 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mystery of Compositional Generalization in Graph-based Generative Commonsense Reasoning
Oct 08, 2024While LLMs have emerged as performant architectures for reasoning tasks, their compositional generalization capabilities have been questioned. In this work, we introduce a Compositional Generalization Challenge for Graph-based Commonsense Reasoning (CGGC) that goes beyond previous evaluations that are based on sequences or tree structures - and instead involves a reasoning graph: It requires models to generate a natural sentence based on given concepts and a corresponding reasoning graph, where the presented graph involves a previously unseen combination of relation types. To master this challenge, models need to learn how to reason over relation tupels within the graph, and how to compose them when conceptualizing a verbalization. We evaluate seven well-known LLMs using in-context learning and find that performant LLMs still struggle in compositional generalization. We investigate potential causes of this gap by analyzing the structures of reasoning graphs, and find that different structures present varying levels of difficulty for compositional generalization. Arranging the order of demonstrations according to the structures' difficulty shows that organizing samples in an easy-to-hard schema enhances the compositional generalization ability of LLMs.
Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
Apr 29, 2024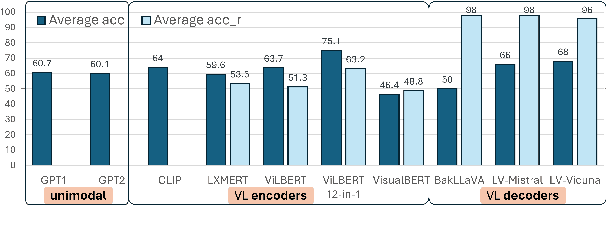
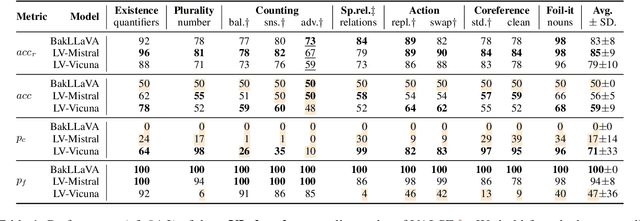
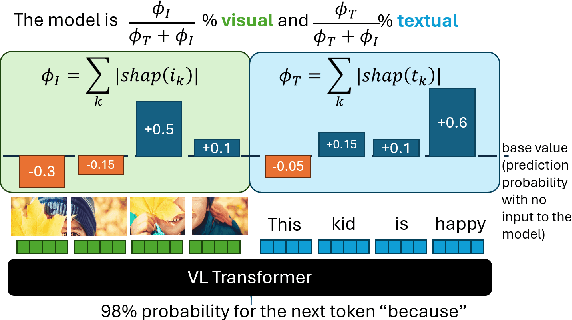
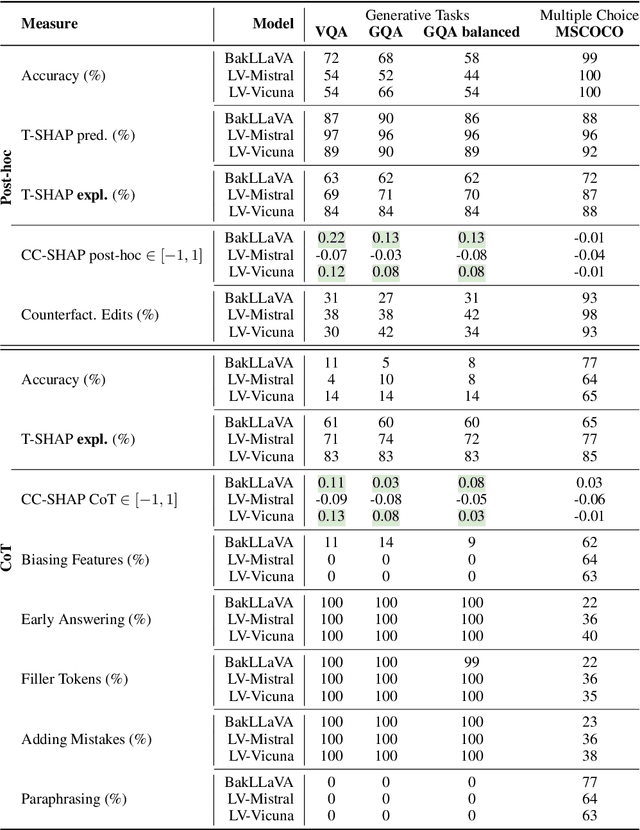
Vision and language models (VLMs) are currently the most generally performant architectures on multimodal tasks. Next to their predictions, they can also produce explanations, either in post-hoc or CoT settings. However, it is not clear how much they use the vision and text modalities when generating predictions or explanations. In this work, we investigate if VLMs rely on modalities differently when generating explanations as opposed to when they provide answers. We also evaluate the self-consistency of VLM decoders in both post-hoc and CoT explanation settings, by extending existing tests and measures to VLM decoders. We find that VLMs are less self-consistent than LLMs. The text contributions in VL decoders are much larger than the image contributions across all measured tasks. And the contributions of the image are significantly larger for explanation generations than for answer generation. This difference is even larger in CoT compared to the post-hoc explanation setting. We also provide an up-to-date benchmarking of state-of-the-art VL decoders on the VALSE benchmark, which to date focused only on VL encoders. We find that VL decoders are still struggling with most phenomena tested by VALSE.
