 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning for modelling unstructured grid data in computational physics: a review
Feb 13, 2025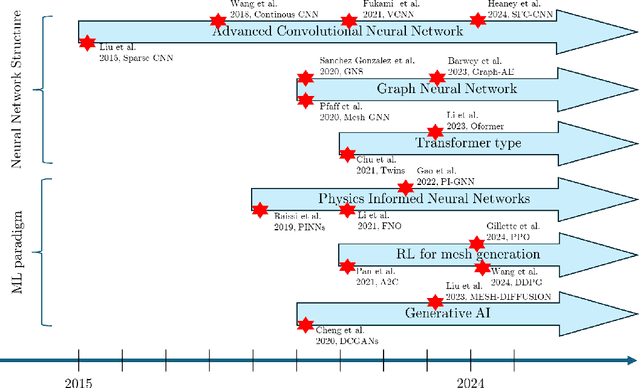
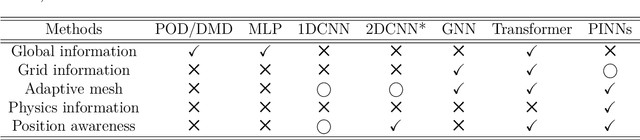
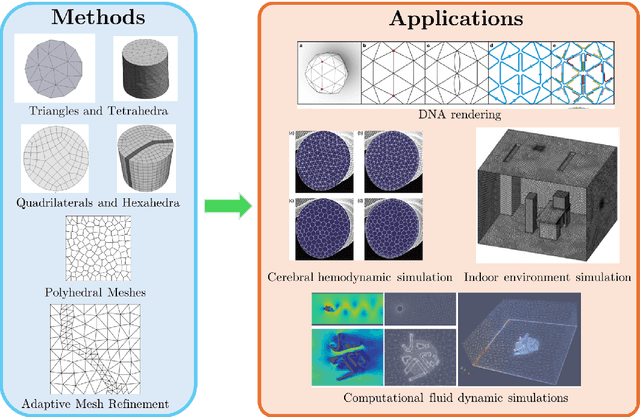

Unstructured grid data are essential for modelling complex geometries and dynamics in computational physics. Yet, their inherent irregularity presents significant challenges for conventional machine learning (ML) techniques. This paper provides a comprehensive review of advanced ML methodologies designed to handle unstructured grid data in high-dimensional dynamical systems. Key approaches discussed include graph neural networks, transformer models with spatial attention mechanisms, interpolation-integrated ML methods, and meshless techniques such as physics-informed neural networks. These methodologies have proven effective across diverse fields, including fluid dynamics and environmental simulations. This review is intended as a guidebook for computational scientists seeking to apply ML approaches to unstructured grid data in their domains, as well as for ML researchers looking to address challenges in computational physics. It places special focus on how ML methods can overcome the inherent limitations of traditional numerical techniques and, conversely, how insights from computational physics can inform ML development. To support benchmarking, this review also provides a summary of open-access datasets of unstructured grid data in computational physics. Finally, emerging directions such as generative models with unstructured data, reinforcement learning for mesh generation, and hybrid physics-data-driven paradigms are discussed to inspire future advancements in this evolving field.
ClimateLearn: Benchmarking Machine Learning for Weather and Climate Modeling
Jul 04, 2023


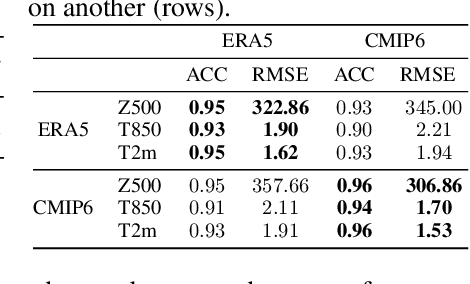
Modeling weather and climate is an essential endeavor to understand the near- and long-term impacts of climate change, as well as inform technology and policymaking for adaptation and mitigation efforts. In recent years, there has been a surging interest in applying data-driven methods based on machine learning for solving core problems such as weather forecasting and climate downscaling. Despite promising results, much of this progress has been impaired due to the lack of large-scale, open-source efforts for reproducibility, resulting in the use of inconsistent or underspecified datasets, training setups, and evaluations by both domain scientists and artificial intelligence researchers. We introduce ClimateLearn, an open-source PyTorch library that vastly simplifies the training and evaluation of machine learning models for data-driven climate science. ClimateLearn consists of holistic pipelines for dataset processing (e.g., ERA5, CMIP6, PRISM), implementation of state-of-the-art deep learning models (e.g., Transformers, ResNets), and quantitative and qualitative evaluation for standard weather and climate modeling tasks. We supplement these functionalities with extensive documentation, contribution guides, and quickstart tutorials to expand access and promote community growth. We have also performed comprehensive forecasting and downscaling experiments to showcase the capabilities and key features of our library. To our knowledge, ClimateLearn is the first large-scale, open-source effort for bridging research in weather and climate modeling with modern machine learning systems. Our library is available publicly at https://github.com/aditya-grover/climate-learn.
Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment
Apr 06, 2022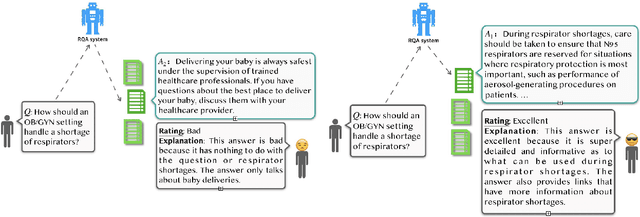
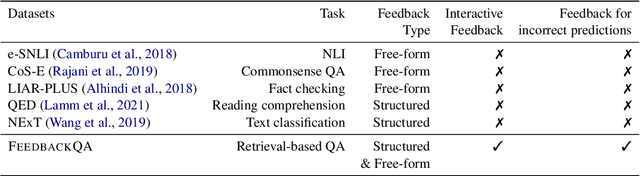
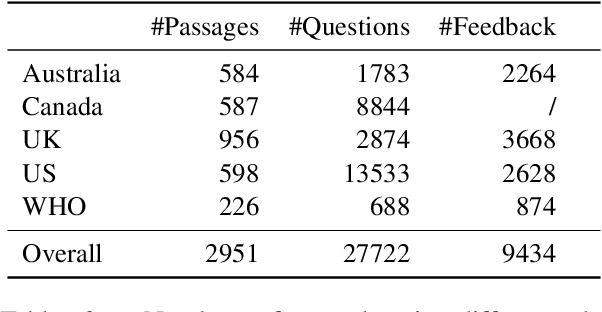
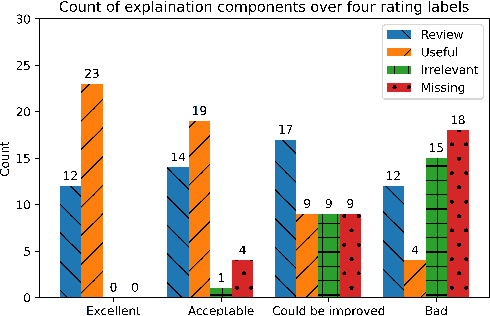
Most research on question answering focuses on the pre-deployment stage; i.e., building an accurate model for deployment. In this paper, we ask the question: Can we improve QA systems further \emph{post-}deployment based on user interactions? We focus on two kinds of improvements: 1) improving the QA system's performance itself, and 2) providing the model with the ability to explain the correctness or incorrectness of an answer. We collect a retrieval-based QA dataset, FeedbackQA, which contains interactive feedback from users. We collect this dataset by deploying a base QA system to crowdworkers who then engage with the system and provide feedback on the quality of its answers. The feedback contains both structured ratings and unstructured natural language explanations. We train a neural model with this feedback data that can generate explanations and re-score answer candidates. We show that feedback data not only improves the accuracy of the deployed QA system but also other stronger non-deployed systems. The generated explanations also help users make informed decisions about the correctness of answers. Project page: https://mcgill-nlp.github.io/feedbackqa/
Knowledge-Aware Neural Networks for Medical Forum Question Classification
Sep 27, 2021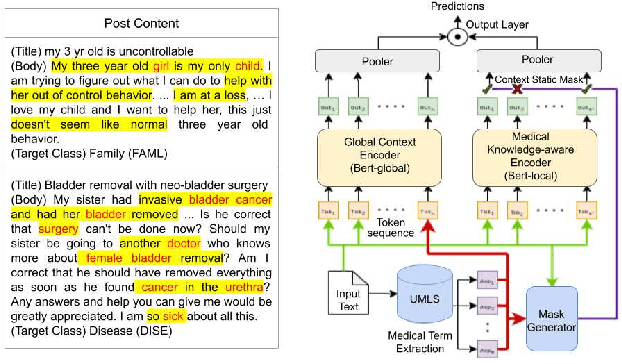
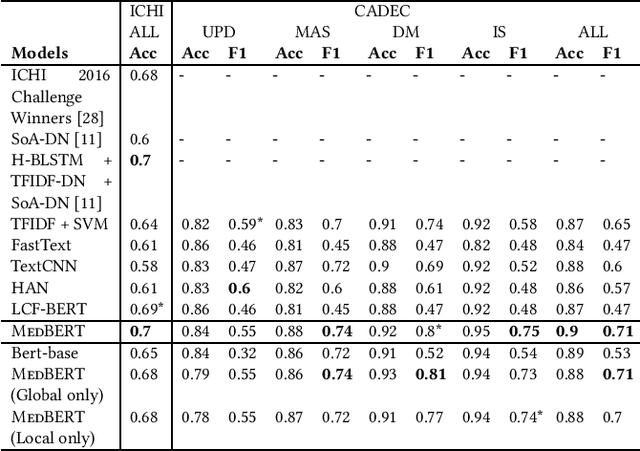
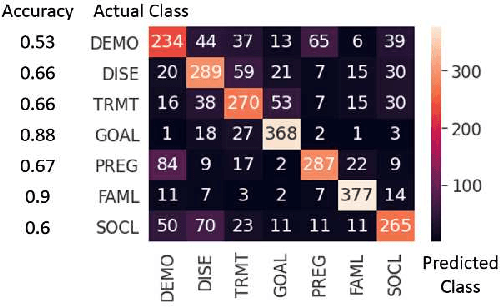
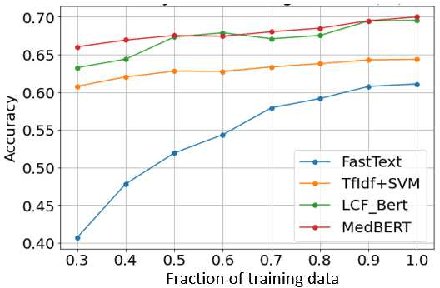
