 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private De-identification of Dutch Clinical Notes: A Comparative Evaluation
Apr 23, 2026Protecting patient privacy in clinical narratives is essential for enabling secondary use of healthcare data under regulations such as GDPR and HIPAA. While manual de-identification remains the gold standard, it is costly and slow, motivating the need for automated methods that combine privacy guarantees with high utility. Most automated text de-identification pipelines employed named entity recognition (NER) to identify protected entities for redaction. Although methods based on differential privacy (DP) provide formal privacy guarantees, more recently also large language models (LLMs) are increasingly used for text de-identification in the clinical domain. In this work, we present the first comparative study of DP, NER, and LLMs for Dutch clinical text de-identification. We investigate these methods separately as well as hybrid strategies that apply NER or LLM preprocessing prior to DP, and assess performance in terms of privacy leakage and extrinsic evaluation (entity and relation classification). We show that DP mechanisms alone degrade utility substantially, but combining them with linguistic preprocessing, especially LLM-based redaction, significantly improves the privacy-utility trade-off.
FewMMBench: A Benchmark for Multimodal Few-Shot Learning
Feb 25, 2026As multimodal large language models (MLLMs) advance in handling interleaved image-text data, assessing their few-shot learning capabilities remains an open challenge. In this paper, we introduce FewMMBench, a comprehensive benchmark designed to evaluate MLLMs under few-shot conditions, with a focus on In-Context Learning (ICL) and Chain-of-Thought (CoT) prompting. Covering a diverse suite of multimodal understanding tasks, from attribute recognition to temporal reasoning, FewMMBench enables systematic analysis across task types, model families, and prompting strategies. We evaluate 26 open-weight MLLMs from six model families across zero-shot, few-shot, and CoT-augmented few-shot settings. Our findings reveal that instruction-tuned models exhibit strong zero-shot performance but benefit minimally, or even regress, with additional demonstrations or CoT reasoning. Retrieval-based demonstrations and increased context size also yield limited gains. These results highlight FewMMBench as a rigorous testbed for diagnosing and advancing few-shot capabilities in multimodal LLMs. The data is available at: https://huggingface.co/datasets/mustafaa/FewMMBench
MedPath: Multi-Domain Cross-Vocabulary Hierarchical Paths for Biomedical Entity Linking
Nov 14, 2025Progress in biomedical Named Entity Recognition (NER) and Entity Linking (EL) is currently hindered by a fragmented data landscape, a lack of resources for building explainable models, and the limitations of semantically-blind evaluation metrics. To address these challenges, we present MedPath, a large-scale and multi-domain biomedical EL dataset that builds upon nine existing expert-annotated EL datasets. In MedPath, all entities are 1) normalized using the latest version of the Unified Medical Language System (UMLS), 2) augmented with mappings to 62 other biomedical vocabularies and, crucially, 3) enriched with full ontological paths -- i.e., from general to specific -- in up to 11 biomedical vocabularies. MedPath directly enables new research frontiers in biomedical NLP, facilitating training and evaluation of semantic-rich and interpretable EL systems, and the development of the next generation of interoperable and explainable clinical NLP models.
DeVisE: Behavioral Testing of Medical Large Language Models
Jun 18, 2025Large language models (LLMs) are increasingly used in clinical decision support, yet current evaluation methods often fail to distinguish genuine medical reasoning from superficial patterns. We introduce DeVisE (Demographics and Vital signs Evaluation), a behavioral testing framework for probing fine-grained clinical understanding. We construct a dataset of ICU discharge notes from MIMIC-IV, generating both raw (real-world) and template-based (synthetic) versions with controlled single-variable counterfactuals targeting demographic (age, gender, ethnicity) and vital sign attributes. We evaluate five LLMs spanning general-purpose and medically fine-tuned variants, under both zero-shot and fine-tuned settings. We assess model behavior via (1) input-level sensitivity - how counterfactuals alter the likelihood of a note; and (2) downstream reasoning - how they affect predicted hospital length-of-stay. Our results show that zero-shot models exhibit more coherent counterfactual reasoning patterns, while fine-tuned models tend to be more stable yet less responsive to clinically meaningful changes. Notably, demographic factors subtly but consistently influence outputs, emphasizing the importance of fairness-aware evaluation. This work highlights the utility of behavioral testing in exposing the reasoning strategies of clinical LLMs and informing the design of safer, more transparent medical AI systems.
