 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
Bounding Hallucinations: Information-Theoretic Guarantees for RAG Systems via Merlin-Arthur Protocols
Dec 12, 2025Retrieval-augmented generation (RAG) models rely on retrieved evidence to guide large language model (LLM) generators, yet current systems treat retrieval as a weak heuristic rather than verifiable evidence. As a result, LLMs answer without support, hallucinate under incomplete or misleading context, and rely on spurious evidence. We introduce a training framework that treats the entire RAG pipeline -- both the retriever and the generator -- as an interactive proof system via an adaptation of the Merlin-Arthur (M/A) protocol. Arthur (the generator LLM) trains on questions of unkown provenance: Merlin provides helpful evidence, while Morgana injects adversarial, misleading context. Both use a linear-time XAI method to identify and modify the evidence most influential to Arthur. Consequently, Arthur learns to (i) answer when the context support the answer, (ii) reject when evidence is insufficient, and (iii) rely on the specific context spans that truly ground the answer. We further introduce a rigorous evaluation framework to disentangle explanation fidelity from baseline predictive errors. This allows us to introduce and measure the Explained Information Fraction (EIF), which normalizes M/A certified mutual-information guarantees relative to model capacity and imperfect benchmarks. Across three RAG datasets and two model families of varying sizes, M/A-trained LLMs show improved groundedness, completeness, soundness, and reject behavior, as well as reduced hallucinations -- without needing manually annotated unanswerable questions. The retriever likewise improves recall and MRR through automatically generated M/A hard positives and negatives. Our results demonstrate that autonomous interactive-proof-style supervision provides a principled and practical path toward reliable RAG systems that treat retrieved documents not as suggestions, but as verifiable evidence.
Aleph-Alpha-GermanWeb: Improving German-language LLM pre-training with model-based data curation and synthetic data generation
Apr 24, 2025



Scaling data quantity is essential for large language models (LLMs), yet recent findings show that data quality can significantly boost performance and training efficiency. We introduce a German-language dataset curation pipeline that combines heuristic and model-based filtering techniques with synthetic data generation. We use our pipeline to create Aleph-Alpha-GermanWeb, a large-scale German pre-training dataset which draws from: (1) Common Crawl web data, (2) FineWeb2, and (3) synthetically-generated data conditioned on actual, organic web data. We evaluate our dataset by pre-training both a 1B Llama-style model and an 8B tokenizer-free hierarchical autoregressive transformer (HAT). A comparison on German-language benchmarks, including MMMLU, shows significant performance gains of Aleph-Alpha-GermanWeb over FineWeb2 alone. This advantage holds at the 8B scale even when FineWeb2 is enriched by human-curated high-quality data sources such as Wikipedia. Our findings support the growing body of evidence that model-based data curation and synthetic data generation can significantly enhance LLM pre-training datasets.
Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
Apr 29, 2024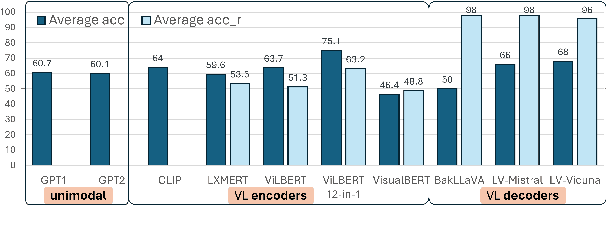
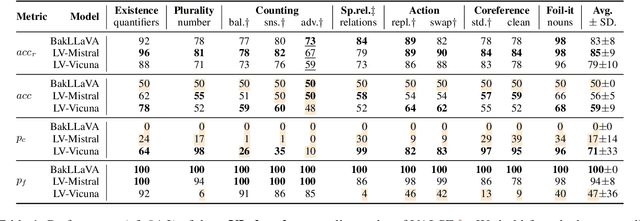
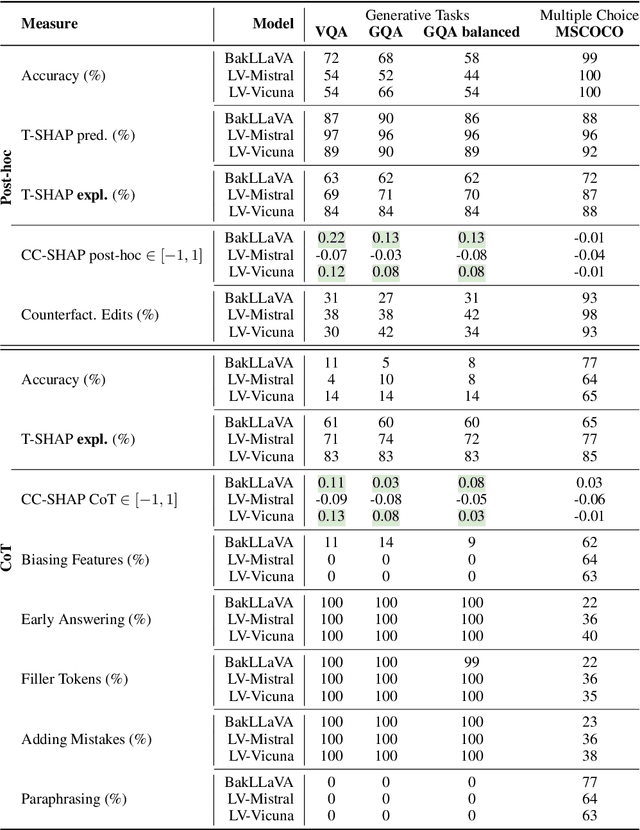
Vision and language models (VLMs) are currently the most generally performant architectures on multimodal tasks. Next to their predictions, they can also produce explanations, either in post-hoc or CoT settings. However, it is not clear how much they use the vision and text modalities when generating predictions or explanations. In this work, we investigate if VLMs rely on modalities differently when generating explanations as opposed to when they provide answers. We also evaluate the self-consistency of VLM decoders in both post-hoc and CoT explanation settings, by extending existing tests and measures to VLM decoders. We find that VLMs are less self-consistent than LLMs. The text contributions in VL decoders are much larger than the image contributions across all measured tasks. And the contributions of the image are significantly larger for explanation generations than for answer generation. This difference is even larger in CoT compared to the post-hoc explanation setting. We also provide an up-to-date benchmarking of state-of-the-art VL decoders on the VALSE benchmark, which to date focused only on VL encoders. We find that VL decoders are still struggling with most phenomena tested by VALSE.
