 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing past words: Testing the cross-modal capabilities of pretrained V&L models
Paper and Code
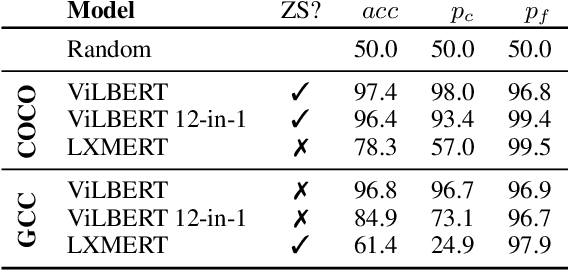


We investigate the ability of general-purpose pretrained vision and language V&L models to perform reasoning in two tasks that require multimodal integration: (1) discriminating a correct image-sentence pair from an incorrect one, and (2) counting entities in an image. We evaluate three pretrained V&L models on these tasks: ViLBERT, ViLBERT 12-in-1 and LXMERT, in zero-shot and finetuned settings. Our results show that models solve task (1) very well, as expected, since all models use task (1) for pretraining. However, none of the pretrained V&L models are able to adequately solve task (2), our counting probe, and they cannot generalise to out-of-distribution quantities. Our investigations suggest that pretrained V&L representations are less successful than expected at integrating the two modalities. We propose a number of explanations for these findings: LXMERT's results on the image-sentence alignment task (and to a lesser extent those obtained by ViLBERT 12-in-1) indicate that the model may exhibit catastrophic forgetting. As for our results on the counting probe, we find evidence that all models are impacted by dataset bias, and also fail to individuate entities in the visual input.