 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocAgent: A Multi-Agent System for Automated Code Documentation Generation
Apr 11, 2025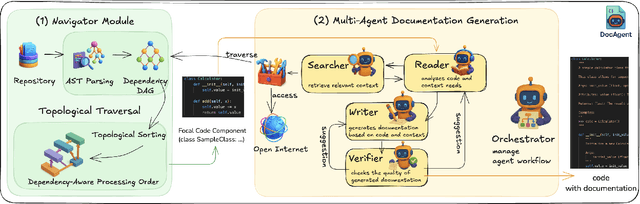
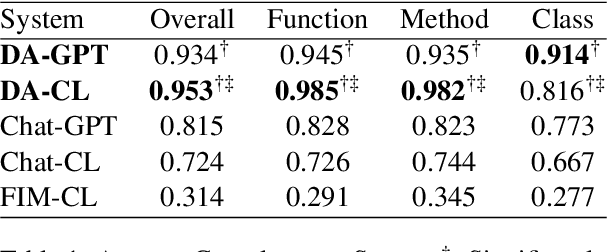
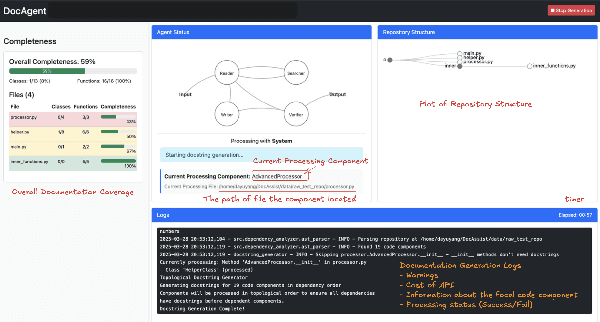

High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs
Feb 26, 2025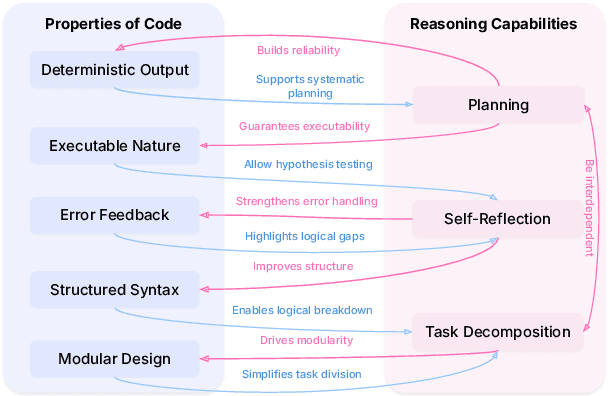
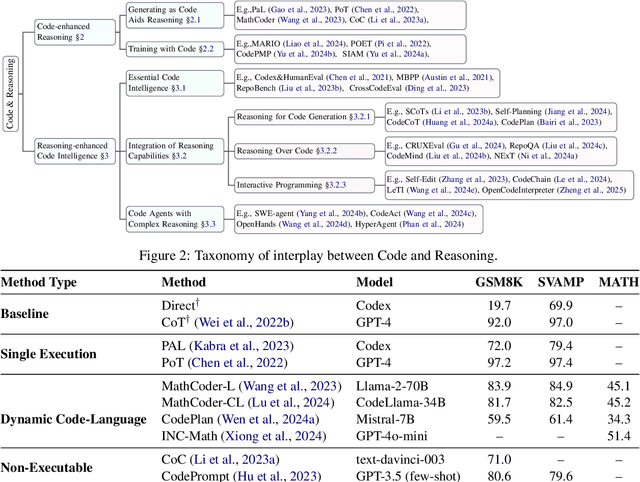


In large language models (LLMs), code and reasoning reinforce each other: code offers an abstract, modular, and logic-driven structure that supports reasoning, while reasoning translates high-level goals into smaller, executable steps that drive more advanced code intelligence. In this study, we examine how code serves as a structured medium for enhancing reasoning: it provides verifiable execution paths, enforces logical decomposition, and enables runtime validation. We also explore how improvements in reasoning have transformed code intelligence from basic completion to advanced capabilities, enabling models to address complex software engineering tasks through planning and debugging. Finally, we identify key challenges and propose future research directions to strengthen this synergy, ultimately improving LLM's performance in both areas.