Online medical forums have become a predominant platform for answering health-related information needs of consumers. However, with a significant rise in the number of queries and the limited availability of experts, it is necessary to automatically classify medical queries based on a consumer's intention, so that these questions may be directed to the right set of medical experts. Here, we develop a novel medical knowledge-aware BERT-based model (MedBERT) that explicitly gives more weightage to medical concept-bearing words, and utilize domain-specific side information obtained from a popular medical knowledge base. We also contribute a multi-label dataset for the Medical Forum Question Classification (MFQC) task. MedBERT achieves state-of-the-art performance on two benchmark datasets and performs very well in low resource settings.
Scalable Microservice Forensics and Stability Assessment Using Variational Autoencoders
Apr 23, 2021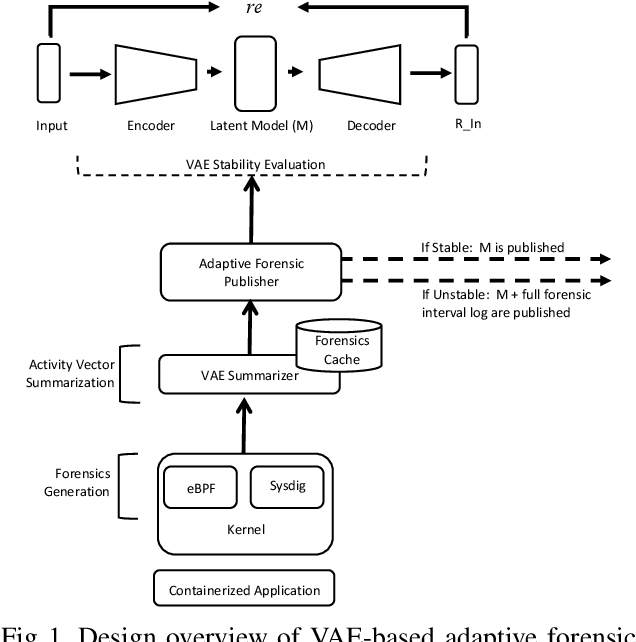
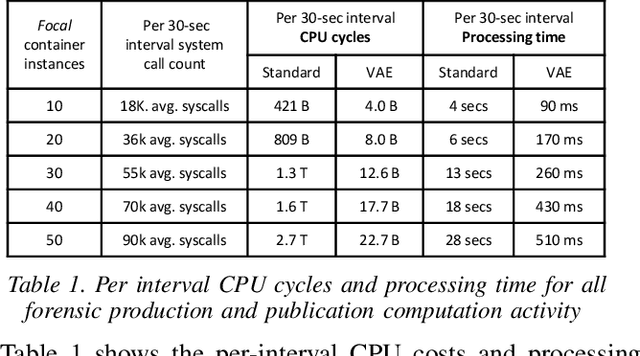
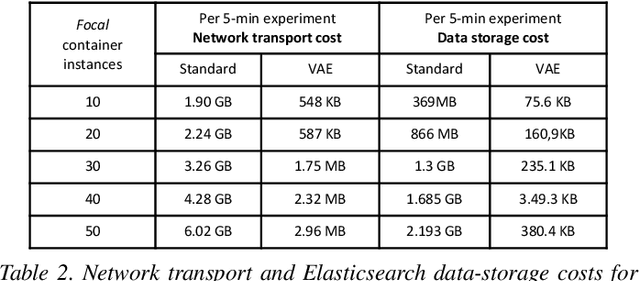
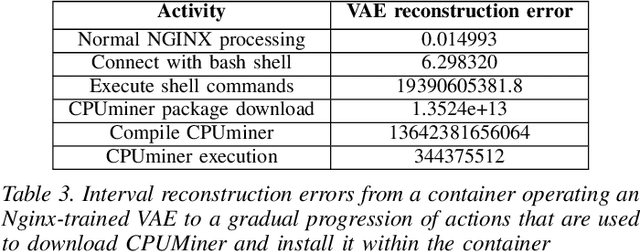
We present a deep learning based approach to containerized application runtime stability analysis, and an intelligent publishing algorithm that can dynamically adjust the depth of process-level forensics published to a backend incident analysis repository. The approach applies variational autoencoders (VAEs) to learn the stable runtime patterns of container images, and then instantiates these container-specific VAEs to implement stability detection and adaptive forensics publishing. In performance comparisons using a 50-instance container workload, a VAE-optimized service versus a conventional eBPF-based forensic publisher demonstrates 2 orders of