Clinical information extraction for Low-resource languages with Few-shot learning using Pre-trained language models and Prompting
Mar 20, 2024



Automatic extraction of medical information from clinical documents poses several challenges: high costs of required clinical expertise, limited interpretability of model predictions, restricted computational resources and privacy regulations. Recent advances in domain-adaptation and prompting methods showed promising results with minimal training data using lightweight masked language models, which are suited for well-established interpretability methods. We are first to present a systematic evaluation of these methods in a low-resource setting, by performing multi-class section classification on German doctor's letters. We conduct extensive class-wise evaluations supported by Shapley values, to validate the quality of our small training data set and to ensure the interpretability of model predictions. We demonstrate that a lightweight, domain-adapted pretrained model, prompted with just 20 shots, outperforms a traditional classification model by 30.5% accuracy. Our results serve as a process-oriented guideline for clinical information extraction projects working with low-resource.
Exploring Continual Learning of Compositional Generalization in NLI
Mar 07, 2024Compositional Natural Language Inference has been explored to assess the true abilities of neural models to perform NLI. Yet, current evaluations assume models to have full access to all primitive inferences in advance, in contrast to humans that continuously acquire inference knowledge. In this paper, we introduce the Continual Compositional Generalization in Inference (C2Gen NLI) challenge, where a model continuously acquires knowledge of constituting primitive inference tasks as a basis for compositional inferences. We explore how continual learning affects compositional generalization in NLI, by designing a continual learning setup for compositional NLI inference tasks. Our experiments demonstrate that models fail to compositionally generalize in a continual scenario. To address this problem, we first benchmark various continual learning algorithms and verify their efficacy. We then further analyze C2Gen, focusing on how to order primitives and compositional inference types and examining correlations between subtasks. Our analyses show that by learning subtasks continuously while observing their dependencies and increasing degrees of difficulty, continual learning can enhance composition generalization ability.
Graph Language Models
Jan 13, 2024


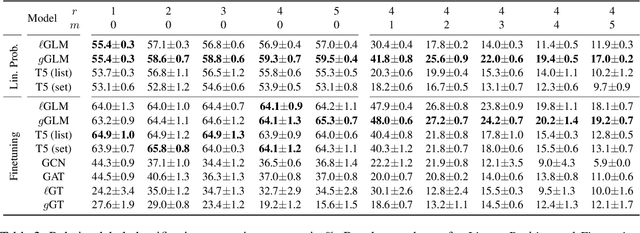
While Language Models have become workhorses for NLP, their interplay with textual knowledge graphs (KGs) - structured memories of general or domain knowledge - is actively researched. Current embedding methodologies for such graphs typically either (i) linearize graphs for embedding them using sequential Language Models (LMs), which underutilize structural information, or (ii) use Graph Neural Networks (GNNs) to preserve graph structure, while GNNs cannot represent textual features as well as a pre-trained LM could. In this work we introduce a novel language model, the Graph Language Model (GLM), that integrates the strengths of both approaches, while mitigating their weaknesses. The GLM parameters are initialized from a pretrained LM, to facilitate nuanced understanding of individual concepts and triplets. Simultaneously, its architectural design incorporates graph biases, thereby promoting effective knowledge distribution within the graph. Empirical evaluations on relation classification tasks on ConceptNet subgraphs reveal that GLM embeddings surpass both LM- and GNN-based baselines in supervised and zero-shot settings.