Imitation of Life: A Search Engine for Biologically Inspired Design
Dec 20, 2023Biologically Inspired Design (BID), or Biomimicry, is a problem-solving methodology that applies analogies from nature to solve engineering challenges. For example, Speedo engineers designed swimsuits based on shark skin. Finding relevant biological solutions for real-world problems poses significant challenges, both due to the limited biological knowledge engineers and designers typically possess and to the limited BID resources. Existing BID datasets are hand-curated and small, and scaling them up requires costly human annotations. In this paper, we introduce BARcode (Biological Analogy Retriever), a search engine for automatically mining bio-inspirations from the web at scale. Using advances in natural language understanding and data programming, BARcode identifies potential inspirations for engineering challenges. Our experiments demonstrate that BARcode can retrieve inspirations that are valuable to engineers and designers tackling real-world problems, as well as recover famous historical BID examples. We release data and code; we view BARcode as a step towards addressing the challenges that have historically hindered the practical application of BID to engineering innovation.
A Probabilistic Approach to Neural Network Pruning
May 20, 2021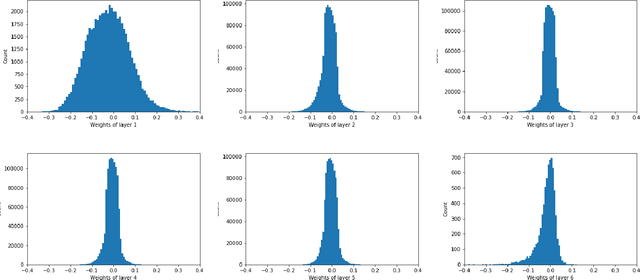



Neural network pruning techniques reduce the number of parameters without compromising predicting ability of a network. Many algorithms have been developed for pruning both over-parameterized fully-connected networks (FCNs) and convolutional neural networks (CNNs), but analytical studies of capabilities and compression ratios of such pruned sub-networks are lacking. We theoretically study the performance of two pruning techniques (random and magnitude-based) on FCNs and CNNs. Given a target network {whose weights are independently sampled from appropriate distributions}, we provide a universal approach to bound the gap between a pruned and the target network in a probabilistic sense. The results establish that there exist pruned networks with expressive power within any specified bound from the target network.
Complex Factoid Question Answering with a Free-Text Knowledge Graph
Mar 23, 2021



We introduce DELFT, a factoid question answering system which combines the nuance and depth of knowledge graph question answering approaches with the broader coverage of free-text. DELFT builds a free-text knowledge graph from Wikipedia, with entities as nodes and sentences in which entities co-occur as edges. For each question, DELFT finds the subgraph linking question entity nodes to candidates using text sentences as edges, creating a dense and high coverage semantic graph. A novel graph neural network reasons over the free-text graph-combining evidence on the nodes via information along edge sentences-to select a final answer. Experiments on three question answering datasets show DELFT can answer entity-rich questions better than machine reading based models, bert-based answer ranking and memory networks. DELFT's advantage comes from both the high coverage of its free-text knowledge graph-more than double that of dbpedia relations-and the novel graph neural network which reasons on the rich but noisy free-text evidence.