magnitude (OM) CPU performance improvement, a 3 OM reduction in network transport volume, and a 4 OM reduction in Elasticsearch storage costs. We evaluate the VAE-based stability detection technique against two attacks, CPUMiner and HTTP-flood attack, finding that it is effective in isolating both anomalies. We believe this technique provides a novel approach to integrating fine-grained process monitoring and digital-forensic services into large container ecosystems that today simply cannot be monitored by conventional techniques
Exploring Effects of Random Walk Based Minibatch Selection Policy on Knowledge Graph Completion
Apr 12, 2020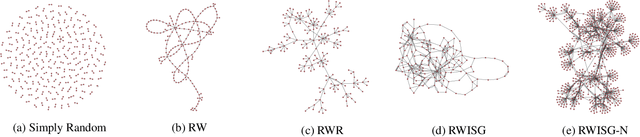
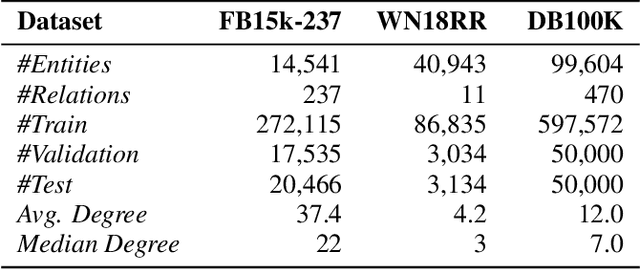
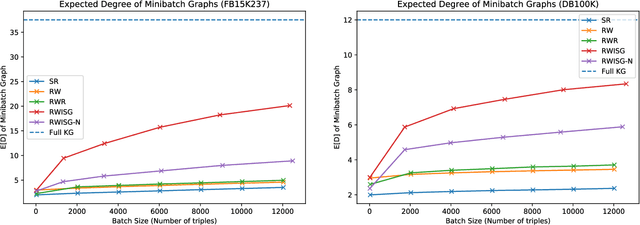
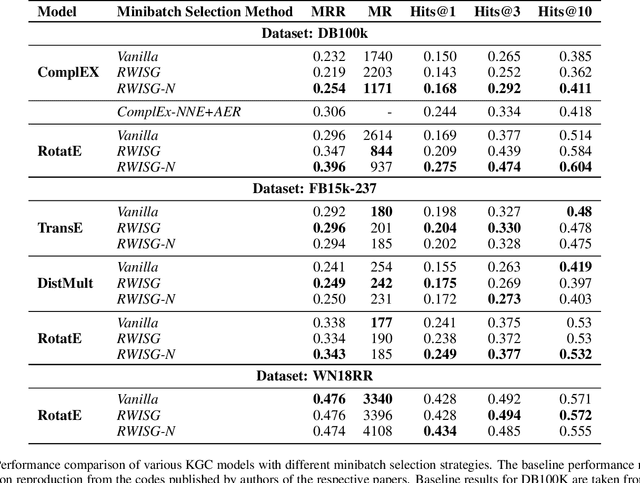
In this paper, we have explored the effects of different minibatch sampling techniques in Knowledge Graph Completion. Knowledge Graph Completion (KGC) or Link Prediction is the task of predicting missing facts in a knowledge graph. KGC models are usually trained using margin, soft-margin or cross-entropy loss function that promotes assigning a higher score or probability for true fact triplets. Minibatch gradient descent is used to optimize these loss functions for training the KGC models. But, as each minibatch consists of only a few randomly sampled triplets from a large knowledge graph, any entity that occurs in a minibatch, occurs only once in most cases. Because of this, these loss functions ignore all other neighbors of any entity, whose embedding is being updated at some minibatch step. In this paper, we propose a new random-walk based minibatch sampling technique for training KGC models that