 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Approach That Beats Large Rubik's Cubes
Feb 18, 2025


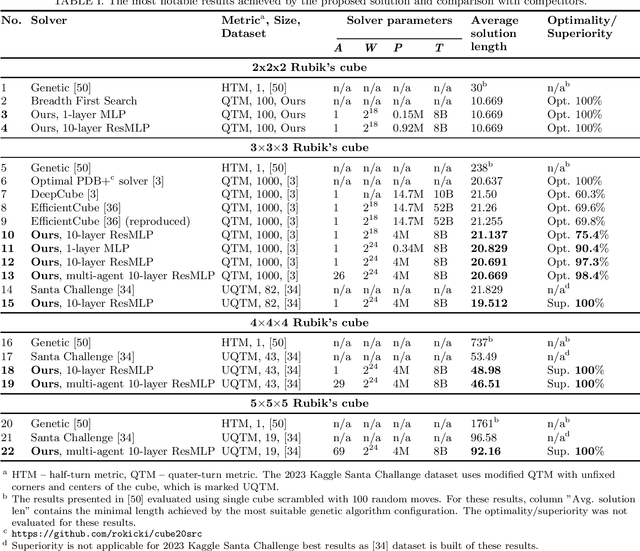
The paper proposes a novel machine learning-based approach to the pathfinding problem on extremely large graphs. This method leverages diffusion distance estimation via a neural network and uses beam search for pathfinding. We demonstrate its efficiency by finding solutions for 4x4x4 and 5x5x5 Rubik's cubes with unprecedentedly short solution lengths, outperforming all available solvers and introducing the first machine learning solver beyond the 3x3x3 case. In particular, it surpasses every single case of the combined best results in the Kaggle Santa 2023 challenge, which involved over 1,000 teams. For the 3x3x3 Rubik's cube, our approach achieves an optimality rate exceeding 98%, matching the performance of task-specific solvers and significantly outperforming prior solutions such as DeepCubeA (60.3%) and EfficientCube (69.6%). Additionally, our solution is more than 26 times faster in solving 3x3x3 Rubik's cubes while requiring up to 18.5 times less model training time than the most efficient state-of-the-art competitor.
Lights, Camera, Action! A Framework to Improve NLP Accuracy over OCR documents
Aug 06, 2021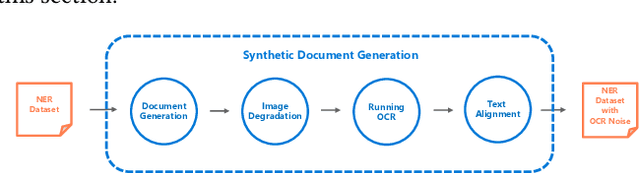
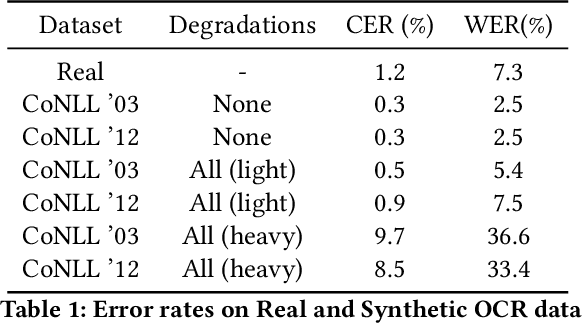
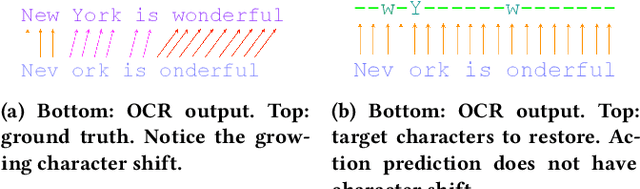

Document digitization is essential for the digital transformation of our societies, yet a crucial step in the process, Optical Character Recognition (OCR), is still not perfect. Even commercial OCR systems can produce questionable output depending on the fidelity of the scanned documents. In this paper, we demonstrate an effective framework for mitigating OCR errors for any downstream NLP task, using Named Entity Recognition (NER) as an example. We first address the data scarcity problem for model training by constructing a document synthesis pipeline, generating realistic but degraded data with NER labels. We measure the NER accuracy drop at various degradation levels and show that a text restoration model, trained on the degraded data, significantly closes the NER accuracy gaps caused by OCR errors, including on an out-of-domain dataset. For the benefit of the community, we have made the document synthesis pipeline available as an open-source project.