Personalized Visualization Recommendation
Feb 12, 2021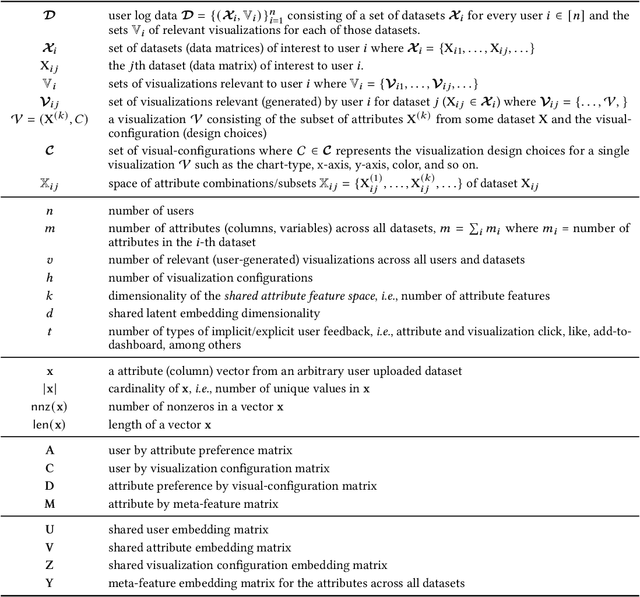
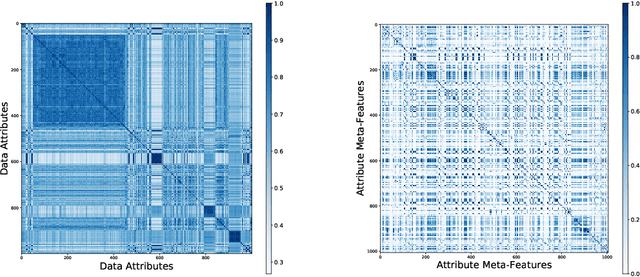

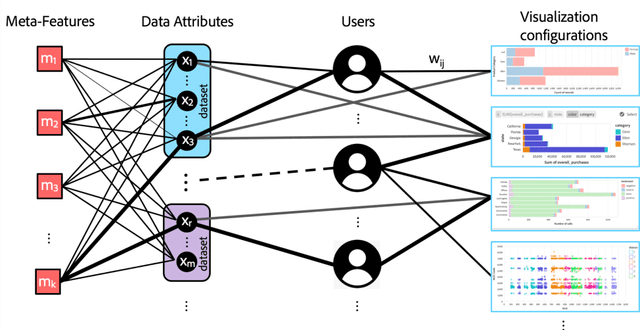
Visualization recommendation work has focused solely on scoring visualizations based on the underlying dataset and not the actual user and their past visualization feedback. These systems recommend the same visualizations for every user, despite that the underlying user interests, intent, and visualization preferences are likely to be fundamentally different, yet vitally important. In this work, we formally introduce the problem of personalized visualization recommendation and present a generic learning framework for solving it. In particular, we focus on recommending visualizations personalized for each individual user based on their past visualization interactions (e.g., viewed, clicked, manually created) along with the data from those visualizations. More importantly, the framework can learn from visualizations relevant to other users, even if the visualizations are generated from completely different datasets. Experiments demonstrate the effectiveness of the approach as it leads to higher quality visualization recommendations tailored to the specific user intent and preferences. To support research on this new problem, we release our user-centric visualization corpus consisting of 17.4k users exploring 94k datasets with 2.3 million attributes and 32k user-generated visualizations.