optimizes the loss incurred by a minibatch of closely connected subgraph of triplets instead of randomly selected ones. We have shown results of experiments for different models and datasets with our sampling technique and found that the proposed sampling algorithm has varying effects on these datasets/models. Specifically, we find that our proposed method achieves state-of-the-art performance on the DB100K dataset.
Entity Personalized Talent Search Models with Tree Interaction Features
Feb 25, 2019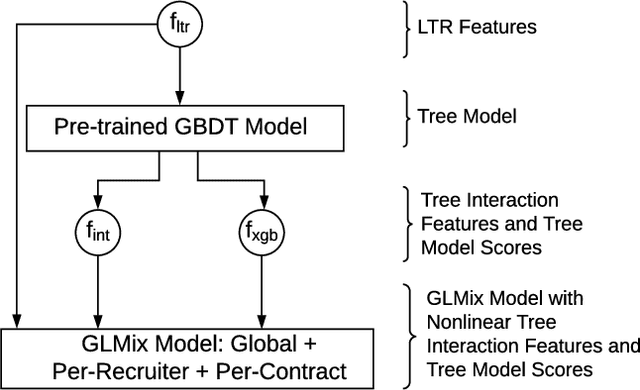

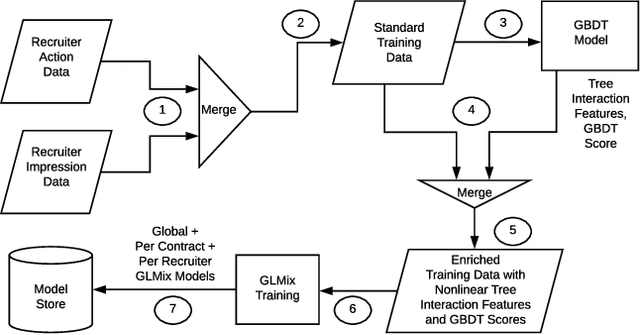
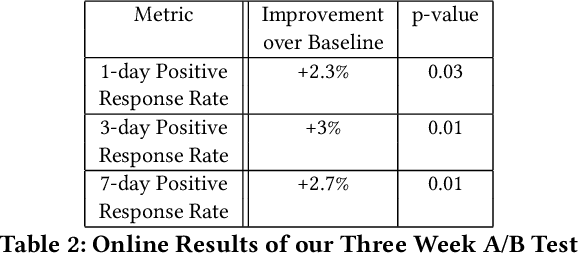
Talent Search systems aim to recommend potential candidates who are a good match to the hiring needs of a recruiter expressed in terms of the recruiter's search query or job posting. Past work in this domain has focused on linear and nonlinear models which lack preference personalization in the user-level due to being trained only with globally collected recruiter activity data. In this paper, we propose an entity-personalized Talent Search model which utilizes a combination of generalized linear mixed (GLMix) models and gradient boosted decision tree (GBDT) models, and provides personalized talent recommendations using nonlinear tree interaction features generated by the GBDT. We also present the offline and online system architecture for the productionization of this hybrid model approach in our Talent Search systems. Finally, we provide offline and online experiment results benchmarking our entity-personalized model with tree interaction features, which demonstrate significant improvements in our precision metrics compared to globally trained non-personalized models.