 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool Detectors
May 30, 2025Recent advancements in Generative AI and Large Language Models (LLMs) have enabled the creation of highly realistic synthetic content, raising concerns about the potential for malicious use, such as misinformation and manipulation. Moreover, detecting Machine-Generated Text (MGT) remains challenging due to the lack of robust benchmarks that assess generalization to real-world scenarios. In this work, we present a pipeline to test the resilience of state-of-the-art MGT detectors (e.g., Mage, Radar, LLM-DetectAIve) to linguistically informed adversarial attacks. To challenge the detectors, we fine-tune language models using Direct Preference Optimization (DPO) to shift the MGT style toward human-written text (HWT). This exploits the detectors' reliance on stylistic clues, making new generations more challenging to detect. Additionally, we analyze the linguistic shifts induced by the alignment and which features are used by detectors to detect MGT texts. Our results show that detectors can be easily fooled with relatively few examples, resulting in a significant drop in detection performance. This highlights the importance of improving detection methods and making them robust to unseen in-domain texts.
How Humans and LLMs Organize Conceptual Knowledge: Exploring Subordinate Categories in Italian
May 27, 2025People can categorize the same entity at multiple taxonomic levels, such as basic (bear), superordinate (animal), and subordinate (grizzly bear). While prior research has focused on basic-level categories, this study is the first attempt to examine the organization of categories by analyzing exemplars produced at the subordinate level. We present a new Italian psycholinguistic dataset of human-generated exemplars for 187 concrete words. We then use these data to evaluate whether textual and vision LLMs produce meaningful exemplars that align with human category organization across three key tasks: exemplar generation, category induction, and typicality judgment. Our findings show a low alignment between humans and LLMs, consistent with previous studies. However, their performance varies notably across different semantic domains. Ultimately, this study highlights both the promises and the constraints of using AI-generated exemplars to support psychological and linguistic research.
ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
Nov 13, 2023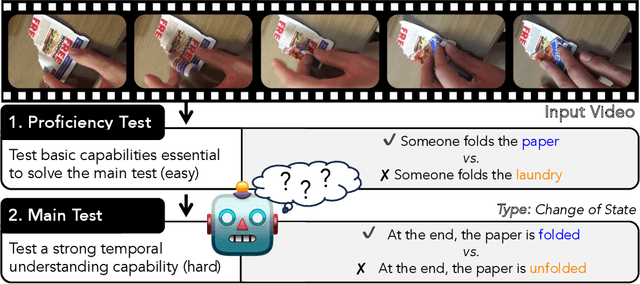
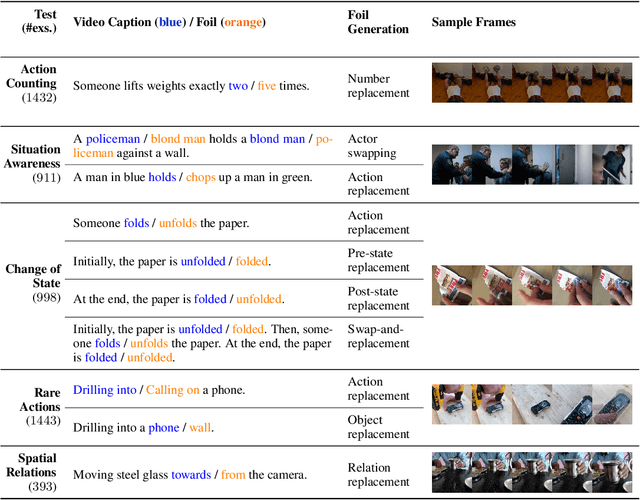
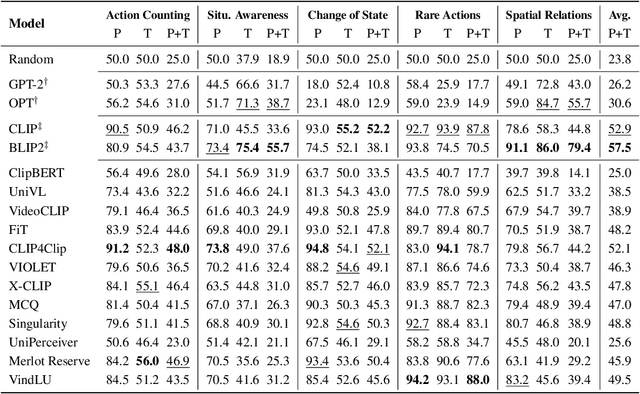

With the ever-increasing popularity of pretrained Video-Language Models (VidLMs), there is a pressing need to develop robust evaluation methodologies that delve deeper into their visio-linguistic capabilities. To address this challenge, we present ViLMA (Video Language Model Assessment), a task-agnostic benchmark that places the assessment of fine-grained capabilities of these models on a firm footing. Task-based evaluations, while valuable, fail to capture the complexities and specific temporal aspects of moving images that VidLMs need to process. Through carefully curated counterfactuals, ViLMA offers a controlled evaluation suite that sheds light on the true potential of these models, as well as their performance gaps compared to human-level understanding. ViLMA also includes proficiency tests, which assess basic capabilities deemed essential to solving the main counterfactual tests. We show that current VidLMs' grounding abilities are no better than those of vision-language models which use static images. This is especially striking once the performance on proficiency tests is factored in. Our benchmark serves as a catalyst for future research on VidLMs, helping to highlight areas that still need to be explored.