 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Atoms to Trees: Building a Structured Feature Forest with Hierarchical Sparse Autoencoders
Feb 12, 2026Sparse autoencoders (SAEs) have proven effective for extracting monosemantic features from large language models (LLMs), yet these features are typically identified in isolation. However, broad evidence suggests that LLMs capture the intrinsic structure of natural language, where the phenomenon of "feature splitting" in particular indicates that such structure is hierarchical. To capture this, we propose the Hierarchical Sparse Autoencoder (HSAE), which jointly learns a series of SAEs and the parent-child relationships between their features. HSAE strengthens the alignment between parent and child features through two novel mechanisms: a structural constraint loss and a random feature perturbation mechanism. Extensive experiments across various LLMs and layers demonstrate that HSAE consistently recovers semantically meaningful hierarchies, supported by both qualitative case studies and rigorous quantitative metrics. At the same time, HSAE preserves the reconstruction fidelity and interpretability of standard SAEs across different dictionary sizes. Our work provides a powerful, scalable tool for discovering and analyzing the multi-scale conceptual structures embedded in LLM representations.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025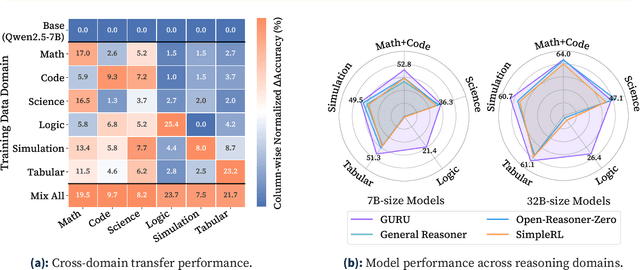
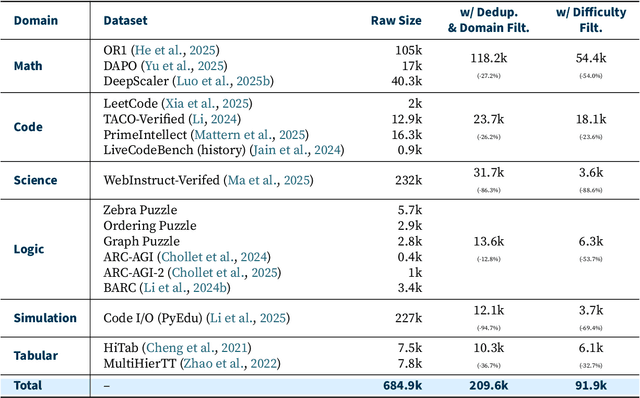
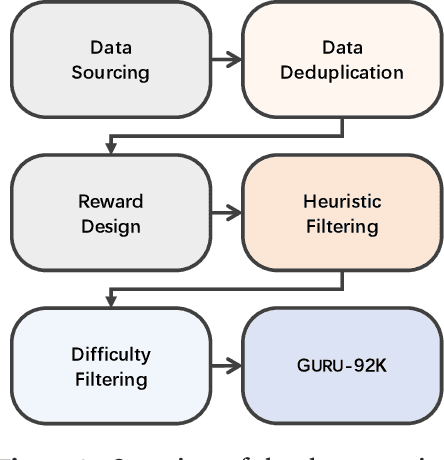

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
May 19, 2025



The recent explosion of large language models (LLMs), each with its own general or specialized strengths, makes scalable, reliable benchmarking more urgent than ever. Standard practices nowadays face fundamental trade-offs: closed-ended question-based benchmarks (eg MMLU) struggle with saturation as newer models emerge, while crowd-sourced leaderboards (eg Chatbot Arena) rely on costly and slow human judges. Recently, automated methods (eg LLM-as-a-judge) shed light on the scalability, but risk bias by relying on one or a few "authority" models. To tackle these issues, we propose Decentralized Arena (dearena), a fully automated framework leveraging collective intelligence from all LLMs to evaluate each other. It mitigates single-model judge bias by democratic, pairwise evaluation, and remains efficient at scale through two key components: (1) a coarse-to-fine ranking algorithm for fast incremental insertion of new models with sub-quadratic complexity, and (2) an automatic question selection strategy for the construction of new evaluation dimensions. Across extensive experiments across 66 LLMs, dearena attains up to 97% correlation with human judgements, while significantly reducing the cost. Our code and data will be publicly released on https://github.com/maitrix-org/de-arena.
Symbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025
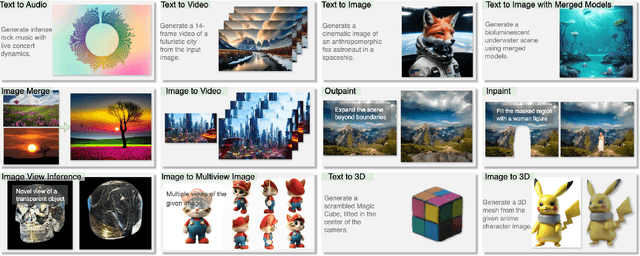
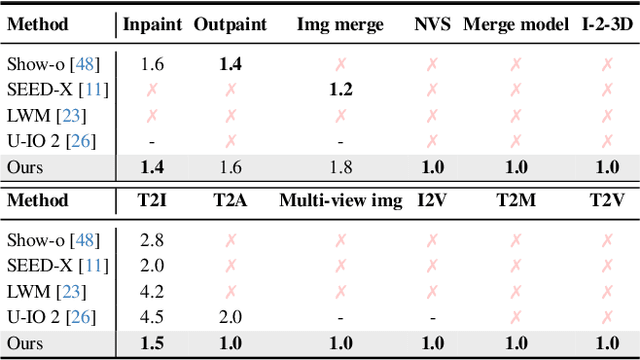

We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
Neutralizing Bias in LLM Reasoning using Entailment Graphs
Mar 14, 2025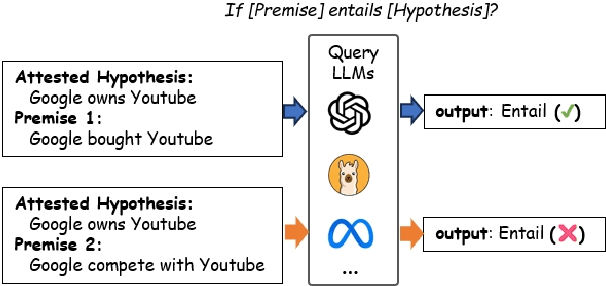


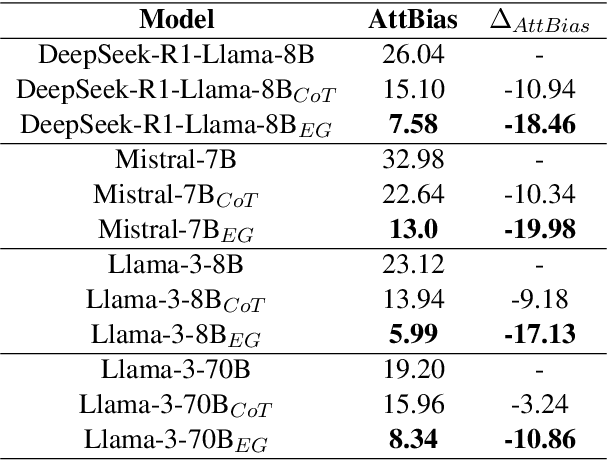
LLMs are often claimed to be capable of Natural Language Inference (NLI), which is widely regarded as a cornerstone of more complex forms of reasoning. However, recent works show that LLMs still suffer from hallucinations in NLI due to attestation bias, where LLMs overly rely on propositional memory to build shortcuts. To solve the issue, we design an unsupervised framework to construct counterfactual reasoning data and fine-tune LLMs to reduce attestation bias. To measure bias reduction, we build bias-adversarial variants of NLI datasets with randomly replaced predicates in premises while keeping hypotheses unchanged. Extensive evaluations show that our framework can significantly reduce hallucinations from attestation bias. Then, we further evaluate LLMs fine-tuned with our framework on original NLI datasets and their bias-neutralized versions, where original entities are replaced with randomly sampled ones. Extensive results show that our framework consistently improves inferential performance on both original and bias-neutralized NLI datasets.
Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs
Feb 26, 2025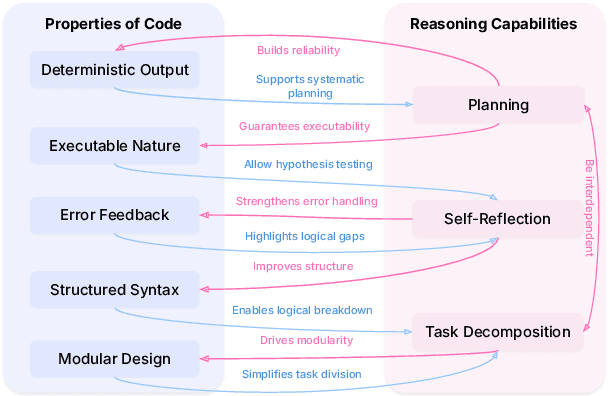
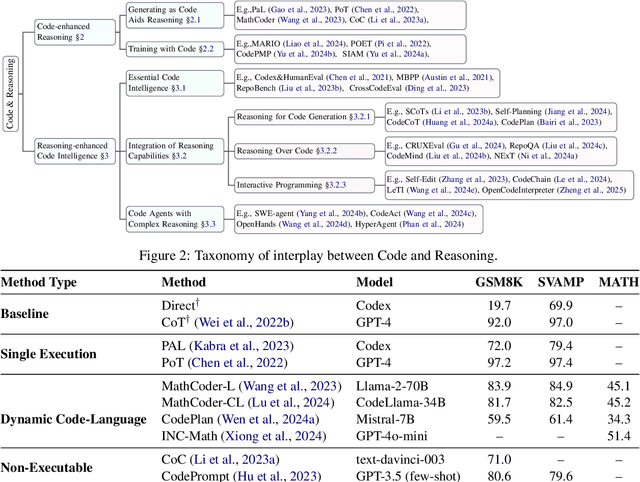


In large language models (LLMs), code and reasoning reinforce each other: code offers an abstract, modular, and logic-driven structure that supports reasoning, while reasoning translates high-level goals into smaller, executable steps that drive more advanced code intelligence. In this study, we examine how code serves as a structured medium for enhancing reasoning: it provides verifiable execution paths, enforces logical decomposition, and enables runtime validation. We also explore how improvements in reasoning have transformed code intelligence from basic completion to advanced capabilities, enabling models to address complex software engineering tasks through planning and debugging. Finally, we identify key challenges and propose future research directions to strengthen this synergy, ultimately improving LLM's performance in both areas.
Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Dec 22, 2024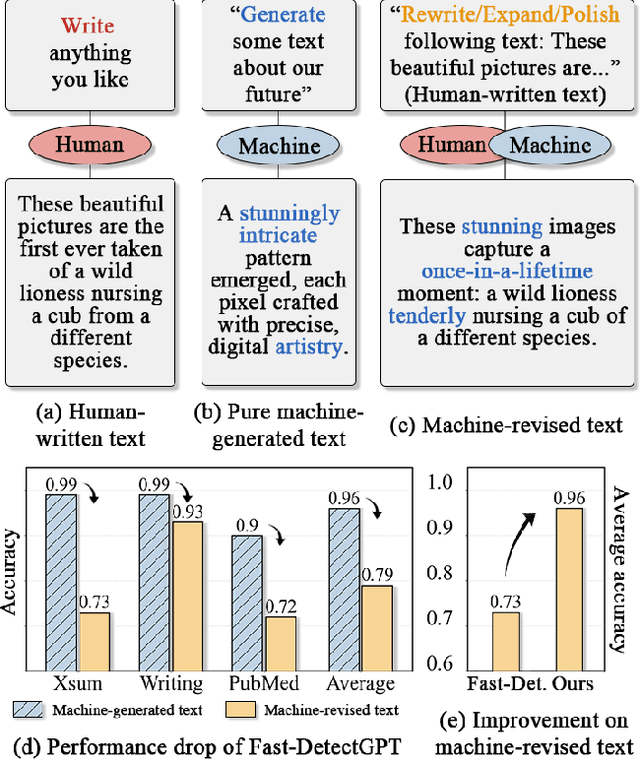
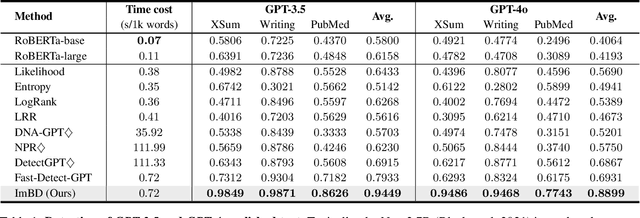
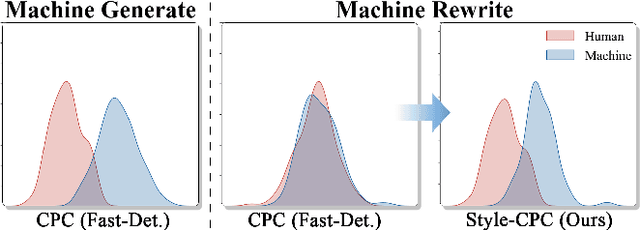
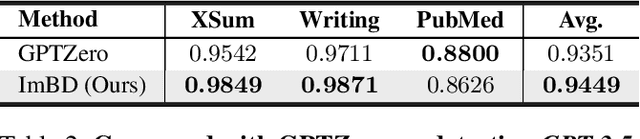
Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models
Nov 14, 2024
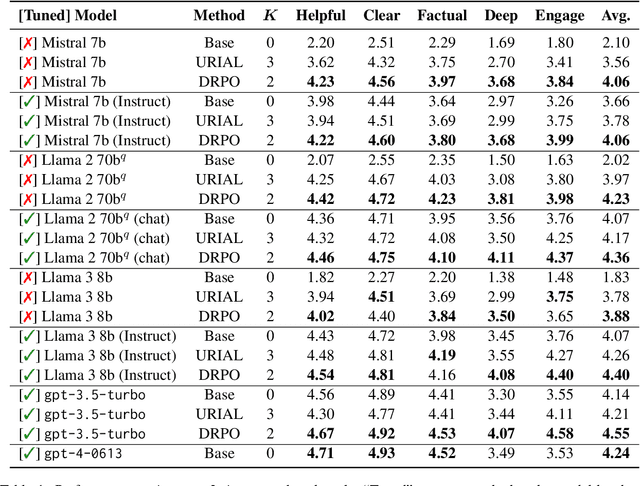
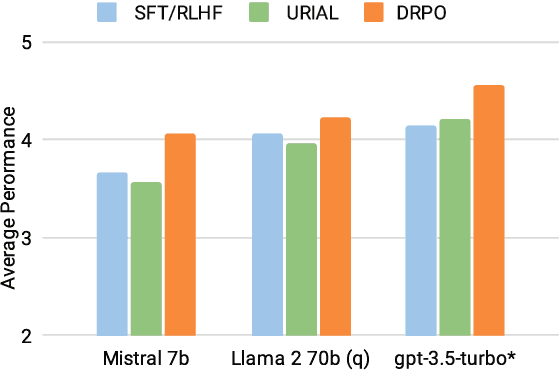
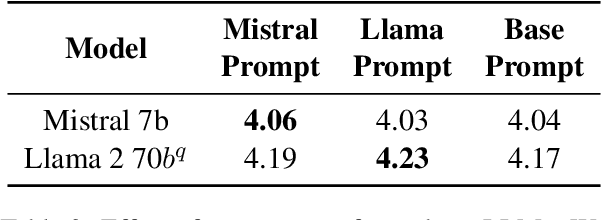
Aligning Large Language Models (LLMs) traditionally relies on costly training and human preference annotations. Self-alignment seeks to reduce these expenses by enabling models to align themselves. To further lower costs and achieve alignment without any expensive tuning or annotations, we introduce a new tuning-free approach for self-alignment, Dynamic Rewarding with Prompt Optimization (DRPO). Our approach leverages a search-based optimization framework