Revealing the Dark Secrets of BERT
Sep 11, 2019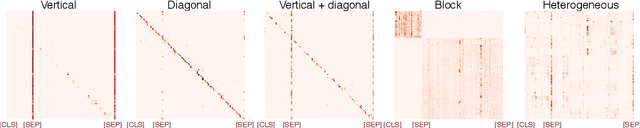
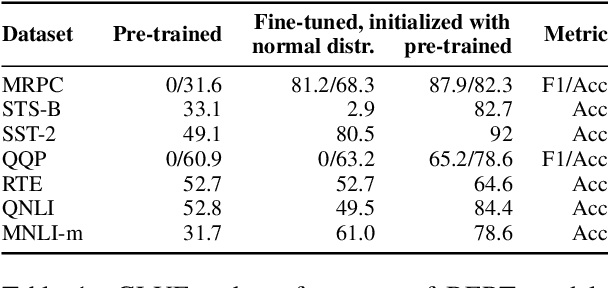
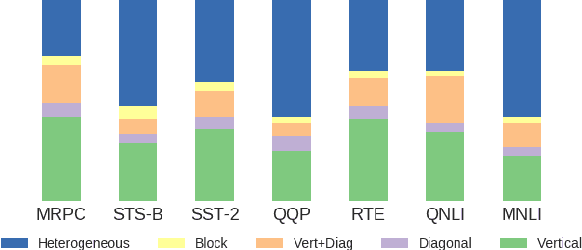
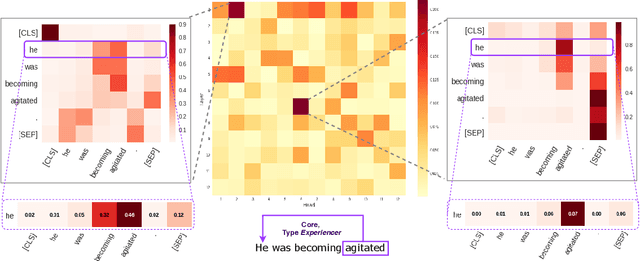
BERT-based architectures currently give state-of-the-art performance on many NLP tasks, but little is known about the exact mechanisms that contribute to its success. In the current work, we focus on the interpretation of self-attention, which is one of the fundamental underlying components of BERT. Using a subset of GLUE tasks and a set of handcrafted features-of-interest, we propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT's heads. Our findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization. While different heads consistently use the same attention patterns, they have varying impact on performance across different tasks. We show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
What's in a Name? Reducing Bias in Bios without Access to Protected Attributes
Apr 10, 2019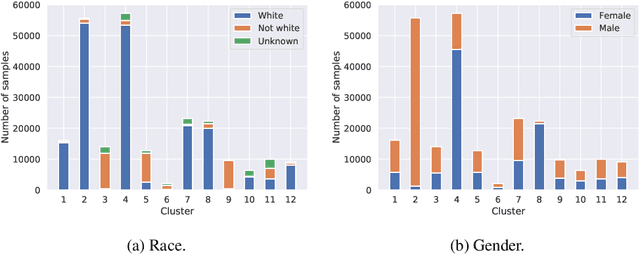
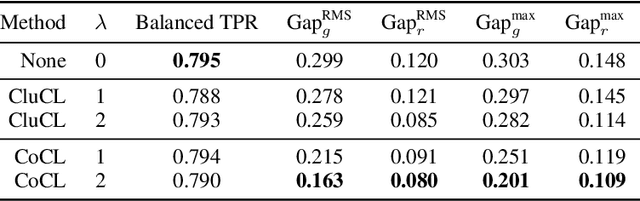
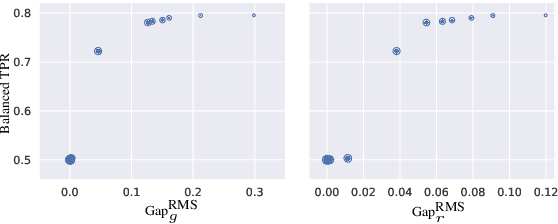
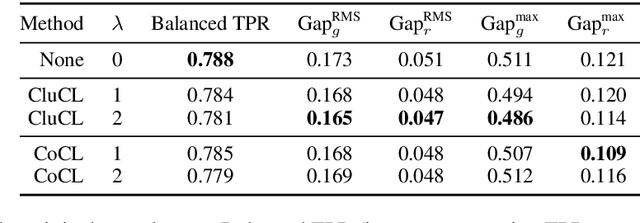
There is a growing body of work that proposes methods for mitigating bias in machine learning systems. These methods typically rely on access to protected attributes such as race, gender, or age. However, this raises two significant challenges: (1) protected attributes may not be available or it may not be legal to use them, and (2) it is often desirable to simultaneously consider multiple protected attributes, as well as their intersections. In the context of mitigating bias in occupation classification, we propose a method for discouraging correlation between the predicted probability of an individual's true occupation and a word embedding of their name. This method leverages the societal biases that are encoded in word embeddings, eliminating the need for access to protected attributes. Crucially, it only requires access to individuals' names at training time and not at deployment time. We evaluate two variations of our proposed method using a large-scale dataset of online biographies. We find that both variations simultaneously reduce race and gender biases, with almost no reduction in the classifier's overall true positive rate.