On Measuring Faithfulness of Natural Language Explanations
Nov 13, 2023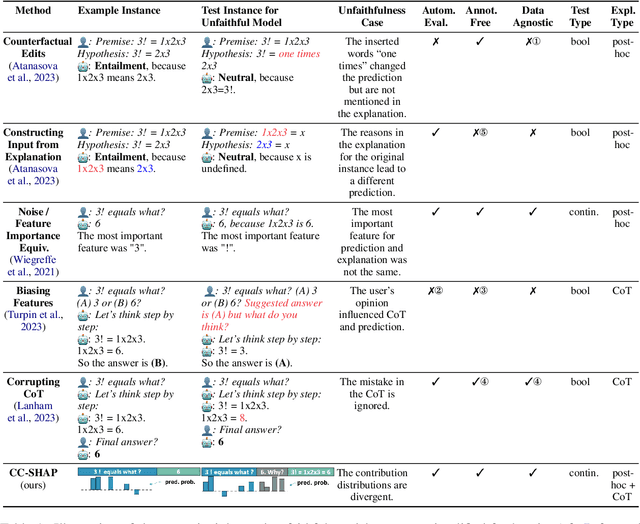
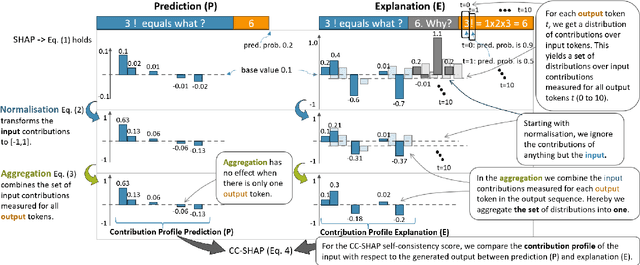
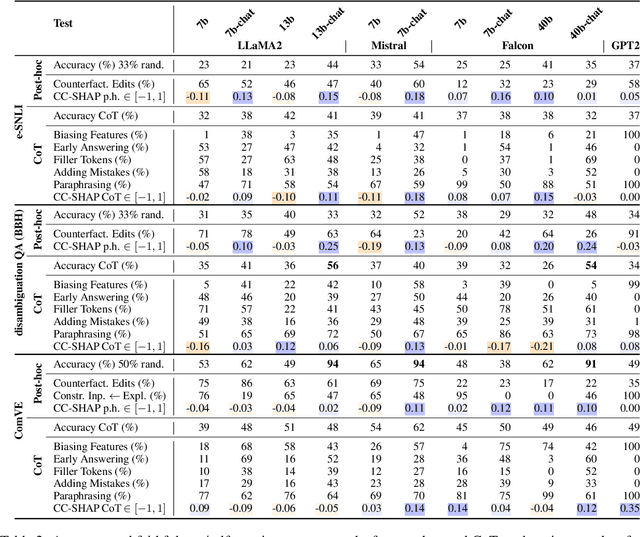
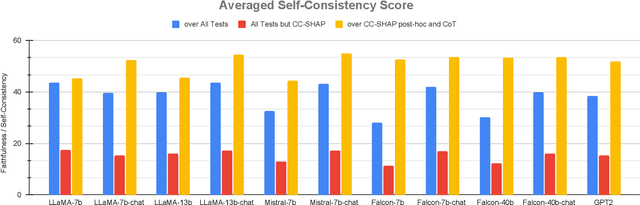
Large language models (LLMs) can explain their own predictions, through post-hoc or Chain-of-Thought (CoT) explanations. However the LLM could make up reasonably sounding explanations that are unfaithful to its underlying reasoning. Recent work has designed tests that aim to judge the faithfulness of either post-hoc or CoT explanations. In this paper we argue that existing faithfulness tests are not actually measuring faithfulness in terms of the models' inner workings, but only evaluate their self-consistency on the output level. The aims of our work are two-fold. i) We aim to clarify the status of existing faithfulness tests in terms of model explainability, characterising them as self-consistency tests instead. This assessment we underline by constructing a Comparative Consistency Bank for self-consistency tests that for the first time compares existing tests on a common suite of 11 open-source LLMs and 5 datasets -- including ii) our own proposed self-consistency measure CC-SHAP. CC-SHAP is a new fine-grained measure (not test) of LLM self-consistency that compares a model's input contributions to answer prediction and generated explanation. With CC-SHAP, we aim to take a step further towards measuring faithfulness with a more interpretable and fine-grained method. Code available at \url{https://github.com/Heidelberg-NLP/CC-SHAP}
ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
Nov 13, 2023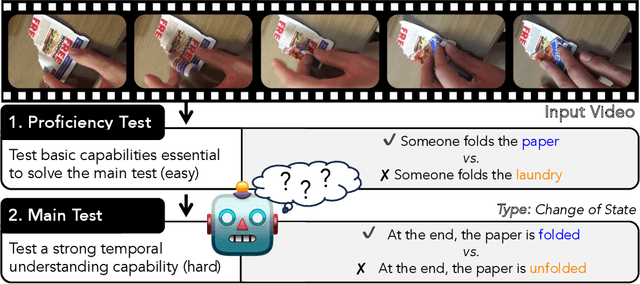
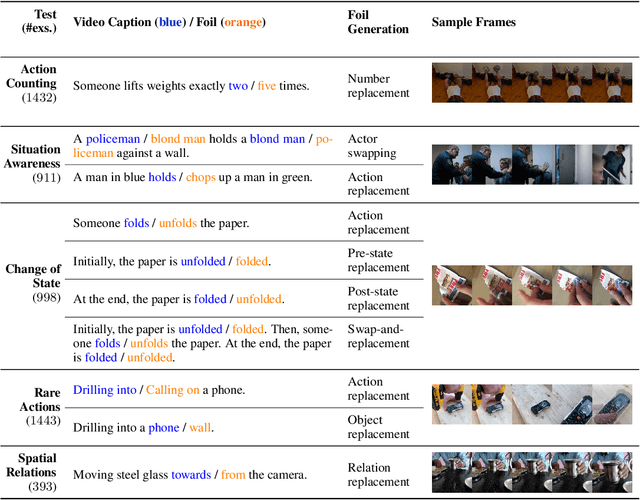
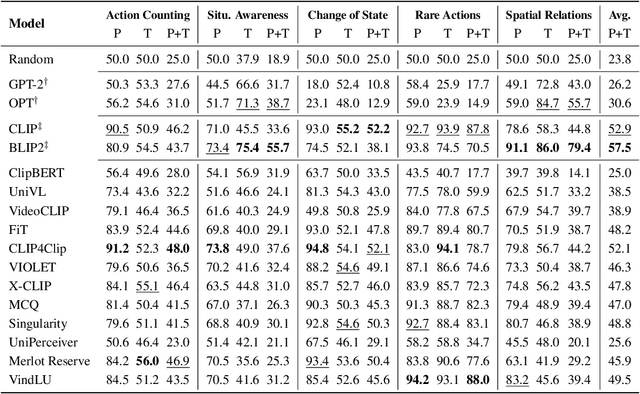

With the ever-increasing popularity of pretrained Video-Language Models (VidLMs), there is a pressing need to develop robust evaluation methodologies that delve deeper into their visio-linguistic capabilities. To address this challenge, we present ViLMA (Video Language Model Assessment), a task-agnostic benchmark that places the assessment of fine-grained capabilities of these models