 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Query Fairness Under Unawareness
Jun 04, 2025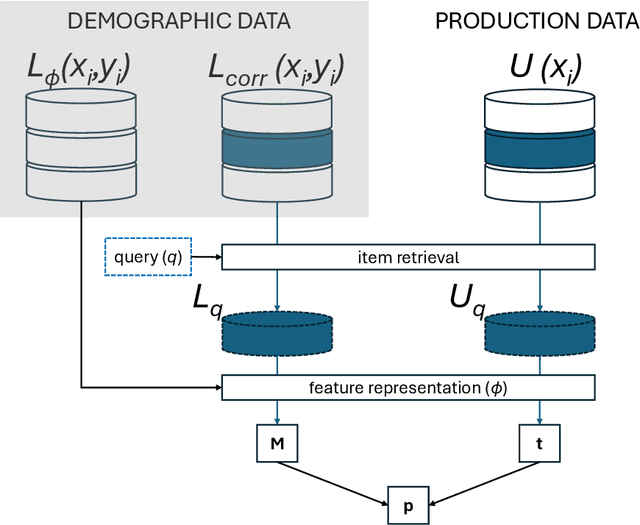

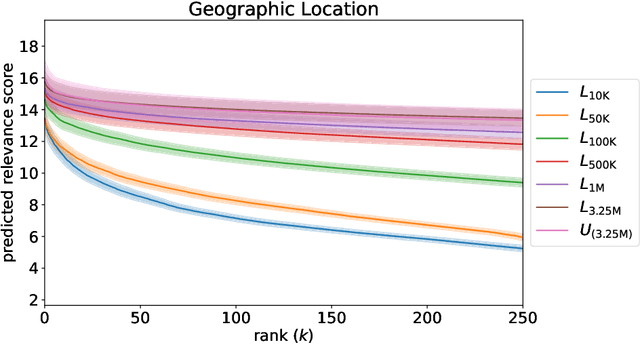

Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
Stress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool Detectors
May 30, 2025Recent advancements in Generative AI and Large Language Models (LLMs) have enabled the creation of highly realistic synthetic content, raising concerns about the potential for malicious use, such as misinformation and manipulation. Moreover, detecting Machine-Generated Text (MGT) remains challenging due to the lack of robust benchmarks that assess generalization to real-world scenarios. In this work, we present a pipeline to test the resilience of state-of-the-art MGT detectors (e.g., Mage, Radar, LLM-DetectAIve) to linguistically informed adversarial attacks. To challenge the detectors, we fine-tune language models using Direct Preference Optimization (DPO) to shift the MGT style toward human-written text (HWT). This exploits the detectors' reliance on stylistic clues, making new generations more challenging to detect. Additionally, we analyze the linguistic shifts induced by the alignment and which features are used by detectors to detect MGT texts. Our results show that detectors can be easily fooled with relatively few examples, resulting in a significant drop in detection performance. This highlights the importance of improving detection methods and making them robust to unseen in-domain texts.
Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary Adaptation
Apr 23, 2025The number of pretrained Large Language Models (LLMs) is increasing steadily, though the majority are designed predominantly for the English language. While state-of-the-art LLMs can handle other languages, due to language contamination or some degree of multilingual pretraining data, they are not optimized for non-English languages, leading to inefficient encoding (high token "fertility") and slower inference speed. In this work, we thoroughly compare a variety of vocabulary adaptation techniques for optimizing English LLMs for the Italian language, and put forward Semantic Alignment Vocabulary Adaptation (SAVA), a novel method that leverages neural mapping for vocabulary substitution. SAVA achieves competitive performance across multiple downstream tasks, enhancing grounded alignment strategies. We adapt two LLMs: Mistral-7b-v0.1, reducing token fertility by 25\%, and Llama-3.1-8B, optimizing the vocabulary and reducing the number of parameters by 1 billion. We show that, following the adaptation of the vocabulary, these models can recover their performance with a relatively limited stage of continual training on the target language. Finally, we test the capabilities of the adapted models on various multi-choice and generative tasks.