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
Jan 27, 2019
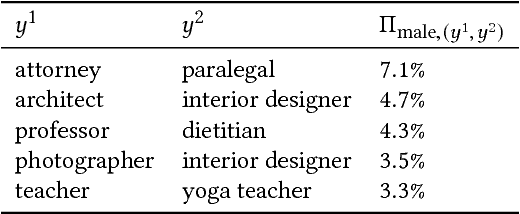
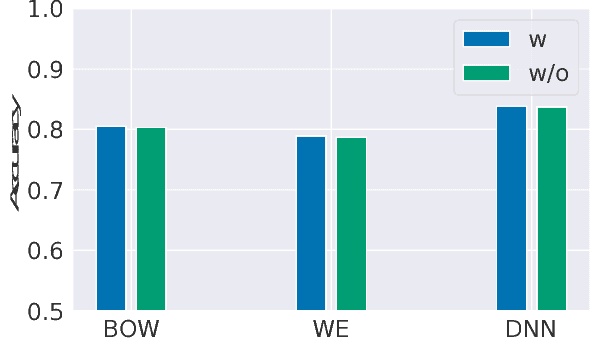

We present a large-scale study of gender bias in occupation classification, a task where the use of machine learning may lead to negative outcomes on peoples' lives. We analyze the potential allocation harms that can result from semantic representation bias. To do so, we study the impact on occupation classification of including explicit gender indicators---such as first names and pronouns---in different semantic representations of online biographies. Additionally, we quantify the bias that remains when these indicators are "scrubbed," and describe proxy behavior that occurs in the absence of explicit gender indicators. As we demonstrate, differences in true positive rates between genders are correlated with existing gender imbalances in occupations, which may compound these imbalances.
Adversarial Decomposition of Text Representation
Aug 27, 2018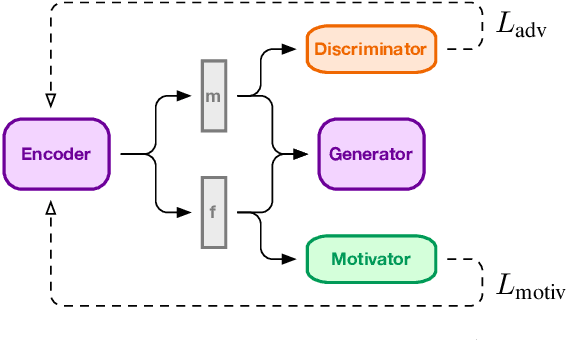

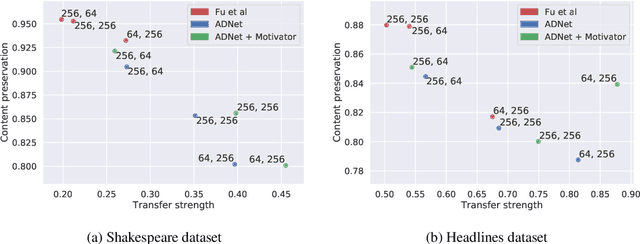

In this paper, we present a method for adversarial decomposition of text representation. This method can be used to decompose a representation of an input sentence into several independent vectors, where each vector is responsible for a specific aspect of the input sentence. We evaluate the proposed method on several case studies: the conversion between different social registers, diachronic language change and the decomposition of the sentiment polarity of input sentences. We show that the proposed method is capable of fine-grained controlled change of these aspects of the input sentence. The model uses adversarial-motivational training and includes a special motivational loss, which acts opposite to the discriminator and encourages a better decomposition. Finally, we evaluate the obtained meaning embeddings on a downstream task of paraphrase detection and show that they are significantly better than embeddings of a regular autoencoder.