ML-based Visualization Recommendation: Learning to Recommend Visualizations from Data
Sep 25, 2020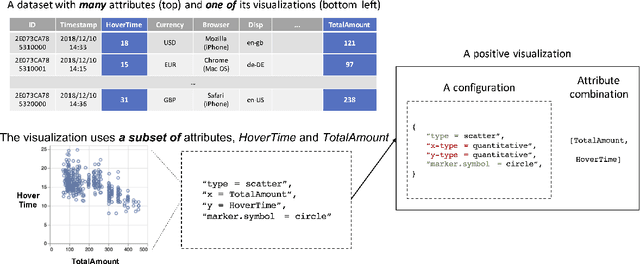

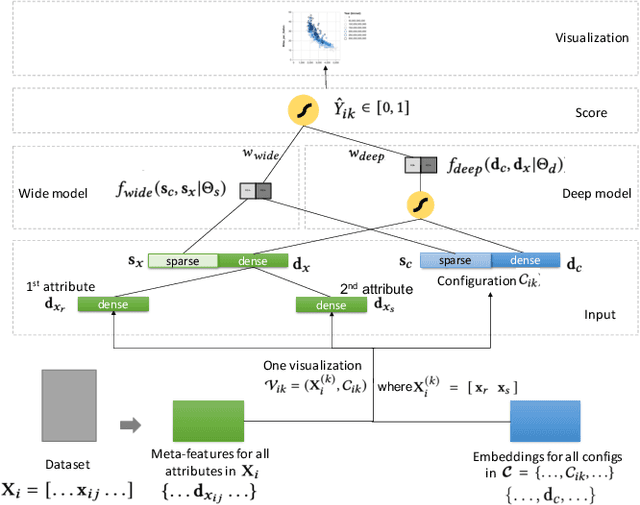
Visualization recommendation seeks to generate, score, and recommend to users useful visualizations automatically, and are fundamentally important for exploring and gaining insights into a new or existing dataset quickly. In this work, we propose the first end-to-end ML-based visualization recommendation system that takes as input a large corpus of datasets and visualizations, learns a model based on this data. Then, given a new unseen dataset from an arbitrary user, the model automatically generates visualizations for that new dataset, derive scores for the visualizations, and output a list of recommended visualizations to the user ordered by effectiveness. We also describe an evaluation framework to quantitatively evaluate visualization recommendation models learned from a large corpus of visualizations and datasets. Through quantitative experiments, a user study, and qualitative analysis, we show that our end-to-end ML-based system recommends more effective and useful visualizations compared to existing state-of-the-art rule-based systems. Finally, we observed a strong preference by the human experts in our user study towards the visualizations recommended by our ML-based system as opposed to the rule-based system (5.92 from a 7-point Likert scale compared to only 3.45).
The Impact of the Mini-batch Size on the Variance of Gradients in Stochastic Gradient Descent
Apr 27, 2020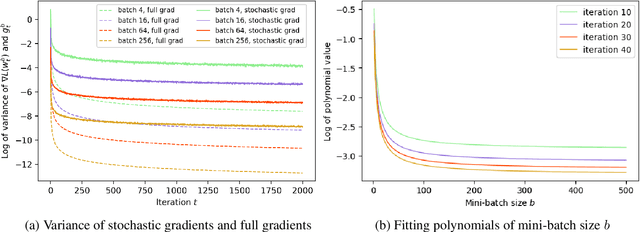



The mini-batch stochastic gradient descent (SGD) algorithm is widely used in training machine learning models, in particular deep learning models. We study SGD dynamics under linear regression and two-layer linear networks, with an easy extension to deeper linear networks, by focusing on the variance of the gradients, which is the first study of this nature. In the linear regression case, we show that in each iteration the norm of the gradient is a decreasing function of the mini-batch size $b$ and thus the variance of the stochastic gradient estimator is a decreasing function of $b$. For deep neural networks with $L_2$ loss we show that the variance of the gradient is a polynomial in $1/b$. The results back the important intuition that smaller batch sizes yield lower loss function values which is a common believe among the researchers. The proof techniques exhibit a relationship between stochastic gradient estimators and initial weights, which is useful for further research on the dynamics of SGD. We empirically provide further insights to our results on various datasets and commonly used deep network structures.