On Measuring Faithfulness of Natural Language Explanations
Nov 13, 2023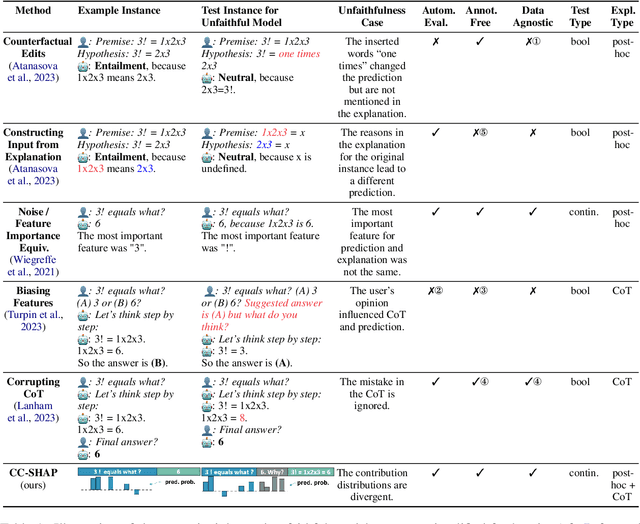
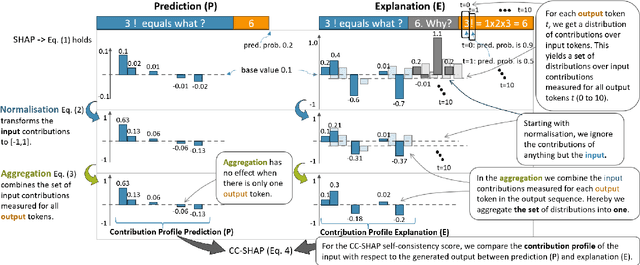
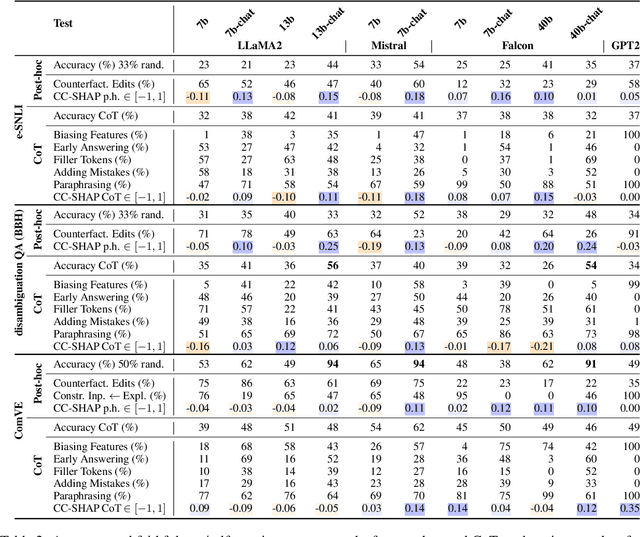
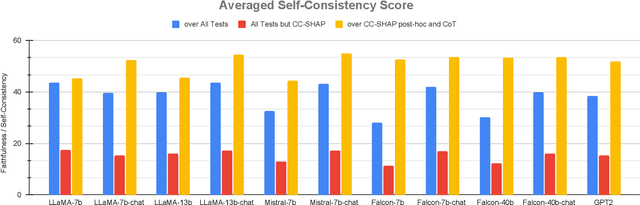
Large language models (LLMs) can explain their own predictions, through post-hoc or Chain-of-Thought (CoT) explanations. However the LLM could make up reasonably sounding explanations that are unfaithful to its underlying reasoning. Recent work has designed tests that aim to judge the faithfulness of either post-hoc or CoT explanations. In this paper we argue that existing faithfulness tests are not actually measuring faithfulness in terms of the models' inner workings, but only evaluate their self-consistency on the output level. The aims of our work are two-fold. i) We aim to clarify the status of existing faithfulness tests in terms of model explainability, characterising them as self-consistency tests instead. This assessment we underline by constructing a Comparative Consistency Bank for self-consistency tests that for the first time compares existing tests on a common suite of 11 open-source LLMs and 5 datasets -- including ii) our own proposed self-consistency measure CC-SHAP. CC-SHAP is a new fine-grained measure (not test) of LLM self-consistency that compares a model's input contributions to answer prediction and generated explanation. With CC-SHAP, we aim to take a step further towards measuring faithfulness with a more interpretable and fine-grained method. Code available at \url{https://github.com/Heidelberg-NLP/CC-SHAP}
ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
Nov 13, 2023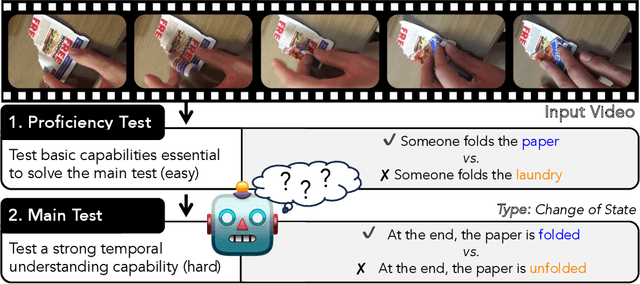
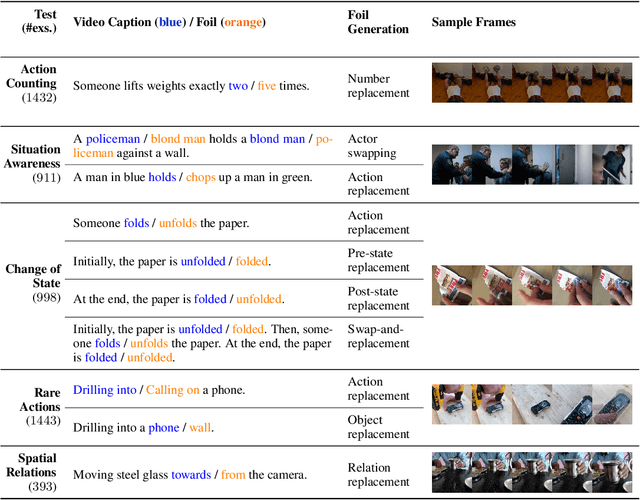
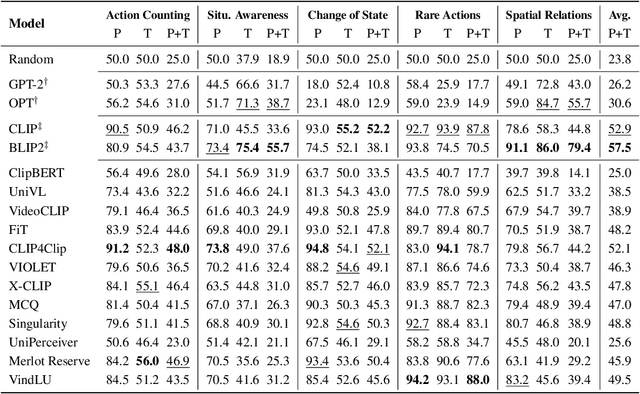

With the ever-increasing popularity of pretrained Video-Language Models (VidLMs), there is a pressing need to develop robust evaluation methodologies that delve deeper into their visio-linguistic capabilities. To address this challenge, we present ViLMA (Video Language Model Assessment), a task-agnostic benchmark that places the assessment of fine-grained capabilities of these models on a firm footing. Task-based evaluations, while valuable, fail to capture the complexities and specific temporal aspects of moving images that VidLMs need to process. Through carefully curated counterfactuals, ViLMA offers a controlled evaluation suite that sheds light on the true potential of these models, as well as their performance gaps compared to human-level understanding. ViLMA also includes proficiency tests, which assess basic capabilities deemed essential to solving the main counterfactual tests. We show that current VidLMs' grounding abilities are no better than those of vision-language models which use static images. This is especially striking once the performance on proficiency tests is factored in. Our benchmark serves as a catalyst for future research on VidLMs, helping to highlight areas that still need to be explored.
