 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalCore: A Dataset for Legal Documents Event Coreference Resolution
Feb 18, 2025Recognizing events and their coreferential mentions in a document is essential for understanding semantic meanings of text. The existing research on event coreference resolution is mostly limited to news articles. In this paper, we present the first dataset for the legal domain, LegalCore, which has been annotated with comprehensive event and event coreference information. The legal contract documents we annotated in this dataset are several times longer than news articles, with an average length of around 25k tokens per document. The annotations show that legal documents have dense event mentions and feature both short-distance and super long-distance coreference links between event mentions. We further benchmark mainstream Large Language Models (LLMs) on this dataset for both event detection and event coreference resolution tasks, and find that this dataset poses significant challenges for state-of-the-art open-source and proprietary LLMs, which perform significantly worse than a supervised baseline. We will publish the dataset as well as the code.
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Sep 28, 2024Automating the creation of scientific diagrams from academic papers can significantly streamline the development of tutorials, presentations, and posters, thereby saving time and accelerating the process. Current text-to-image models struggle with generating accurate and visually appealing diagrams from long-context inputs. We propose SciDoc2Diagram, a task that extracts relevant information from scientific papers and generates diagrams, along with a benchmarking dataset, SciDoc2DiagramBench. We develop a multi-step pipeline SciDoc2Diagrammer that generates diagrams based on user intentions using intermediate code generation. We observed that initial diagram drafts were often incomplete or unfaithful to the source, leading us to develop SciDoc2Diagrammer-Multi-Aspect-Feedback (MAF), a refinement strategy that significantly enhances factual correctness and visual appeal and outperforms existing models on both automatic and human judgement.
* Code and data available at https://github.com/Ishani-Mondal/SciDoc2DiagramGeneration
Enhancing Presentation Slide Generation by LLMs with a Multi-Staged End-to-End Approach
Jun 01, 2024Generating presentation slides from a long document with multimodal elements such as text and images is an important task. This is time consuming and needs domain expertise if done manually. Existing approaches for generating a rich presentation from a document are often semi-automatic or only put a flat summary into the slides ignoring the importance of a good narrative. In this paper, we address this research gap by proposing a multi-staged end-to-end model which uses a combination of LLM and VLM. We have experimentally shown that compared to applying LLMs directly with state-of-the-art prompting, our proposed multi-staged solution is better in terms of automated metrics and human evaluation.
Presentations are not always linear! GNN meets LLM for Document-to-Presentation Transformation with Attribution
May 21, 2024Automatically generating a presentation from the text of a long document is a challenging and useful problem. In contrast to a flat summary, a presentation needs to have a better and non-linear narrative, i.e., the content of a slide can come from different and non-contiguous parts of the given document. However, it is difficult to incorporate such non-linear mapping of content to slides and ensure that the content is faithful to the document. LLMs are prone to hallucination and their performance degrades with the length of the input document. Towards this, we propose a novel graph based solution where we learn a graph from the input document and use a combination of graph neural network and LLM to generate a presentation with attribution of content for each slide. We conduct thorough experiments to show the merit of our approach compared to directly using LLMs for this task.
Knowledge-Aware Neural Networks for Medical Forum Question Classification
Sep 27, 2021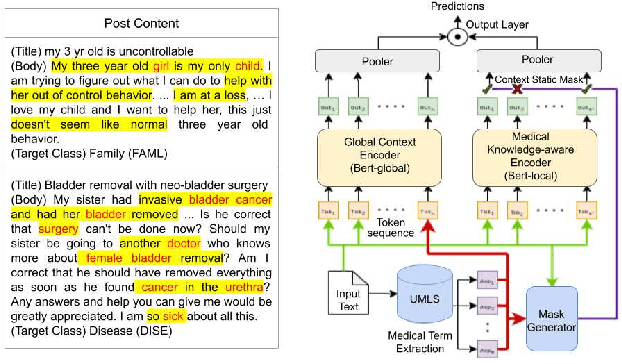
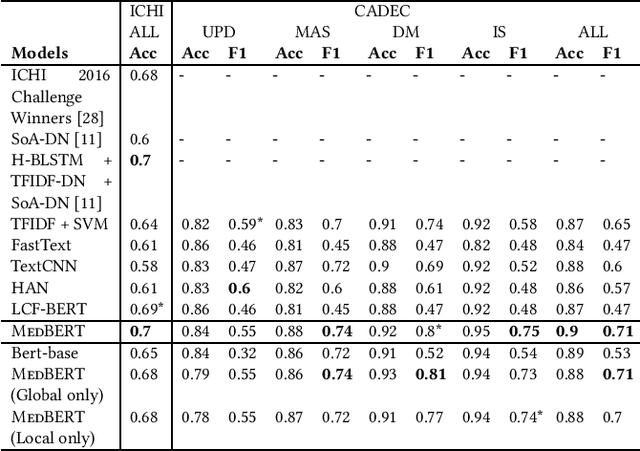
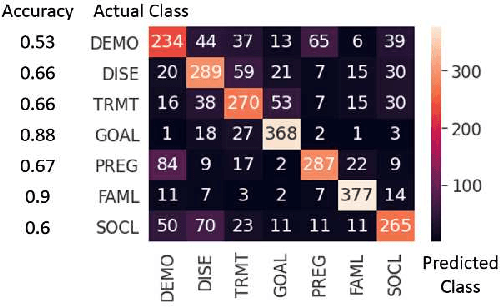
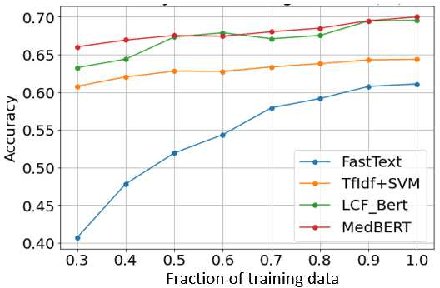
Online medical forums have become a predominant platform for answering health-related information needs of consumers. However, with a significant rise in the number of queries and the limited availability of experts, it is necessary to automatically classify medical queries based on a consumer's intention, so that these questions may be directed to the right set of medical experts. Here, we develop a novel medical knowledge-aware BERT-based model (MedBERT) that explicitly gives more weightage to medical concept-bearing words, and utilize domain-specific side information obtained from a popular medical knowledge base. We also contribute a multi-label dataset for the Medical Forum Question Classification (MFQC) task. MedBERT achieves state-of-the-art performance on two benchmark datasets and performs very well in low resource settings.