on a firm footing. Task-based evaluations, while valuable, fail to capture the complexities and specific temporal aspects of moving images that VidLMs need to process. Through carefully curated counterfactuals, ViLMA offers a controlled evaluation suite that sheds light on the true potential of these models, as well as their performance gaps compared to human-level understanding. ViLMA also includes proficiency tests, which assess basic capabilities deemed essential to solving the main counterfactual tests. We show that current VidLMs' grounding abilities are no better than those of vision-language models which use static images. This is especially striking once the performance on proficiency tests is factored in. Our benchmark serves as a catalyst for future research on VidLMs, helping to highlight areas that still need to be explored.
Dynamic MOdularized Reasoning for Compositional Structured Explanation Generation
Sep 14, 2023



Despite the success of neural models in solving reasoning tasks, their compositional generalization capabilities remain unclear. In this work, we propose a new setting of the structured explanation generation task to facilitate compositional reasoning research. Previous works found that symbolic methods achieve superior compositionality by using pre-defined inference rules for iterative reasoning. But these approaches rely on brittle symbolic transfers and are restricted to well-defined tasks. Hence, we propose a dynamic modularized reasoning model, MORSE, to improve the compositional generalization of neural models. MORSE factorizes the inference process into a combination of modules, where each module represents a functional unit. Specifically, we adopt modularized self-attention to dynamically select and route inputs to dedicated heads, which specializes them to specific functions. We conduct experiments for increasing lengths and shapes of reasoning trees on two benchmarks to test MORSE's compositional generalization abilities, and find it outperforms competitive baselines. Model ablation and deeper analyses show the effectiveness of dynamic reasoning modules and their generalization abilities.