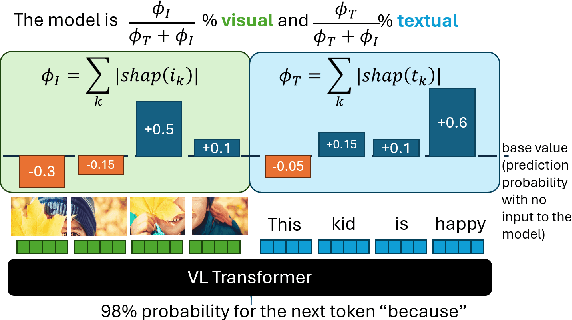
MM-SHAP: A Performance-agnostic Metric for Measuring Multimodal Contributions in Vision and Language Models & Tasks
Dec 15, 2022
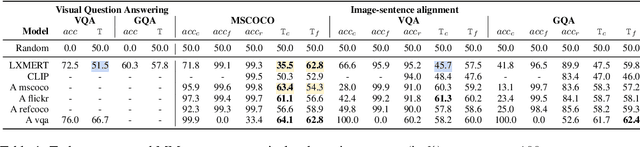
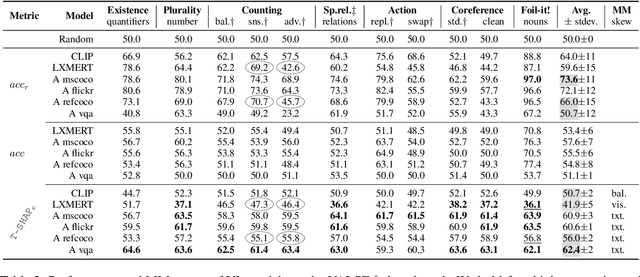
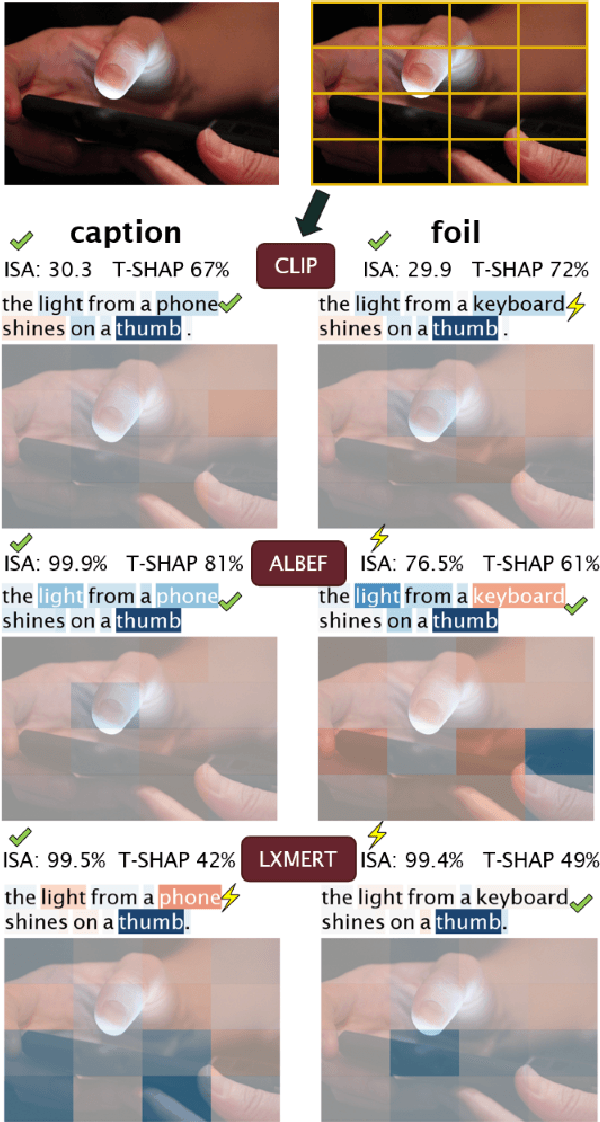
Vision and language models (VL) are known to exploit unrobust indicators in individual modalities (e.g., introduced by distributional biases), instead of focusing on relevant information in each modality. A small drop in accuracy obtained on a VL task with a unimodal model suggests that so-called unimodal collapse occurred. But how to quantify the amount of unimodal collapse reliably, at dataset and instance-level, to diagnose and combat unimodal collapse in a targeted way? We present MM-SHAP, a performance-agnostic multimodality score that quantifies the proportion by which a model uses individual modalities in multimodal tasks. MM-SHAP is based on Shapley values and will be applied in two ways: (1) to compare models for their degree of multimodality, and (2) to measure the contribution of individual modalities for a given task and dataset. Experiments with 6 VL models -- LXMERT, CLIP and four ALBEF variants -- on four VL tasks highlight that unimodal