 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeVisE: Behavioral Testing of Medical Large Language Models
Jun 18, 2025Large language models (LLMs) are increasingly used in clinical decision support, yet current evaluation methods often fail to distinguish genuine medical reasoning from superficial patterns. We introduce DeVisE (Demographics and Vital signs Evaluation), a behavioral testing framework for probing fine-grained clinical understanding. We construct a dataset of ICU discharge notes from MIMIC-IV, generating both raw (real-world) and template-based (synthetic) versions with controlled single-variable counterfactuals targeting demographic (age, gender, ethnicity) and vital sign attributes. We evaluate five LLMs spanning general-purpose and medically fine-tuned variants, under both zero-shot and fine-tuned settings. We assess model behavior via (1) input-level sensitivity - how counterfactuals alter the likelihood of a note; and (2) downstream reasoning - how they affect predicted hospital length-of-stay. Our results show that zero-shot models exhibit more coherent counterfactual reasoning patterns, while fine-tuned models tend to be more stable yet less responsive to clinically meaningful changes. Notably, demographic factors subtly but consistently influence outputs, emphasizing the importance of fairness-aware evaluation. This work highlights the utility of behavioral testing in exposing the reasoning strategies of clinical LLMs and informing the design of safer, more transparent medical AI systems.
A Vision-Language Framework for Multispectral Scene Representation Using Language-Grounded Features
Jan 17, 2025Scene understanding in remote sensing often faces challenges in generating accurate representations for complex environments such as various land use areas or coastal regions, which may also include snow, clouds, or haze. To address this, we present a vision-language framework named Spectral LLaVA, which integrates multispectral data with vision-language alignment techniques to enhance scene representation and description. Using the BigEarthNet v2 dataset from Sentinel-2, we establish a baseline with RGB-based scene descriptions and further demonstrate substantial improvements through the incorporation of multispectral information. Our framework optimizes a lightweight linear projection layer for alignment while keeping the vision backbone of SpectralGPT frozen. Our experiments encompass scene classification using linear probing and language modeling for jointly performing scene classification and description generation. Our results highlight Spectral LLaVA's ability to produce detailed and accurate descriptions, particularly for scenarios where RGB data alone proves inadequate, while also enhancing classification performance by refining SpectralGPT features into semantically meaningful representations.
GaussianVideo: Efficient Video Representation via Hierarchical Gaussian Splatting
Jan 08, 2025Efficient neural representations for dynamic video scenes are critical for applications ranging from video compression to interactive simulations. Yet, existing methods often face challenges related to high memory usage, lengthy training times, and temporal consistency. To address these issues, we introduce a novel neural video representation that combines 3D Gaussian splatting with continuous camera motion modeling. By leveraging Neural ODEs, our approach learns smooth camera trajectories while maintaining an explicit 3D scene representation through Gaussians. Additionally, we introduce a spatiotemporal hierarchical learning strategy, progressively refining spatial and temporal features to enhance reconstruction quality and accelerate convergence. This memory-efficient approach achieves high-quality rendering at impressive speeds. Experimental results show that our hierarchical learning, combined with robust camera motion modeling, captures complex dynamic scenes with strong temporal consistency, achieving state-of-the-art performance across diverse video datasets in both high- and low-motion scenarios.
HyperGAN-CLIP: A Unified Framework for Domain Adaptation, Image Synthesis and Manipulation
Nov 19, 2024
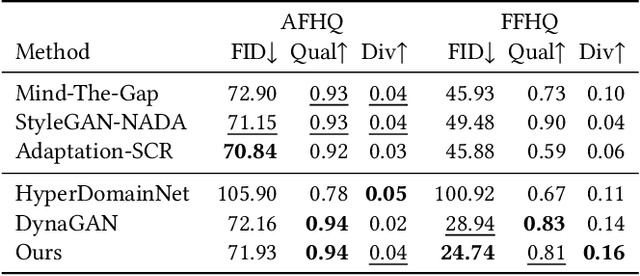
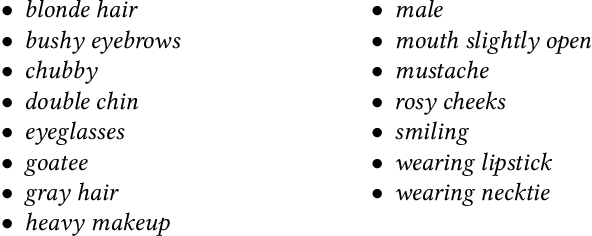
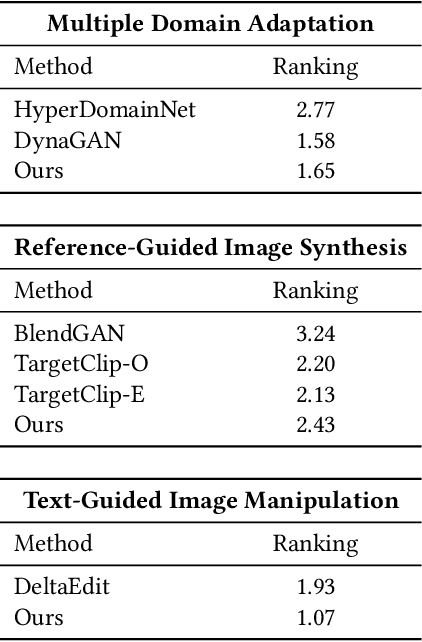
Generative Adversarial Networks (GANs), particularly StyleGAN and its variants, have demonstrated remarkable capabilities in generating highly realistic images. Despite their success, adapting these models to diverse tasks such as domain adaptation, reference-guided synthesis, and text-guided manipulation with limited training data remains challenging. Towards this end, in this study, we present a novel framework that significantly extends the capabilities of a pre-trained StyleGAN by integrating CLIP space via hypernetworks. This integration allows dynamic adaptation of StyleGAN to new domains defined by reference images or textual descriptions. Additionally, we introduce a CLIP-guided discriminator that enhances the alignment between generated images and target domains, ensuring superior image quality. Our approach demonstrates unprecedented flexibility, enabling text-guided image manipulation without the need for text-specific training data and facilitating seamless style transfer. Comprehensive qualitative and quantitative evaluations confirm the robustness and superior performance of our framework compared to existing methods.
