with Large Language Models (LLMs) and evaluate the semantic understanding capabilities of LLMs based on word segmentation. We employ current mainstream LLMs to perform word segmentation across multiple languages to assess LLMs' "comprehension". Our findings reveal that LLMs are capable of following simple prompts to segment raw text into words. There is a trend suggesting that models with more parameters tend to perform better on multiple languages. Additionally, we introduce a novel unsupervised method, termed LLACA ($\textbf{L}$arge $\textbf{L}$anguage Model-Inspired $\textbf{A}$ho-$\textbf{C}$orasick $\textbf{A}$utomaton). Leveraging the advanced pattern recognition capabilities of Aho-Corasick automata, LLACA innovatively combines these with the deep insights of well-pretrained LLMs. This approach not only enables the construction of a dynamic $n$-gram model that adjusts based on contextual information but also integrates the nuanced understanding of LLMs, offering significant improvements over traditional methods. Our source code is available at https://github.com/hkr04/LLACA