collapse can occur to different degrees and in different directions, contradicting the wide-spread assumption that unimodal collapse is one-sided. We recommend MM-SHAP for analysing multimodal tasks, to diagnose and guide progress towards multimodal integration. Code available at: https://github.com/Heidelberg-NLP/MM-SHAP
VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
Dec 14, 2021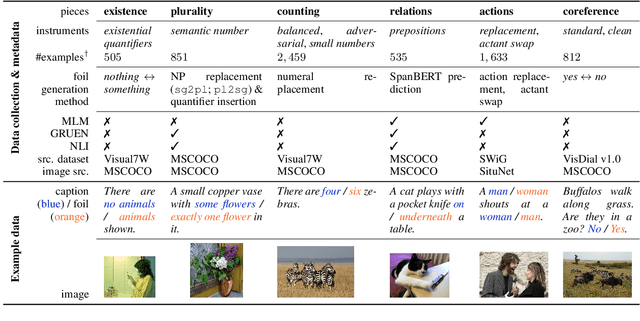
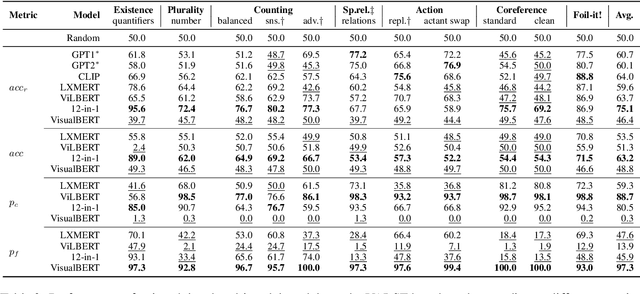
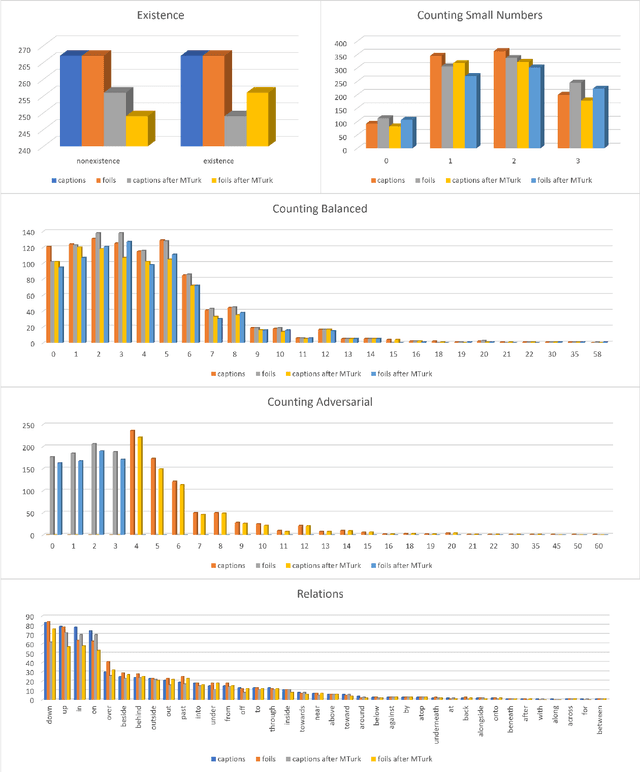
We propose VALSE (Vision And Language Structured Evaluation), a novel benchmark designed for testing general-purpose pretrained vision and language (V&L) models for their visio-linguistic grounding capabilities on specific linguistic phenomena. VALSE offers a suite of six tests covering various linguistic constructs. Solving these requires models to ground linguistic phenomena in the visual modality, allowing more fine-grained evaluations than hitherto possible. We build VALSE using methods that support the construction of valid foils, and report results from evaluating five widely-used V&L models. Our experiments suggest that current models have considerable difficulty addressing most phenomena. Hence, we expect VALSE to serve as an important benchmark to measure future progress of pretrained V&L models from a linguistic perspective, complementing the canonical task-centred V&L evaluations.