AI "News" Content Farms Are Easy to Make and Hard to Detect: A Case Study in Italian
Jun 17, 2024Large Language Models (LLMs) are increasingly used as "content farm" models (CFMs), to generate synthetic text that could pass for real news articles. This is already happening even for languages that do not have high-quality monolingual LLMs. We show that fine-tuning Llama (v1), mostly trained on English, on as little as 40K Italian news articles, is sufficient for producing news-like texts that native speakers of Italian struggle to identify as synthetic. We investigate three LLMs and three methods of detecting synthetic texts (log-likelihood, DetectGPT, and supervised classification), finding that they all perform better than human raters, but they are all impractical in the real world (requiring either access to token likelihood information or a large dataset of CFM texts). We also explore the possibility of creating a proxy CFM: an LLM fine-tuned on a similar dataset to one used by the real "content farm". We find that even a small amount of fine-tuning data suffices for creating a successful detector, but we need to know which base LLM is used, which is a major challenge. Our results suggest that there are currently no practical methods for detecting synthetic news-like texts 'in the wild', while generating them is too easy. We highlight the urgency of more NLP research on this problem.
The Invalsi Benchmark: measuring Language Models Mathematical and Language understanding in Italian
Mar 27, 2024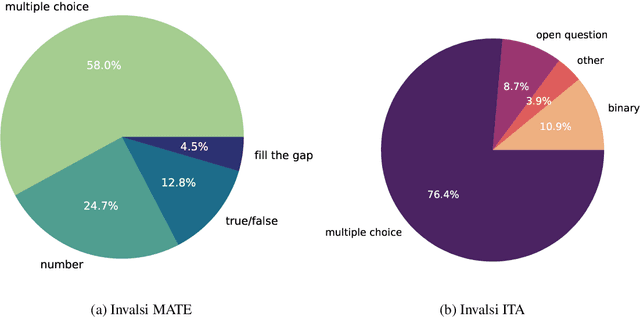
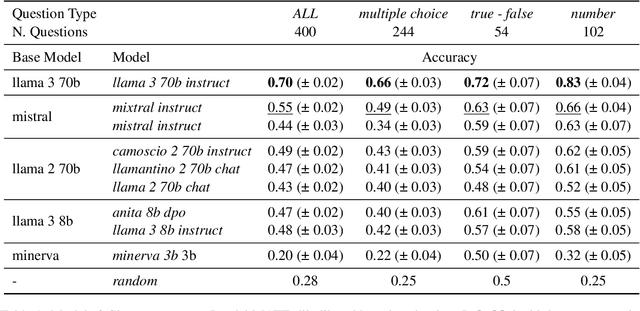
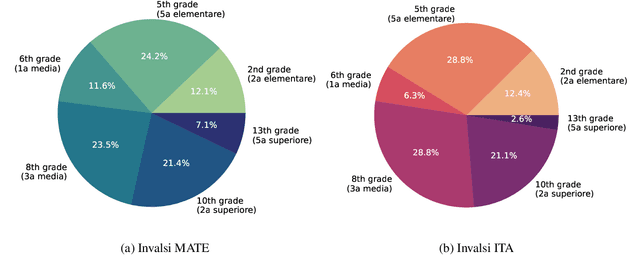
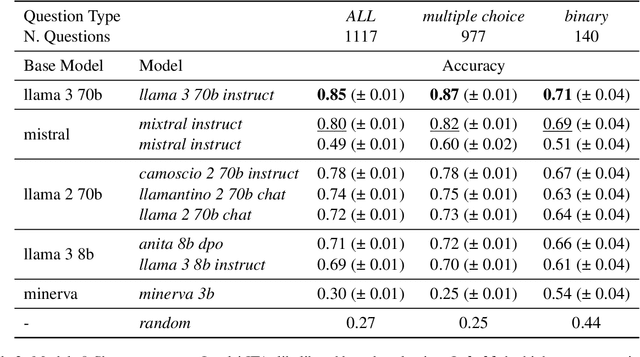
While Italian is by all metrics a high resource language, currently, there are isn't a Language Model pre-trained exclusively in this language. This results in a lower number of available benchmarks to evaluate the performance of language models in Italian. This work presents two new benchmarks to evaluate the models performance on mathematical understanding and language understanding in Italian. These benchmarks are based on real tests that are undertaken by students of age between 11 and 18 within the Italian school system and have therefore been validated by several experts in didactics and pedagogy. To validate this dataset we evaluate the performance of 9 language models that are the best performing when writing in Italian, including our own fine-tuned models. We show that this is a challenging benchmark where current language models are bound by 60\% accuracy. We believe that the release of this dataset paves the way for improving future models mathematical and language understanding in Italian.