Different Questions, Different Models: Fine-Grained Evaluation of Uncertainty and Calibration in Clinical QA with LLMs
Jun 12, 2025



Accurate and well-calibrated uncertainty estimates are essential for deploying large language models (LLMs) in high-stakes domains such as clinical decision support. We present a fine-grained evaluation of uncertainty estimation methods for clinical multiple-choice question answering, covering ten open-source LLMs (general-purpose, biomedical, and reasoning models) across two datasets, eleven medical specialties, and six question types. We compare standard single-generation and sampling-based methods, and present a case study exploring simple, single-pass estimators based on behavioral signals in reasoning traces. These lightweight methods approach the performance of Semantic Entropy while requiring only one generation. Our results reveal substantial variation across specialties and question types, underscoring the importance of selecting models based on both the nature of the question and model-specific strengths.
Interpretable phenotyping of Heart Failure patients with Dutch discharge letters
May 30, 2025



Objective: Heart failure (HF) patients present with diverse phenotypes affecting treatment and prognosis. This study evaluates models for phenotyping HF patients based on left ventricular ejection fraction (LVEF) classes, using structured and unstructured data, assessing performance and interpretability. Materials and Methods: The study analyzes all HF hospitalizations at both Amsterdam UMC hospitals (AMC and VUmc) from 2015 to 2023 (33,105 hospitalizations, 16,334 patients). Data from AMC were used for model training, and from VUmc for external validation. The dataset was unlabelled and included tabular clinical measurements and discharge letters. Silver labels for LVEF classes were generated by combining diagnosis codes, echocardiography results, and textual mentions. Gold labels were manually annotated for 300 patients for testing. Multiple Transformer-based (black-box) and Aug-Linear (white-box) models were trained and compared with baselines on structured and unstructured data. To evaluate interpretability, two clinicians annotated 20 discharge letters by highlighting information they considered relevant for LVEF classification. These were compared to SHAP and LIME explanations from black-box models and the inherent explanations of Aug-Linear models. Results: BERT-based and Aug-Linear models, using discharge letters alone, achieved the highest classification results (AUC=0.84 for BERT, 0.81 for Aug-Linear on external validation), outperforming baselines. Aug-Linear explanations aligned more closely with clinicians' explanations than post-hoc explanations on black-box models. Conclusions: Discharge letters emerged as the most informative source for phenotyping HF patients. Aug-Linear models matched black-box performance while providing clinician-aligned interpretability, supporting their use in transparent clinical decision-making.
What Does Neuro Mean to Cardio? Investigating the Role of Clinical Specialty Data in Medical LLMs
May 15, 2025In this paper, we introduce S-MedQA, an English medical question-answering (QA) dataset for benchmarking large language models in fine-grained clinical specialties. We use S-MedQA to check the applicability of a popular hypothesis related to knowledge injection in the knowledge-intense scenario of medical QA, and show that: 1) training on data from a speciality does not necessarily lead to best performance on that specialty and 2) regardless of the specialty fine-tuned on, token probabilities of clinically relevant terms for all specialties increase consistently. Thus, we believe improvement gains come mostly from domain shifting (e.g., general to medical) rather than knowledge injection and suggest rethinking the role of fine-tuning data in the medical domain. We release S-MedQA and all code needed to reproduce all our experiments to the research community.