Lessons from Natural Language Inference in the Clinical Domain
Aug 27, 2018


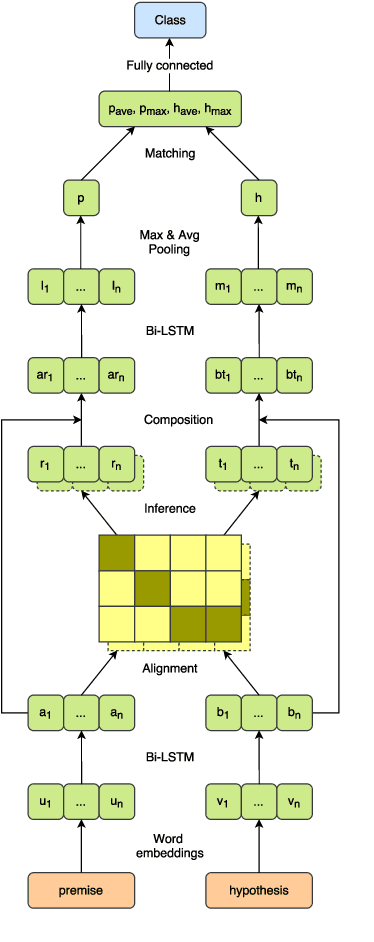
State of the art models using deep neural networks have become very good in learning an accurate mapping from inputs to outputs. However, they still lack generalization capabilities in conditions that differ from the ones encountered during training. This is even more challenging in specialized, and knowledge intensive domains, where training data is limited. To address this gap, we introduce MedNLI - a dataset annotated by doctors, performing a natural language inference task (NLI), grounded in the medical history of patients. We present strategies to: 1) leverage transfer learning using datasets from the open domain, (e.g. SNLI) and 2) incorporate domain knowledge from external data and lexical sources (e.g. medical terminologies). Our results demonstrate performance gains using both strategies.
Temporal Information Extraction for Question Answering Using Syntactic Dependencies in an LSTM-based Architecture
Oct 05, 2017
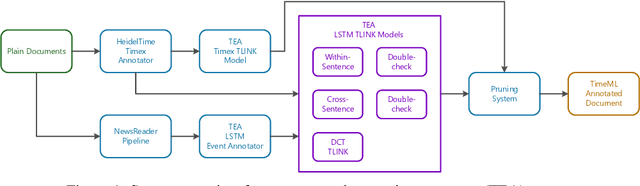

In this paper, we propose to use a set of simple, uniform in architecture LSTM-based models to recover different kinds of temporal relations from text. Using the shortest dependency path between entities as input, the same architecture is used to extract intra-sentence, cross-sentence, and document creation time relations. A "double-checking" technique reverses entity pairs in classification, boosting the recall of positive cases and reducing misclassifications between opposite classes. An efficient pruning algorithm resolves conflicts globally. Evaluated on QA-TempEval (SemEval2015 Task 5), our proposed technique outperforms state-of-the-art methods by a large margin.
