 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Evidence Grounding via Structured Inline Citation Generation
Jun 05, 2026As AI systems become more widely adopted, the demand for factual and faithful generation grows. Properly attributing information through citations becomes, therefore, crucial. This work introduces FullCite, a framework that, in contrast to most previous works, generates structured inline citations linking each claim to both its source document and supporting evidence. FullCite proposes three strategies to inline citation generation: prompt-based generation, constrained decoding over a citation grammar, and posthoc span alignment. Using three question answering benchmarks, namely, ASQA, BioASQ, and ExpertQA, we assess citation quality and faithfulness along three dimensions: document-level correctness, evidence span identification, and claim-citation faithfulness. Our evaluation shows that while LLMs are generally effective at identifying relevant documents, they struggle to identify the precise supporting spans within them. This gap suggests that achieving faithful attributed QA will require research to place greater emphasis on precise evidence span identification.
Do Syntactic Categories Help in Developmentally Motivated Curriculum Learning for Language Models?
Nov 11, 2025We examine the syntactic properties of BabyLM corpus, and age-groups within CHILDES. While we find that CHILDES does not exhibit strong syntactic differentiation by age, we show that the syntactic knowledge about the training data can be helpful in interpreting model performance on linguistic tasks. For curriculum learning, we explore developmental and several alternative cognitively inspired curriculum approaches. We find that some curricula help with reading tasks, but the main performance improvement come from using the subset of syntactically categorizable data, rather than the full noisy corpus.
Research Community Perspectives on "Intelligence" and Large Language Models
May 27, 2025Despite the widespread use of ''artificial intelligence'' (AI) framing in Natural Language Processing (NLP) research, it is not clear what researchers mean by ''intelligence''. To that end, we present the results of a survey on the notion of ''intelligence'' among researchers and its role in the research agenda. The survey elicited complete responses from 303 researchers from a variety of fields including NLP, Machine Learning (ML), Cognitive Science, Linguistics, and Neuroscience. We identify 3 criteria of intelligence that the community agrees on the most: generalization, adaptability, & reasoning. Our results suggests that the perception of the current NLP systems as ''intelligent'' is a minority position (29%). Furthermore, only 16.2% of the respondents see developing intelligent systems as a research goal, and these respondents are more likely to consider the current systems intelligent.
AI "News" Content Farms Are Easy to Make and Hard to Detect: A Case Study in Italian
Jun 17, 2024Large Language Models (LLMs) are increasingly used as "content farm" models (CFMs), to generate synthetic text that could pass for real news articles. This is already happening even for languages that do not have high-quality monolingual LLMs. We show that fine-tuning Llama (v1), mostly trained on English, on as little as 40K Italian news articles, is sufficient for producing news-like texts that native speakers of Italian struggle to identify as synthetic. We investigate three LLMs and three methods of detecting synthetic texts (log-likelihood, DetectGPT, and supervised classification), finding that they all perform better than human raters, but they are all impractical in the real world (requiring either access to token likelihood information or a large dataset of CFM texts). We also explore the possibility of creating a proxy CFM: an LLM fine-tuned on a similar dataset to one used by the real "content farm". We find that even a small amount of fine-tuning data suffices for creating a successful detector, but we need to know which base LLM is used, which is a major challenge. Our results suggest that there are currently no practical methods for detecting synthetic news-like texts 'in the wild', while generating them is too easy. We highlight the urgency of more NLP research on this problem.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.
Mind your Language : Fact-Checking LLMs and their Role in NLP Research and Practice
Aug 14, 2023Much of the recent discourse within the NLP research community has been centered around Large Language Models (LLMs), their functionality and potential -- yet not only do we not have a working definition of LLMs, but much of this discourse relies on claims and assumptions that are worth re-examining. This position paper contributes a definition of LLMs, explicates some of the assumptions made regarding their functionality, and outlines the existing evidence for and against them. We conclude with suggestions for research directions and their framing in future work.
Using Sequences of Life-events to Predict Human Lives
Jun 05, 2023Over the past decade, machine learning has revolutionized computers' ability to analyze text through flexible computational models. Due to their structural similarity to written language, transformer-based architectures have also shown promise as tools to make sense of a range of multi-variate sequences from protein-structures, music, electronic health records to weather-forecasts. We can also represent human lives in a way that shares this structural similarity to language. From one perspective, lives are simply sequences of events: People are born, visit the pediatrician, start school, move to a new location, get married, and so on. Here, we exploit this similarity to adapt innovations from natural language processing to examine the evolution and predictability of human lives based on detailed event sequences. We do this by drawing on arguably the most comprehensive registry data in existence, available for an entire nation of more than six million individuals across decades. Our data include information about life-events related to health, education, occupation, income, address, and working hours, recorded with day-to-day resolution. We create embeddings of life-events in a single vector space showing that this embedding space is robust and highly structured. Our models allow us to predict diverse outcomes ranging from early mortality to personality nuances, outperforming state-of-the-art models by a wide margin. Using methods for interpreting deep learning models, we probe the algorithm to understand the factors that enable our predictions. Our framework allows researchers to identify new potential mechanisms that impact life outcomes and associated possibilities for personalized interventions.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023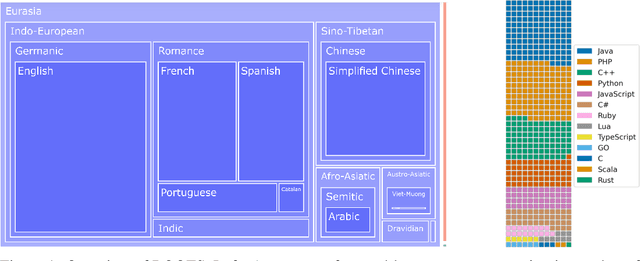


As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
The ROOTS Search Tool: Data Transparency for LLMs
Feb 27, 2023
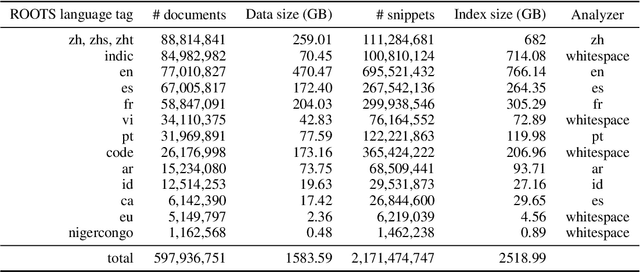

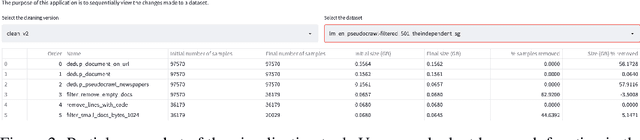
ROOTS is a 1.6TB multilingual text corpus developed for the training of BLOOM, currently the largest language model explicitly accompanied by commensurate data governance efforts. In continuation of these efforts, we present the ROOTS Search Tool: a search engine over the entire ROOTS corpus offering both fuzzy and exact search capabilities. ROOTS is the largest corpus to date that can be investigated this way. The ROOTS Search Tool is open-sourced and available on Hugging Face Spaces. We describe our implementation and the possible use cases of our tool.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.