MAGMA -- Multimodal Augmentation of Generative Models through Adapter-based Finetuning
Dec 09, 2021
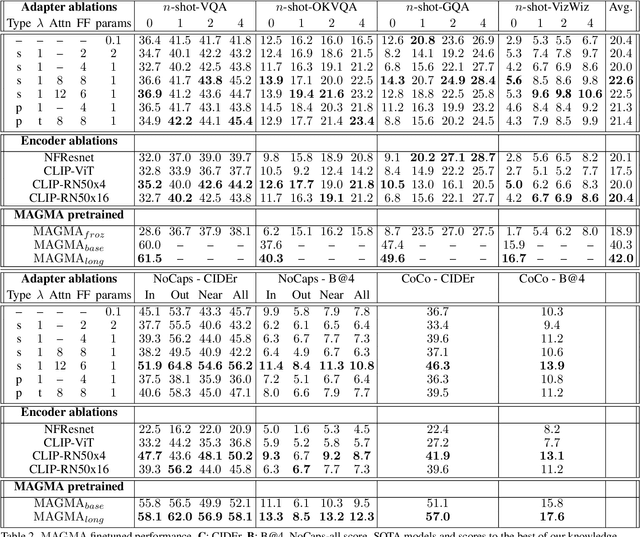
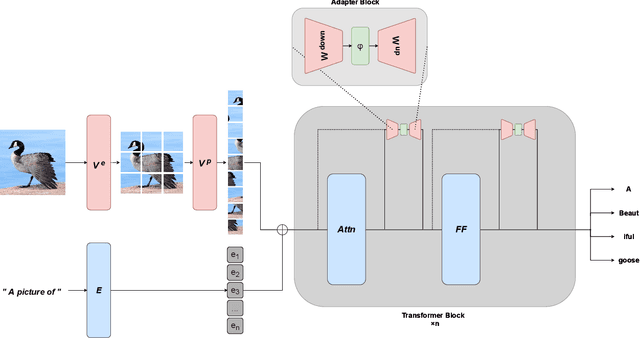

Large-scale pretraining is fast becoming the norm in Vision-Language (VL) modeling. However, prevailing VL approaches are limited by the requirement for labeled data and the use of complex multi-step pretraining objectives. We present MAGMA - a simple method for augmenting generative language models with additional modalities using adapter-based finetuning. Building on Frozen, we train a series of VL models that autoregressively generate text from arbitrary combinations of visual and textual input. The pretraining is entirely end-to-end using a single language modeling objective, simplifying optimization compared to previous approaches. Importantly, the language model weights remain unchanged during training, allowing for transfer of encyclopedic knowledge and in-context learning abilities from language pretraining. MAGMA outperforms Frozen on open-ended generative tasks, achieving state of the art results on the OKVQA benchmark and competitive results on a range of other popular VL benchmarks, while pretraining on 0.2% of the number of samples used to train SimVLM.
What is Multimodality?
Mar 10, 2021
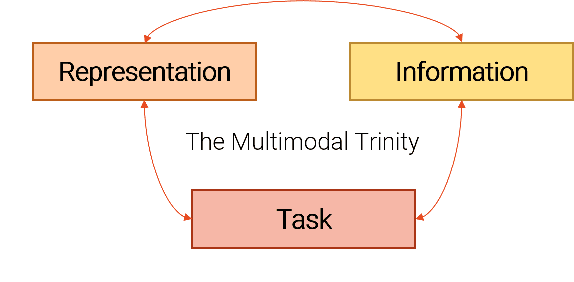
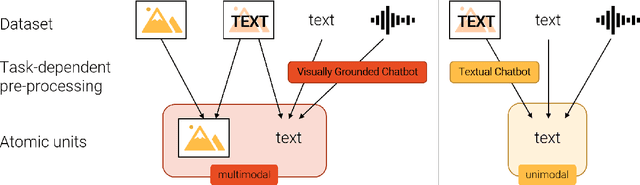
The last years have shown rapid developments in the field of multimodal machine learning, combining e.g., vision, text or speech. In this position paper we explain how the field uses outdated definitions of multimodality that prove unfit for the machine learning era. We propose a new task-relative definition of (multi)modality in the context of multimodal machine learning that focuses on representations and information that are relevant for a given machine learning task. With our new definition of multimodality we aim to provide a missing foundation for multimodal research, an important component of language grounding and a crucial milestone towards NLU.