Here's My Point: Joint Pointer Architecture for Argument Mining
May 08, 2017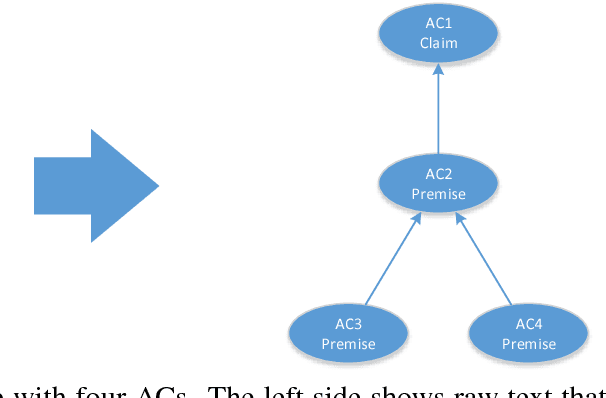
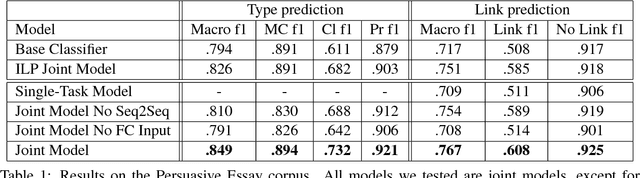
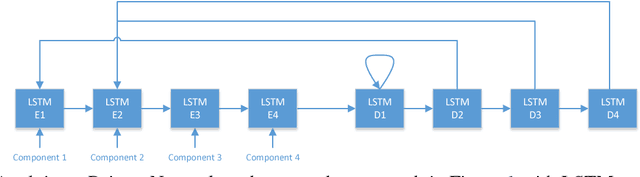
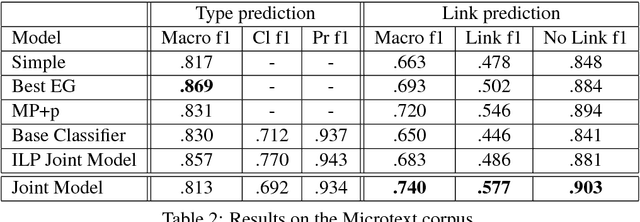
One of the major goals in automated argumentation mining is to uncover the argument structure present in argumentative text. In order to determine this structure, one must understand how different individual components of the overall argument are linked. General consensus in this field dictates that the argument components form a hierarchy of persuasion, which manifests itself in a tree structure. This work provides the first neural network-based approach to argumentation mining, focusing on the two tasks of extracting links between argument components, and classifying types of argument components. In order to solve this problem, we propose to use a joint model that is based on a Pointer Network architecture. A Pointer Network is appealing for this task for the following reasons: 1) It takes into account the sequential nature of argument components; 2) By construction, it enforces certain properties of the tree structure present in argument relations; 3) The hidden representations can be applied to auxiliary tasks. In order to extend the contribution of the original Pointer Network model, we construct a joint model that simultaneously attempts to learn the type of argument component, as well as continuing to predict links between argument components. The proposed joint model achieves state-of-the-art results on two separate evaluation corpora, achieving far superior performance than a regular Pointer Network model. Our results show that optimizing for both tasks, and adding a fully-connected layer prior to recurrent neural network input, is crucial for high performance.
Forced to Learn: Discovering Disentangled Representations Without Exhaustive Labels
May 01, 2017
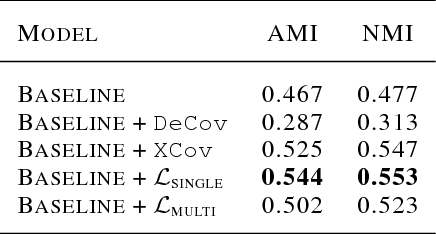
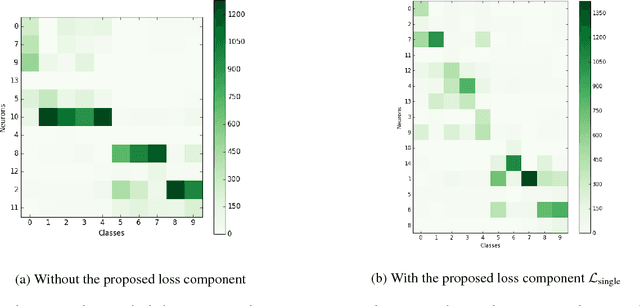
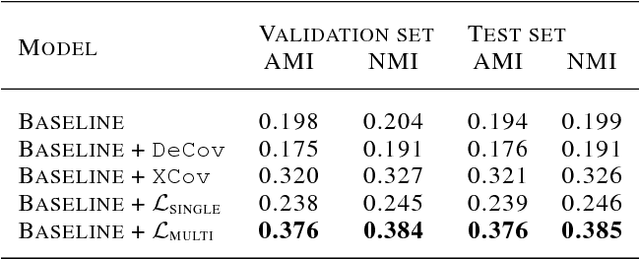
Learning a better representation with neural networks is a challenging problem, which was tackled extensively from different prospectives in the past few years. In this work, we focus on learning a representation that could be used for a clustering task and introduce two novel loss components that substantially improve the quality of produced clusters, are simple to apply to an arbitrary model and cost function, and do not require a complicated training procedure. We evaluate them on two most common types of models, Recurrent Neural Networks and Convolutional Neural Networks, showing that the approach we propose consistently improves the quality of KMeans clustering in terms of Adjusted Mutual Information score and outperforms previously proposed methods.