 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoTrace: Representing and Comparing Answering Strategies of Humans and LLMs in Information-Seeking Question Answering
Apr 16, 2026We introduce DiscoTrace, a method to identify the rhetorical strategies that answerers use when responding to information-seeking questions. DiscoTrace represents answers as a sequence of question-related discourse acts paired with interpretations of the original question, annotated on top of rhetorical structure theory parses. Applying DiscoTrace to answers from nine different human communities reveals that communities have diverse preferences for answer construction. In contrast, LLMs do not exhibit rhetorical diversity in their answers, even when prompted to mimic specific human community answering guidelines. LLMs also systematically opt for breadth, addressing interpretations of questions that human answerers choose not to address. Our findings can guide the development of pragmatic LLM answerers that consider a range of strategies informed by context in QA.
CANVAS: Continuity-Aware Narratives via Visual Agentic Storyboarding
Apr 15, 2026Long-form visual storytelling requires maintaining continuity across shots, including consistent characters, stable environments, and smooth scene transitions. While existing generative models can produce strong individual frames, they fail to preserve such continuity, leading to appearance changes, inconsistent backgrounds, and abrupt scene shifts. We introduce CANVAS (Continuity-Aware Narratives via Visual Agentic Storyboarding), a multi-agent framework that explicitly plans visual continuity in multi-shot narratives. CANVAS enforces coherence through character continuity, persistent background anchors, and location-aware scene planning for smooth transitions within the same setting We evaluate CANVAS on two storyboard generation benchmarks ST-BENCH and ViStoryBench and introduce a new challenging benchmark HardContinuityBench for long-range narrative consistency. CANVAS consistently outperforms the best-performing baseline, improving background continuity by 21.6%, character consistency by 9.6% and props consistency by 7.6%.
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Aug 27, 2025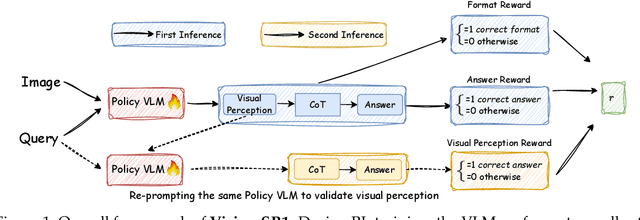
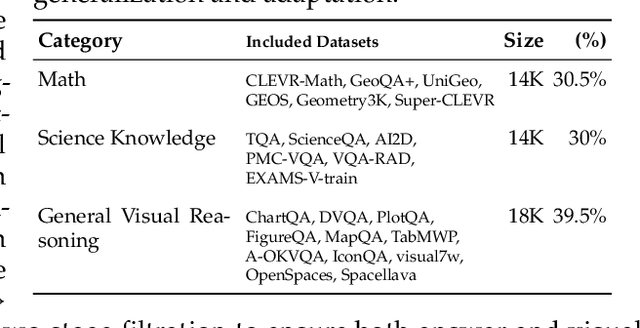
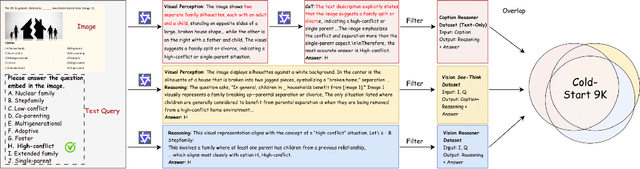
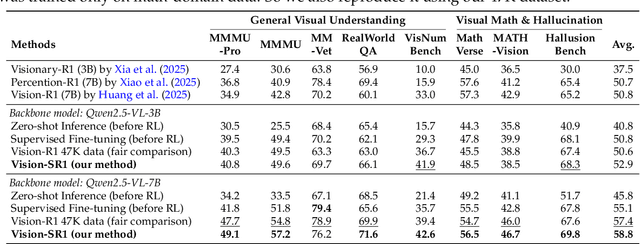
Vision-Language Models (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Jul 01, 2025Topic model and document-clustering evaluations either use automated metrics that align poorly with human preferences or require expert labels that are intractable to scale. We design a scalable human evaluation protocol and a corresponding automated approximation that reflect practitioners' real-world usage of models. Annotators -- or an LLM-based proxy -- review text items assigned to a topic or cluster, infer a category for the group, then apply that category to other documents. Using this protocol, we collect extensive crowdworker annotations of outputs from a diverse set of topic models on two datasets. We then use these annotations to validate automated proxies, finding that the best LLM proxies are statistically indistinguishable from a human annotator and can therefore serve as a reasonable substitute in automated evaluations. Package, web interface, and data are at https://github.com/ahoho/proxann
NAVIG: Natural Language-guided Analysis with Vision Language Models for Image Geo-localization
Feb 20, 2025Image geo-localization is the task of predicting the specific location of an image and requires complex reasoning across visual, geographical, and cultural contexts. While prior Vision Language Models (VLMs) have the best accuracy at this task, there is a dearth of high-quality datasets and models for analytical reasoning. We first create NaviClues, a high-quality dataset derived from GeoGuessr, a popular geography game, to supply examples of expert reasoning from language. Using this dataset, we present Navig, a comprehensive image geo-localization framework integrating global and fine-grained image information. By reasoning with language, Navig reduces the average distance error by 14% compared to previous state-of-the-art models while requiring fewer than 1000 training samples. Our dataset and code are available at https://github.com/SparrowZheyuan18/Navig/.
