 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Measuring Faithfulness of Natural Language Explanations
Paper and Code
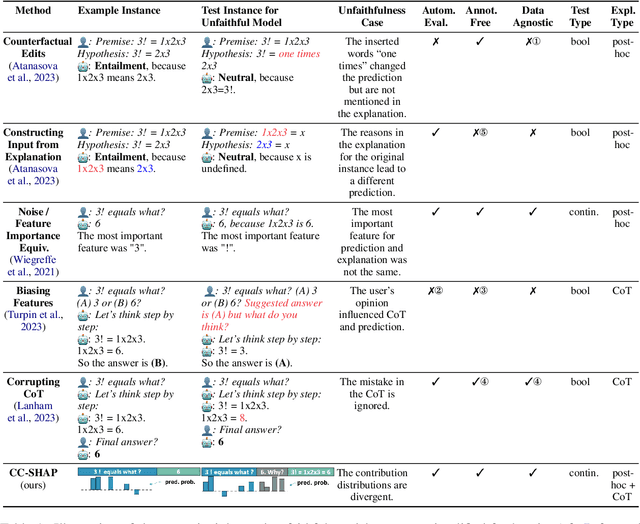
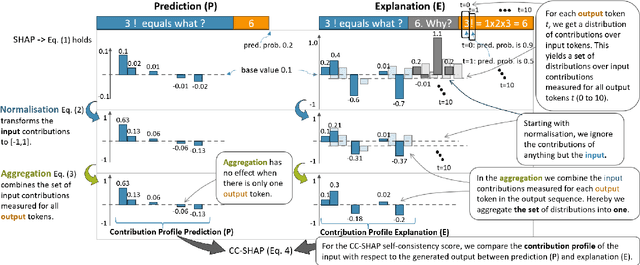
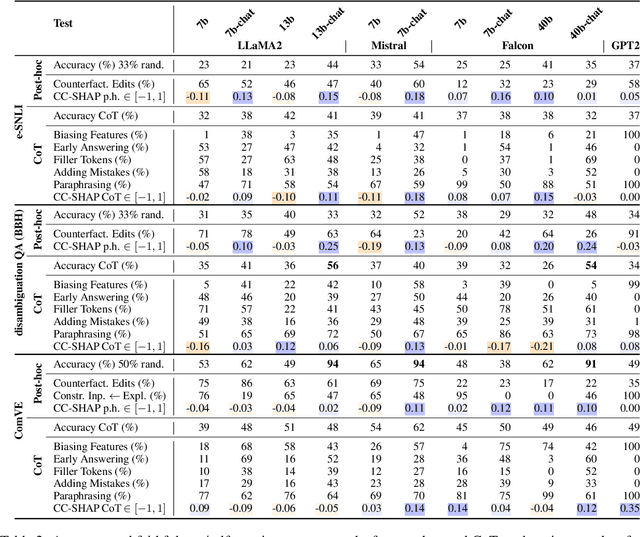
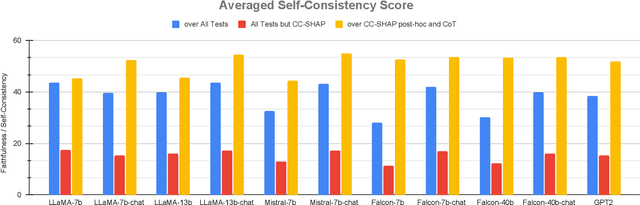
Large language models (LLMs) can explain their own predictions, through post-hoc or Chain-of-Thought (CoT) explanations. However the LLM could make up reasonably sounding explanations that are unfaithful to its underlying reasoning. Recent work has designed tests that aim to judge the faithfulness of either post-hoc or CoT explanations. In this paper we argue that existing faithfulness tests are not actually measuring faithfulness in terms of the models' inner workings, but only evaluate their self-consistency on the output level. The aims of our work are two-fold. i) We aim to clarify the status of existing faithfulness tests in terms of model explainability, characterising them as self-consistency tests instead. This assessment we underline by constructing a Comparative Consistency Bank for self-consistency tests that for the first time compares existing tests on a common suite of 11 open-source LLMs and 5 datasets -- including ii) our own proposed self-consistency measure CC-SHAP. CC-SHAP is a new fine-grained measure (not test) of LLM self-consistency that compares a model's input contributions to answer prediction and generated explanation. With CC-SHAP, we aim to take a step further towards measuring faithfulness with a more interpretable and fine-grained method. Code available at \url{https://github.com/Heidelberg-NLP/CC-SHAP}