HUE Dataset: High-Resolution Event and Frame Sequences for Low-Light Vision
Oct 24, 2024



Low-light environments pose significant challenges for image enhancement methods. To address these challenges, in this work, we introduce the HUE dataset, a comprehensive collection of high-resolution event and frame sequences captured in diverse and challenging low-light conditions. Our dataset includes 106 sequences, encompassing indoor, cityscape, twilight, night, driving, and controlled scenarios, each carefully recorded to address various illumination levels and dynamic ranges. Utilizing a hybrid RGB and event camera setup. we collect a dataset that combines high-resolution event data with complementary frame data. We employ both qualitative and quantitative evaluations using no-reference metrics to assess state-of-the-art low-light enhancement and event-based image reconstruction methods. Additionally, we evaluate these methods on a downstream object detection task. Our findings reveal that while event-based methods perform well in specific metrics, they may produce false positives in practical applications. This dataset and our comprehensive analysis provide valuable insights for future research in low-light vision and hybrid camera systems.
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
Jul 17, 2024The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.
CLIPAway: Harmonizing Focused Embeddings for Removing Objects via Diffusion Models
Jun 13, 2024
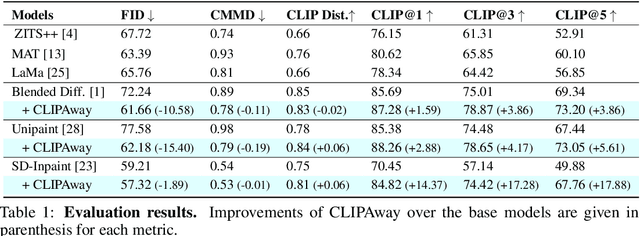


Advanced image editing techniques, particularly inpainting, are essential for seamlessly removing unwanted elements while preserving visual integrity. Traditional GAN-based methods have achieved notable success, but recent advancements in diffusion models have produced superior results due to their training on large-scale datasets, enabling the generation of remarkably realistic inpainted images. Despite their strengths, diffusion models often struggle with object removal tasks without explicit guidance, leading to unintended hallucinations of the removed object. To address this issue, we introduce CLIPAway, a novel approach leveraging CLIP embeddings to focus on background regions while excluding foreground elements. CLIPAway enhances inpainting accuracy and quality by identifying embeddings that prioritize the background, thus achieving seamless object removal. Unlike other methods that rely on specialized training datasets or costly manual annotations, CLIPAway provides a flexible, plug-and-play solution compatible with various diffusion-based inpainting techniques.
SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models
May 01, 2024



We are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. While spatial control using cues such as depth, sketch, and other images has attracted a lot of research, we argue that another equally effective modality is audio since sound and sight are two main components of human perception. Hence, we propose a method to enable audio-conditioning in large scale image diffusion models. Our method first maps features obtained from audio clips to tokens that can be injected into the diffusion model in a fashion similar to text tokens. We introduce additional audio-image cross attention layers which we finetune while freezing the weights of the original layers of the diffusion model. In addition to audio conditioned image generation, our method can also be utilized in conjuction with diffusion based editing methods to enable audio conditioned image editing. We demonstrate our method on a wide range of audio and image datasets. We perform extensive comparisons with recent methods and show favorable performance.