An Integrated Approach for Improving Brand Consistency of Web Content: Modeling, Analysis and Recommendation
Nov 20, 2020
A consumer-dependent (business-to-consumer) organization tends to present itself as possessing a set of human qualities, which is termed as the brand personality of the company. The perception is impressed upon the consumer through the content, be it in the form of advertisement, blogs or magazines, produced by the organization. A consistent brand will generate trust and retain customers over time as they develop an affinity towards regularity and common patterns. However, maintaining a consistent messaging tone for a brand has become more challenging with the virtual explosion in the amount of content which needs to be authored and pushed to the Internet to maintain an edge in the era of digital marketing. To understand the depth of the problem, we collect around 300K web page content from around 650 companies. We develop trait-specific classification models by considering the linguistic features of the content. The classifier automatically identifies the web articles which are not consistent with the mission and vision of a company and further helps us to discover the conditions under which the consistency cannot be maintained. To address the brand inconsistency issue, we then develop a sentence ranking system that outputs the top three sentences that need to be changed for making a web article more consistent with the company's brand personality.
Reinforced Rewards Framework for Text Style Transfer
May 11, 2020
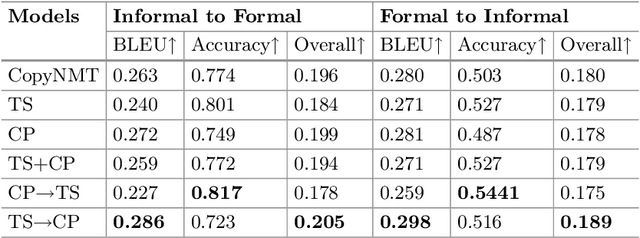
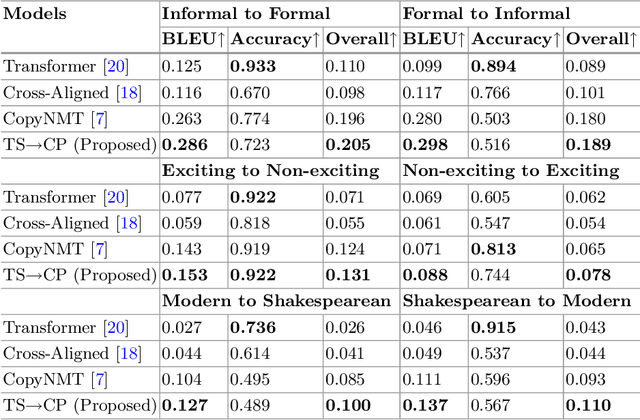
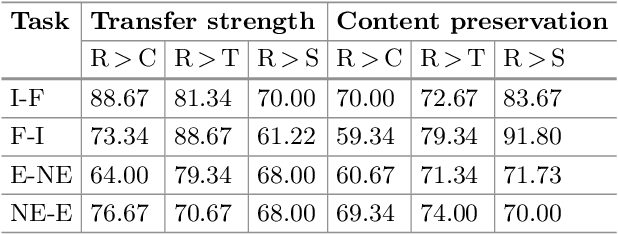
Style transfer deals with the algorithms to transfer the stylistic properties of a piece of text into that of another while ensuring that the core content is preserved. There has been a lot of interest in the field of text style transfer due to its wide application to tailored text generation. Existing works evaluate the style transfer models based on content preservation and transfer strength. In this work, we propose a reinforcement learning based framework that directly rewards the framework on these target metrics yielding a better transfer of the target style. We show the improved performance of our proposed framework based on automatic and human evaluation on three independent tasks: wherein we transfer the style of text from formal to informal, high excitement to low excitement, modern English to Shakespearean English, and vice-versa in all the three cases. Improved performance of the proposed framework over existing state-of-the-art frameworks indicates the viability of the approach.