AnyMatch -- Efficient Zero-Shot Entity Matching with a Small Language Model
Sep 09, 2024
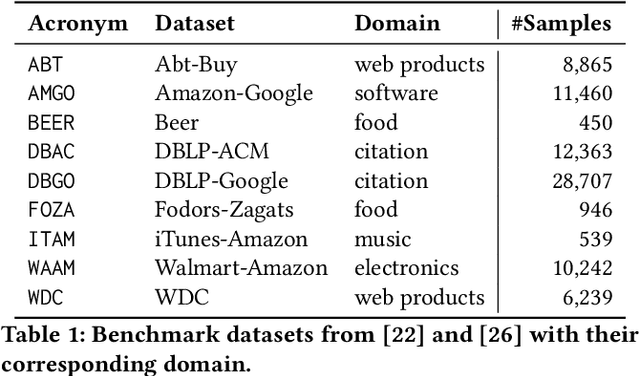
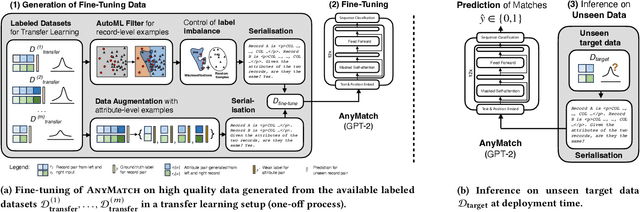
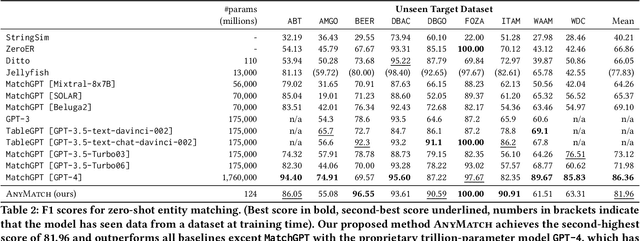
Entity matching (EM) is the problem of determining whether two records refer to same real-world entity, which is crucial in data integration, e.g., for product catalogs or address databases. A major drawback of many EM approaches is their dependence on labelled examples. We thus focus on the challenging setting of zero-shot entity matching where no labelled examples are available for an unseen target dataset. Recently, large language models (LLMs) have shown promising results for zero-shot EM, but their low throughput and high deployment cost limit their applicability and scalability. We revisit the zero-shot EM problem with AnyMatch, a small language model fine-tuned in a transfer learning setup. We propose several novel data selection techniques to generate fine-tuning data for our model, e.g., by selecting difficult pairs to match via an AutoML filter, by generating additional attribute-level examples, and by controlling label imbalance in the data. We conduct an extensive evaluation of the prediction quality and deployment cost of our model, in a comparison to thirteen baselines on nine benchmark datasets. We find that AnyMatch provides competitive prediction quality despite its small parameter size: it achieves the second-highest F1 score overall, and outperforms several other approaches that employ models with hundreds of billions of parameters. Furthermore, our approach exhibits major cost benefits: the average prediction quality of AnyMatch is within 4.4% of the state-of-the-art method MatchGPT with the proprietary trillion-parameter model GPT-4, yet AnyMatch requires four orders of magnitude less parameters and incurs a 3,899 times lower inference cost (in dollars per 1,000 tokens).
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
Jul 17, 2024The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.
LLM aided semi-supervision for Extractive Dialog Summarization
Nov 23, 2023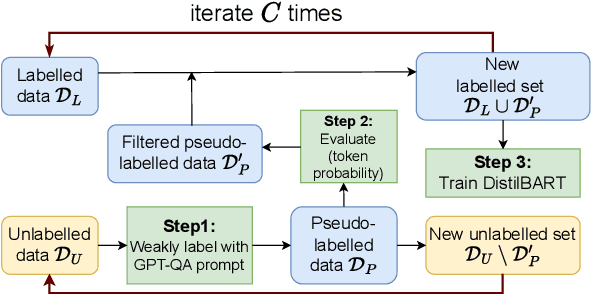
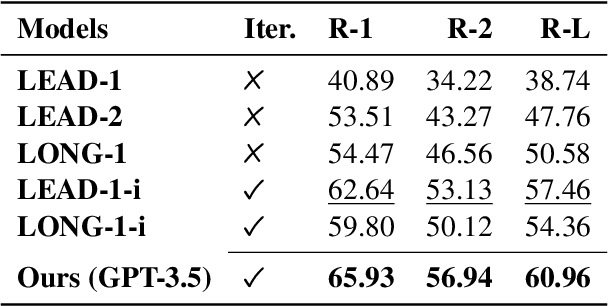
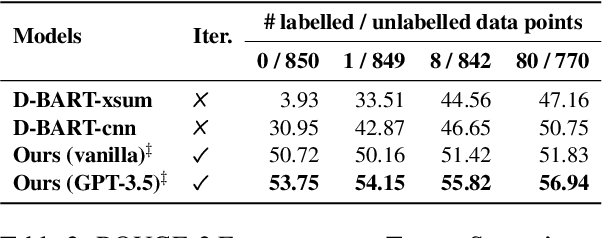

Generating high-quality summaries for chat dialogs often requires large labeled datasets. We propose a method to efficiently use unlabeled data for extractive summarization of customer-agent dialogs. In our method, we frame summarization as a question-answering problem and use state-of-the-art large language models (LLMs) to generate pseudo-labels for a dialog. We then use these pseudo-labels to fine-tune a chat summarization model, effectively transferring knowledge from the large LLM into a smaller specialized model. We demonstrate our method on the \tweetsumm dataset, and show that using 10% of the original labelled data set we can achieve 65.9/57.0/61.0 ROUGE-1/-2/-L, whereas the current state-of-the-art trained on the entire training data set obtains 65.16/55.81/64.37 ROUGE-1/-2/-L. In other words, in the worst case (i.e., ROUGE-L) we still effectively retain 94.7% of the performance while using only 10% of the data.