Clustering Degree-Corrected Stochastic Block Model with Outliers
Jun 07, 2019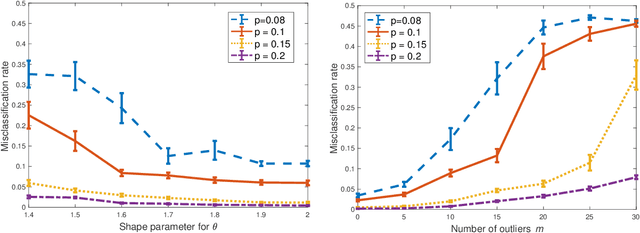
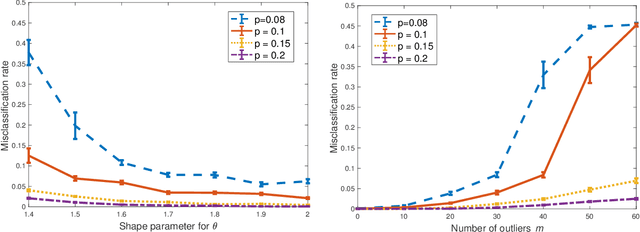
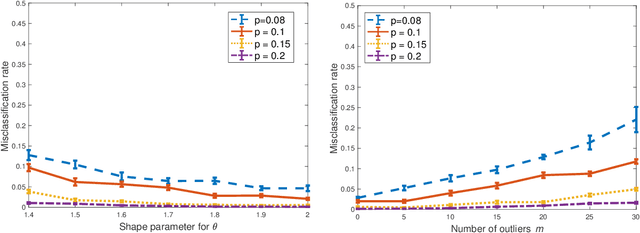
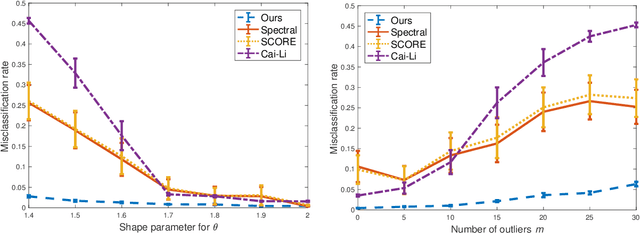
For the degree corrected stochastic block model in the presence of arbitrary or even adversarial outliers, we develop a convex-optimization-based clustering algorithm that includes a penalization term depending on the positive deviation of a node from the expected number of edges to other inliers. We prove that under mild conditions, this method achieves exact recovery of the underlying clusters. Our synthetic experiments show that our algorithm performs well on heterogeneous networks, and in particular those with Pareto degree distributions, for which outliers have a broad range of possible degrees that may enhance their adversarial power. We also demonstrate that our method allows for recovery with significantly lower error rates compared to existing algorithms.
Dynamic Cell Structure via Recursive-Recurrent Neural Networks
May 25, 2019
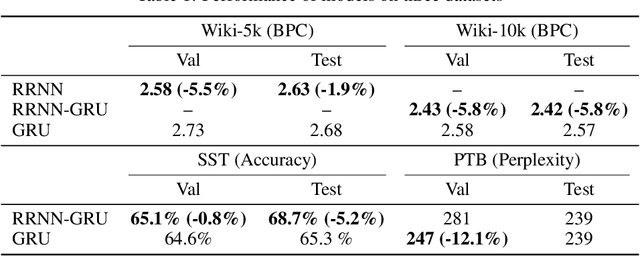
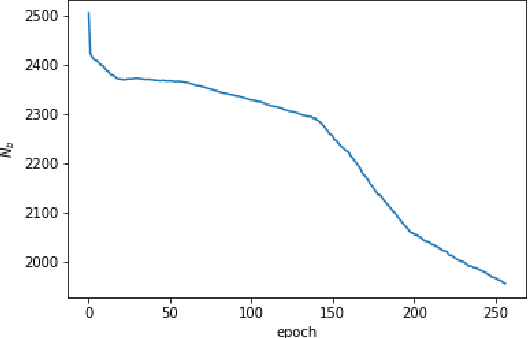

In a recurrent setting, conventional approaches to neural architecture search find and fix a general model for all data samples and time steps. We propose a novel algorithm that can dynamically search for the structure of cells in a recurrent neural network model. Based on a combination of recurrent and recursive neural networks, our algorithm is able to construct customized cell structures for each data sample and time step, allowing for a more efficient architecture search than existing models. Experiments on three common datasets show that the algorithm discovers high-performance cell architectures and achieves better prediction accuracy compared to the GRU structure for language modelling and sentiment analysis.