 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
What's in a Name? Reducing Bias in Bios without Access to Protected Attributes
Apr 10, 2019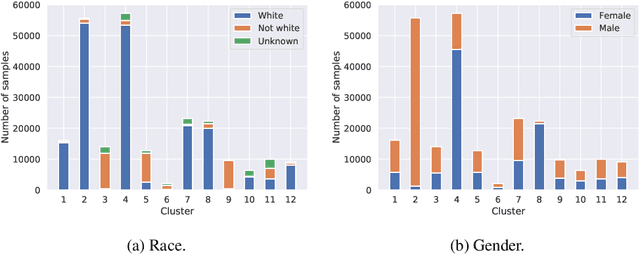
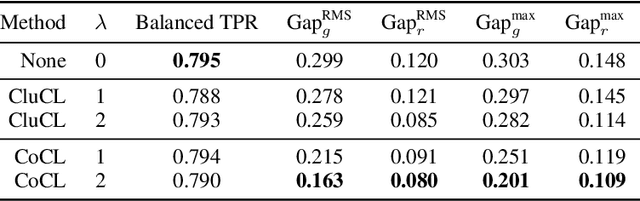
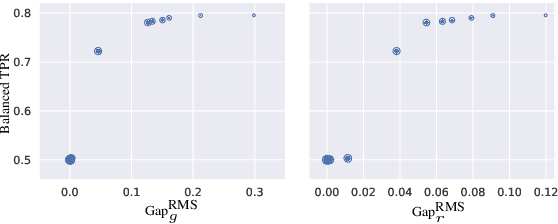
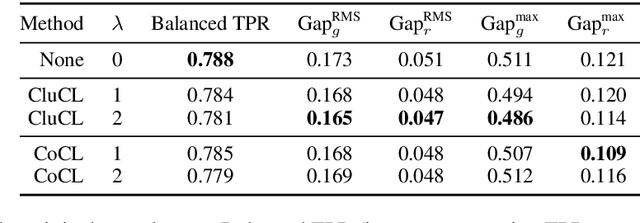
There is a growing body of work that proposes methods for mitigating bias in machine learning systems. These methods typically rely on access to protected attributes such as race, gender, or age. However, this raises two significant challenges: (1) protected attributes may not be available or it may not be legal to use them, and (2) it is often desirable to simultaneously consider multiple protected attributes, as well as their intersections. In the context of mitigating bias in occupation classification, we propose a method for discouraging correlation between the predicted probability of an individual's true occupation and a word embedding of their name. This method leverages the societal biases that are encoded in word embeddings, eliminating the need for access to protected attributes. Crucially, it only requires access to individuals' names at training time and not at deployment time. We evaluate two variations of our proposed method using a large-scale dataset of online biographies. We find that both variations simultaneously reduce race and gender biases, with almost no reduction in the classifier's overall true positive rate.
Entity Personalized Talent Search Models with Tree Interaction Features
Feb 25, 2019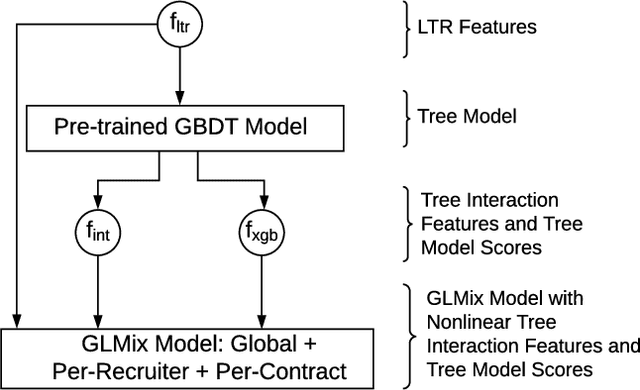

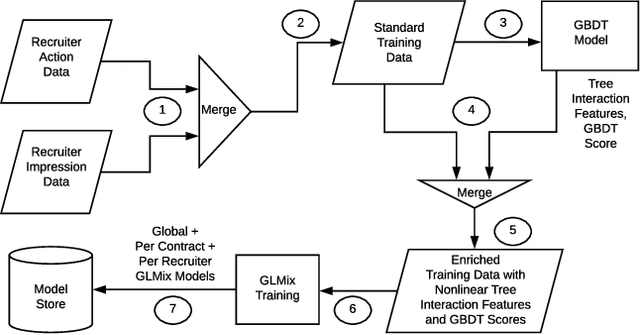
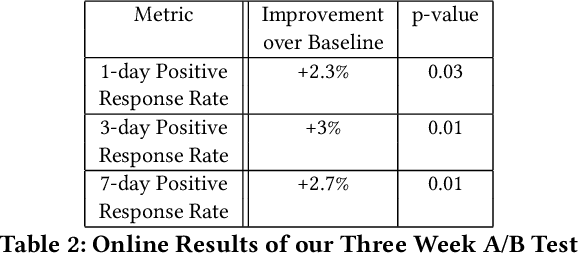
Talent Search systems aim to recommend potential candidates who are a good match to the hiring needs of a recruiter expressed in terms of the recruiter's search query or job posting. Past work in this domain has focused on linear and nonlinear models which lack preference personalization in the user-level due to being trained only with globally collected recruiter activity data. In this paper, we propose an entity-personalized Talent Search model which utilizes a combination of generalized linear mixed (GLMix) models and gradient boosted decision tree (GBDT) models, and provides personalized talent recommendations using nonlinear tree interaction features generated by the GBDT. We also present the offline and online system architecture for the productionization of this hybrid model approach in our Talent Search systems. Finally, we provide offline and online experiment results benchmarking our entity-personalized model with tree interaction features, which demonstrate significant improvements in our precision metrics compared to globally trained non-personalized models.
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
Jan 27, 2019
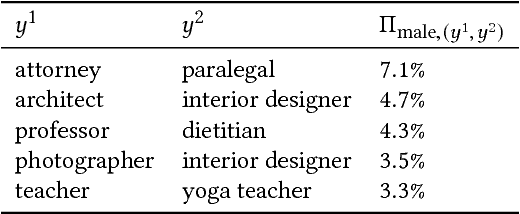
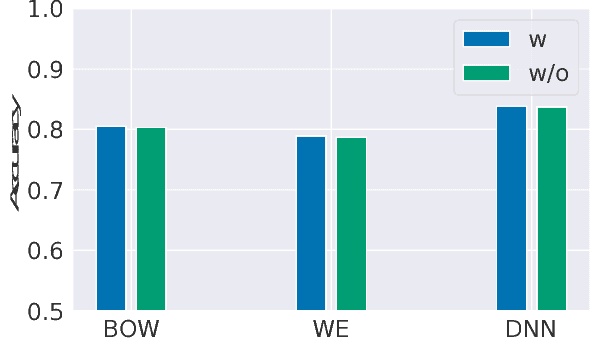

We present a large-scale study of gender bias in occupation classification, a task where the use of machine learning may lead to negative outcomes on peoples' lives. We analyze the potential allocation harms that can result from semantic representation bias. To do so, we study the impact on occupation classification of including explicit gender indicators---such as first names and pronouns---in different semantic representations of online biographies. Additionally, we quantify the bias that remains when these indicators are "scrubbed," and describe proxy behavior that occurs in the absence of explicit gender indicators. As we demonstrate, differences in true positive rates between genders are correlated with existing gender imbalances in occupations, which may compound these imbalances.