Graecia capta ferum victorem cepit. Detecting Latin Allusions to Ancient Greek Literature
Aug 23, 2023Intertextual allusions hold a pivotal role in Classical Philology, with Latin authors frequently referencing Ancient Greek texts. Until now, the automatic identification of these intertextual references has been constrained to monolingual approaches, seeking parallels solely within Latin or Greek texts. In this study, we introduce SPhilBERTa, a trilingual Sentence-RoBERTa model tailored for Classical Philology, which excels at cross-lingual semantic comprehension and identification of identical sentences across Ancient Greek, Latin, and English. We generate new training data by automatically translating English texts into Ancient Greek. Further, we present a case study, demonstrating SPhilBERTa's capability to facilitate automated detection of intertextual parallels. Our models and resources are available at https://github.com/Heidelberg-NLP/ancient-language-models.
AMR4NLI: Interpretable and robust NLI measures from semantic graphs
Jun 01, 2023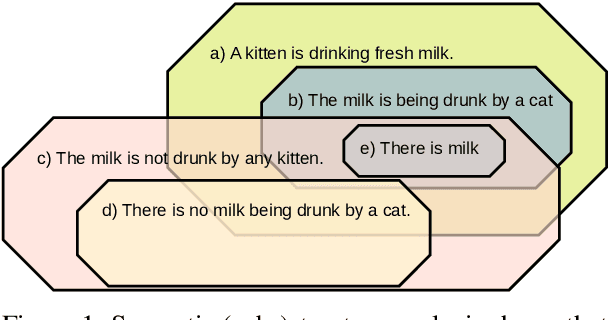
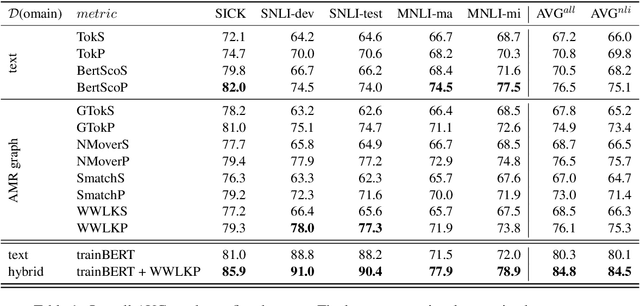
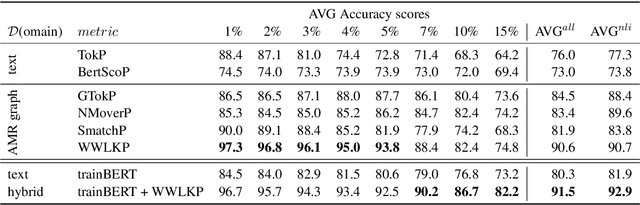
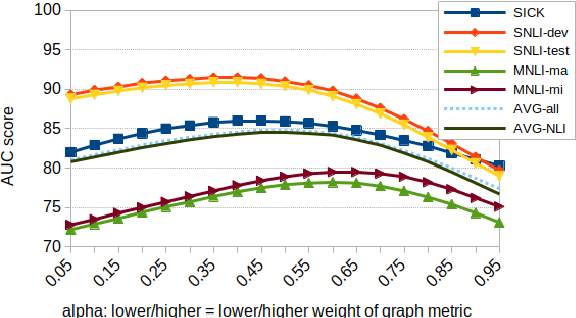
The task of natural language inference (NLI) asks whether a given premise (expressed in NL) entails a given NL hypothesis. NLI benchmarks contain human ratings of entailment, but the meaning relationships driving these ratings are not formalized. Can the underlying sentence pair relationships be made more explicit in an interpretable yet robust fashion? We compare semantic structures to represent premise and hypothesis, including sets of contextualized embeddings and semantic graphs (Abstract Meaning Representations), and measure whether the hypothesis is a semantic substructure of the premise, utilizing interpretable metrics. Our evaluation on three English benchmarks finds value in both contextualized embeddings and semantic graphs; moreover, they provide complementary signals, and can be leveraged together in a hybrid model.