Detecting Images Generated by Diffusers
Mar 09, 2023This paper explores the task of detecting images generated by text-to-image diffusion models. To evaluate this, we consider images generated from captions in the MSCOCO and Wikimedia datasets using two state-of-the-art models: Stable Diffusion and GLIDE. Our experiments show that it is possible to detect the generated images using simple Multi-Layer Perceptrons (MLPs), starting from features extracted by CLIP, or traditional Convolutional Neural Networks (CNNs). We also observe that models trained on images generated by Stable Diffusion can detect images generated by GLIDE relatively well, however, the reverse is not true. Lastly, we find that incorporating the associated textual information with the images rarely leads to significant improvement in detection results but that the type of subject depicted in the image can have a significant impact on performance. This work provides insights into the feasibility of detecting generated images, and has implications for security and privacy concerns in real-world applications.
Unravelling Interlanguage Facts via Explainable Machine Learning
Aug 02, 2022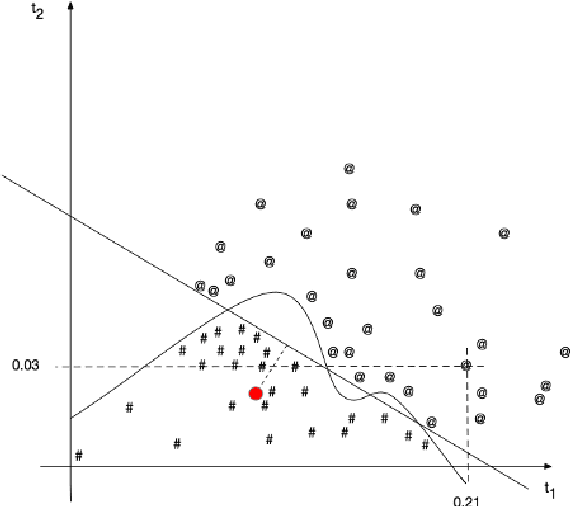
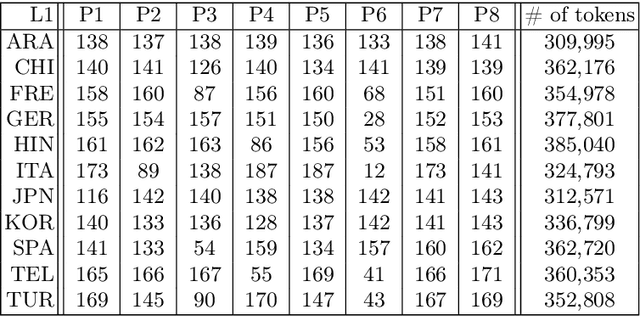
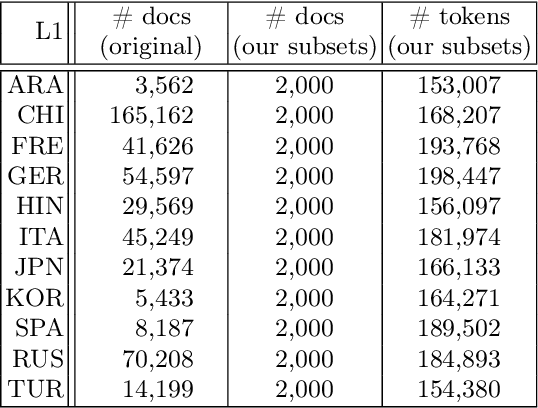
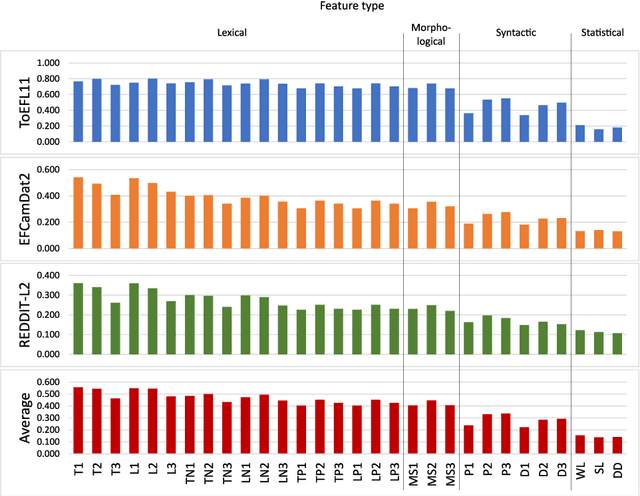
Native language identification (NLI) is the task of training (via supervised machine learning) a classifier that guesses the native language of the author of a text. This task has been extensively researched in the last decade, and the performance of NLI systems has steadily improved over the years. We focus on a different facet of the NLI task, i.e., that of analysing the internals of an NLI classifier trained by an \emph{explainable} machine learning algorithm, in order to obtain explanations of its classification decisions, with the ultimate goal of gaining insight into which linguistic phenomena ``give a speaker's native language away''. We use this perspective in order to tackle both NLI and a (much less researched) companion task, i.e., guessing whether a text has been written by a native or a non-native speaker. Using three datasets of different provenance (two datasets of English learners' essays and a dataset of social media posts), we investigate which kind of linguistic traits (lexical, morphological, syntactic, and statistical) are most effective for solving our two tasks, namely, are most indicative of a speaker's L1. We also present two case studies, one on Spanish and one on Italian learners of English, in which we analyse individual linguistic traits that the classifiers have singled out as most important for spotting these L1s. Overall, our study shows that the use of explainable machine learning can be a valuable tool for th
Transformer-Based Multi-modal Proposal and Re-Rank for Wikipedia Image-Caption Matching
Jun 21, 2022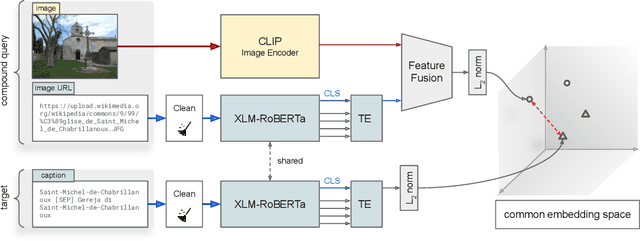
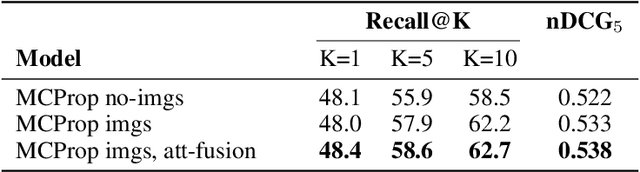
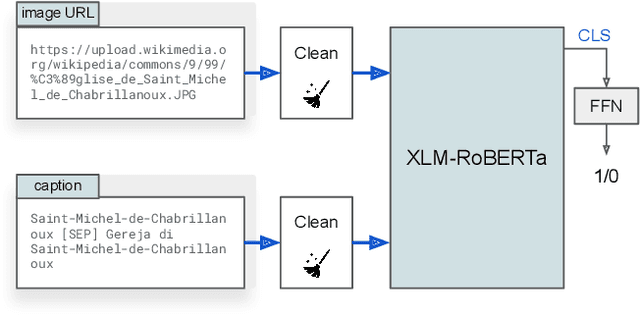
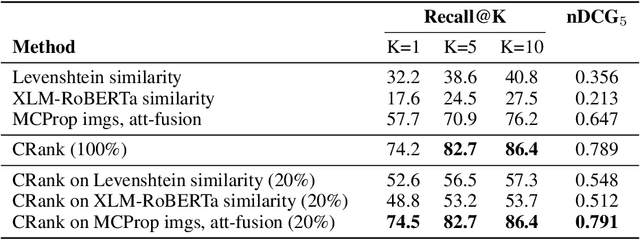
With the increased accessibility of web and online encyclopedias, the amount of data to manage is constantly increasing. In Wikipedia, for example, there are millions of pages written in multiple languages. These pages contain images that often lack the textual context, remaining conceptually floating and therefore harder to find and manage. In this work, we present the system we designed for participating in the Wikipedia Image-Caption Matching challenge on Kaggle, whose objective is to use data associated with images (URLs and visual data) to find the correct caption among a large pool of available ones. A system able to perform this task would improve the accessibility and completeness of multimedia content on large online encyclopedias. Specifically, we propose a cascade of two models, both powered by the recent Transformer model, able to efficiently and effectively infer a relevance score between the query image data and the captions. We verify through extensive experimentation that the proposed two-model approach is an effective way to handle a large pool of images and captions while maintaining bounded the overall computational complexity at inference time. Our approach achieves remarkable results, obtaining a normalized Discounted Cumulative Gain (nDCG) value of 0.53 on the private leaderboard of the Kaggle challenge.