that allows LLMs to iteratively self-improve and craft the optimal alignment instructions, all without additional training or human intervention. The core of DRPO is a dynamic rewarding mechanism, which identifies and rectifies model-specific alignment weaknesses, allowing LLMs to adapt efficiently to diverse alignment challenges. Empirical evaluations on eight recent LLMs, both open- and closed-sourced, demonstrate that DRPO significantly enhances alignment performance, with base models outperforming their SFT/RLHF-tuned counterparts. Moreover, the prompts automatically optimized by DRPO surpass those curated by human experts, further validating the effectiveness of our approach. Our findings highlight the great potential of current LLMs to achieve adaptive self-alignment through inference-time optimization, complementing tuning-based alignment methods.
Explicit Inductive Inference using Large Language Models
Aug 26, 2024



Large Language Models (LLMs) are reported to hold undesirable attestation bias on inference tasks: when asked to predict if a premise P entails a hypothesis H, instead of considering H's conditional truthfulness entailed by P, LLMs tend to use the out-of-context truth label of H as a fragile proxy. In this paper, we propose a pipeline that exploits this bias to do explicit inductive inference. Our pipeline uses an LLM to transform a premise into a set of attested alternatives, and then aggregate answers of the derived new entailment inquiries to support the original inference prediction. On a directional predicate entailment benchmark, we demonstrate that by applying this simple pipeline, we can improve the overall performance of LLMs on inference and substantially alleviate the impact of their attestation bias.
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Apr 08, 2024Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.