Large Language Models Struggle to Describe the Haystack without Human Help: Human-in-the-loop Evaluation of LLMs
Feb 20, 2025A common use of NLP is to facilitate the understanding of large document collections, with a shift from using traditional topic models to Large Language Models. Yet the effectiveness of using LLM for large corpus understanding in real-world applications remains under-explored. This study measures the knowledge users acquire with unsupervised, supervised LLM-based exploratory approaches or traditional topic models on two datasets. While LLM-based methods generate more human-readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to the LLM generation process improves data exploration by mitigating hallucination and over-genericity but requires greater human effort. In contrast, traditional. models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. We show that LLMs struggle to describe the haystack of large corpora without human help, particularly domain-specific data, and face scaling and hallucination limitations due to context length constraints. Dataset available at https://huggingface. co/datasets/zli12321/Bills.
Reverse Question Answering: Can an LLM Write a Question so Hard (or Bad) that it Can't Answer?
Oct 20, 2024Question answering (QA)-producing correct answers for input questions-is popular, but we test a reverse question answering (RQA) task: given an input answer, generate a question with that answer. Past work tests QA and RQA separately, but we test them jointly, comparing their difficulty, aiding benchmark design, and assessing reasoning consistency. 16 LLMs run QA and RQA with trivia questions/answers, showing: 1) Versus QA, LLMs are much less accurate in RQA for numerical answers, but slightly more accurate in RQA for textual answers; 2) LLMs often answer their own invalid questions from RQA accurately in QA, so RQA errors are not from knowledge gaps alone; 3) RQA errors correlate with question difficulty and inversely correlate with answer frequencies in the Dolma corpus; and 4) LLMs struggle to give valid multi-hop questions. By finding question and answer types yielding RQA errors, we suggest improvements for LLM RQA reasoning.
Do great minds think alike? Investigating Human-AI Complementarity in Question Answering with CAIMIRA
Oct 09, 2024



Recent advancements of large language models (LLMs) have led to claims of AI surpassing humans in natural language processing (NLP) tasks such as textual understanding and reasoning. This work investigates these assertions by introducing CAIMIRA, a novel framework rooted in item response theory (IRT) that enables quantitative assessment and comparison of problem-solving abilities of question-answering (QA) agents: humans and AI systems. Through analysis of over 300,000 responses from ~70 AI systems and 155 humans across thousands of quiz questions, CAIMIRA uncovers distinct proficiency patterns in knowledge domains and reasoning skills. Humans outperform AI systems in knowledge-grounded abductive and conceptual reasoning, while state-of-the-art LLMs like GPT-4 and LLaMA show superior performance on targeted information retrieval and fact-based reasoning, particularly when information gaps are well-defined and addressable through pattern matching or data retrieval. These findings highlight the need for future QA tasks to focus on questions that challenge not only higher-order reasoning and scientific thinking, but also demand nuanced linguistic interpretation and cross-contextual knowledge application, helping advance AI developments that better emulate or complement human cognitive abilities in real-world problem-solving.
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Sep 28, 2024Automating the creation of scientific diagrams from academic papers can significantly streamline the development of tutorials, presentations, and posters, thereby saving time and accelerating the process. Current text-to-image models struggle with generating accurate and visually appealing diagrams from long-context inputs. We propose SciDoc2Diagram, a task that extracts relevant information from scientific papers and generates diagrams, along with a benchmarking dataset, SciDoc2DiagramBench. We develop a multi-step pipeline SciDoc2Diagrammer that generates diagrams based on user intentions using intermediate code generation. We observed that initial diagram drafts were often incomplete or unfaithful to the source, leading us to develop SciDoc2Diagrammer-Multi-Aspect-Feedback (MAF), a refinement strategy that significantly enhances factual correctness and visual appeal and outperforms existing models on both automatic and human judgement.
* Code and data available at https://github.com/Ishani-Mondal/SciDoc2DiagramGeneration
A SMART Mnemonic Sounds like "Glue Tonic": Mixing LLMs with Student Feedback to Make Mnemonic Learning Stick
Jun 21, 2024Keyword mnemonics are memorable explanations that link new terms to simpler keywords. Prior works generate mnemonics for students, but they do not guide models toward mnemonics students prefer and aid learning. We build SMART, a mnemonic generator trained on feedback from real students learning new terms. To train SMART, we first fine-tune LLaMA-2 on a curated set of user-written mnemonics. We then use LLM alignment to enhance SMART: we deploy mnemonics generated by SMART in a flashcard app to find preferences on mnemonics students favor. We gather 2684 preferences from 45 students across two types: expressed (inferred from ratings) and observed (inferred from student learning), yielding three key findings. First, expressed and observed preferences disagree; what students think is helpful does not fully capture what is truly helpful. Second, Bayesian models can synthesize complementary data from multiple preference types into a single effectiveness signal. SMART is tuned via Direct Preference Optimization on this signal, which we show resolves ties and missing labels in the typical method of pairwise comparisons, augmenting data for LLM output quality gains. Third, mnemonic experts assess SMART as matching GPT-4, at much lower deployment costs, showing the utility of capturing diverse student feedback to align LLMs in education.