LeQua@CLEF2022: Learning to Quantify
Nov 30, 2021LeQua 2022 is a new lab for the evaluation of methods for "learning to quantify" in textual datasets, i.e., for training predictors of the relative frequencies of the classes of interest in sets of unlabelled textual documents. While these predictions could be easily achieved by first classifying all documents via a text classifier and then counting the numbers of documents assigned to the classes, a growing body of literature has shown this approach to be suboptimal, and has proposed better methods. The goal of this lab is to provide a setting for the comparative evaluation of methods for learning to quantify, both in the binary setting and in the single-label multiclass setting. For each such setting we provide data either in ready-made vector form or in raw document form.
Measuring Fairness under Unawareness via Quantification
Sep 17, 2021
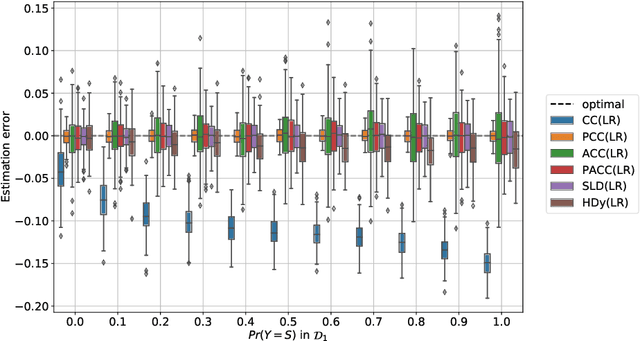

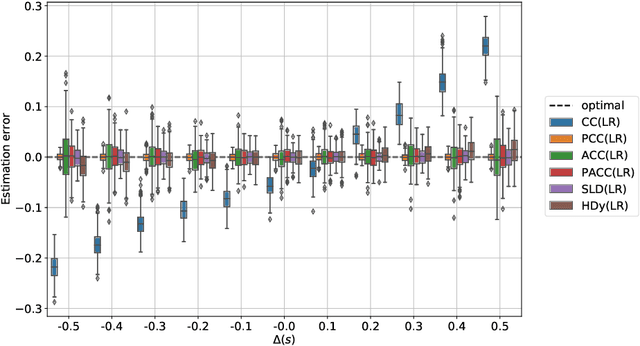
Models trained by means of supervised learning are increasingly deployed in high-stakes domains, and, when their predictions inform decisions about people, they inevitably impact (positively or negatively) on their lives. As a consequence, those in charge of developing these models must carefully evaluate their impact on different groups of people and ensure that sensitive demographic attributes, such as race or sex, do not result in unfair treatment for members of specific groups. For doing this, awareness of demographic attributes on the part of those evaluating model impacts is fundamental. Unfortunately, the collection of these attributes is often in conflict with industry practices and legislation on data minimization and privacy. For this reason, it may be hard to measure the group fairness of trained models, even from within the companies developing them. In this work, we tackle the problem of measuring group fairness under unawareness of sensitive attributes, by using techniques from quantification, a supervised learning task concerned with directly providing group-level prevalence estimates (rather than individual-level class labels). We identify five important factors that complicate the estimation of fairness under unawareness and formalize them into five different experimental protocols under which we assess the effectiveness of different estimators of group fairness. We also consider the problem of potential model misuse to infer sensitive attributes at an individual level, and demonstrate that quantification approaches are suitable for decoupling the (desirable) objective of measuring group fairness from the (undesirable) objective of inferring sensitive attributes of individuals.