Hippocrates: An Open-Source Framework for Advancing Large Language Models in Healthcare
Apr 25, 2024



The integration of Large Language Models (LLMs) into healthcare promises to transform medical diagnostics, research, and patient care. Yet, the progression of medical LLMs faces obstacles such as complex training requirements, rigorous evaluation demands, and the dominance of proprietary models that restrict academic exploration. Transparent, comprehensive access to LLM resources is essential for advancing the field, fostering reproducibility, and encouraging innovation in healthcare AI. We present Hippocrates, an open-source LLM framework specifically developed for the medical domain. In stark contrast to previous efforts, it offers unrestricted access to its training datasets, codebase, checkpoints, and evaluation protocols. This open approach is designed to stimulate collaborative research, allowing the community to build upon, refine, and rigorously evaluate medical LLMs within a transparent ecosystem. Also, we introduce Hippo, a family of 7B models tailored for the medical domain, fine-tuned from Mistral and LLaMA2 through continual pre-training, instruction tuning, and reinforcement learning from human and AI feedback. Our models outperform existing open medical LLMs models by a large-margin, even surpassing models with 70B parameters. Through Hippocrates, we aspire to unlock the full potential of LLMs not just to advance medical knowledge and patient care but also to democratize the benefits of AI research in healthcare, making them available across the globe.
Sequential Compositional Generalization in Multimodal Models
Apr 18, 2024
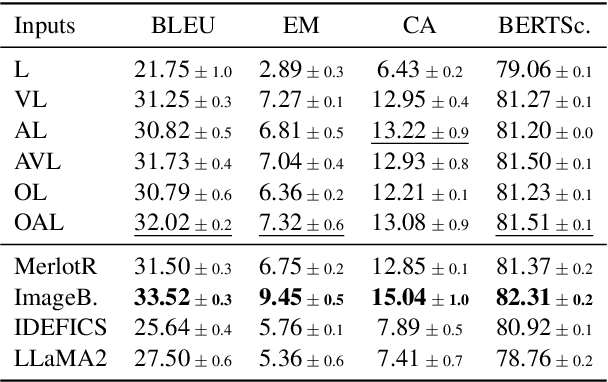
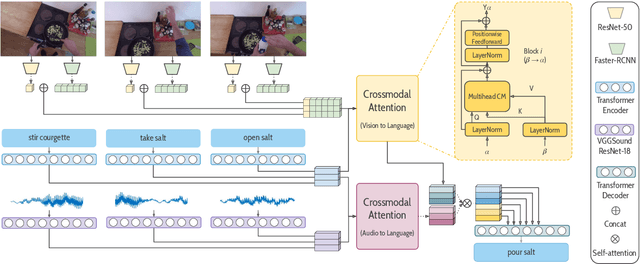
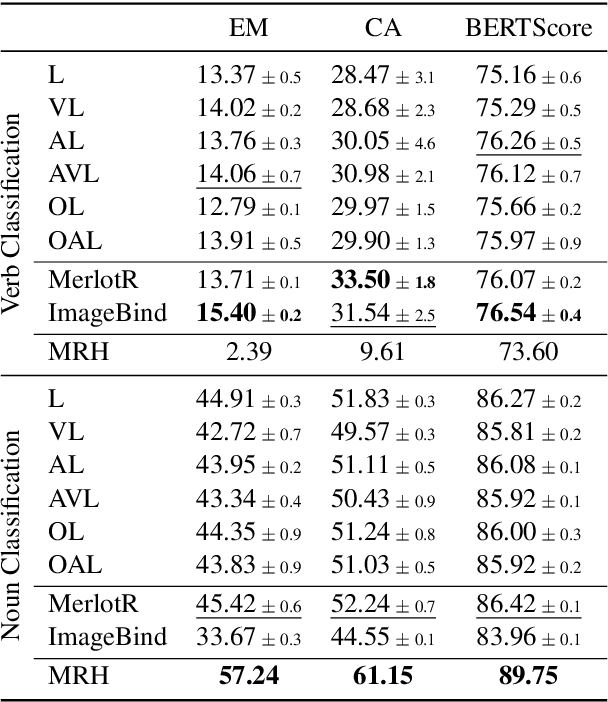
The rise of large-scale multimodal models has paved the pathway for groundbreaking advances in generative modeling and reasoning, unlocking transformative applications in a variety of complex tasks. However, a pressing question that remains is their genuine capability for stronger forms of generalization, which has been largely underexplored in the multimodal setting. Our study aims to address this by examining sequential compositional generalization using \textsc{CompAct} (\underline{Comp}ositional \underline{Act}ivities)\footnote{Project Page: \url{http://cyberiada.github.io/CompAct}}, a carefully constructed, perceptually grounded dataset set within a rich backdrop of egocentric kitchen activity videos. Each instance in our dataset is represented with a combination of raw video footage, naturally occurring sound, and crowd-sourced step-by-step descriptions. More importantly, our setup ensures that the individual concepts are consistently distributed across training and evaluation sets, while their compositions are novel in the evaluation set. We conduct a comprehensive assessment of several unimodal and multimodal models. Our findings reveal that bi-modal and tri-modal models exhibit a clear edge over their text-only counterparts. This highlights the importance of multimodality while charting a trajectory for future research in this domain.