 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedPath: Multi-Domain Cross-Vocabulary Hierarchical Paths for Biomedical Entity Linking
Nov 14, 2025Progress in biomedical Named Entity Recognition (NER) and Entity Linking (EL) is currently hindered by a fragmented data landscape, a lack of resources for building explainable models, and the limitations of semantically-blind evaluation metrics. To address these challenges, we present MedPath, a large-scale and multi-domain biomedical EL dataset that builds upon nine existing expert-annotated EL datasets. In MedPath, all entities are 1) normalized using the latest version of the Unified Medical Language System (UMLS), 2) augmented with mappings to 62 other biomedical vocabularies and, crucially, 3) enriched with full ontological paths -- i.e., from general to specific -- in up to 11 biomedical vocabularies. MedPath directly enables new research frontiers in biomedical NLP, facilitating training and evaluation of semantic-rich and interpretable EL systems, and the development of the next generation of interoperable and explainable clinical NLP models.
LLM aided semi-supervision for Extractive Dialog Summarization
Nov 23, 2023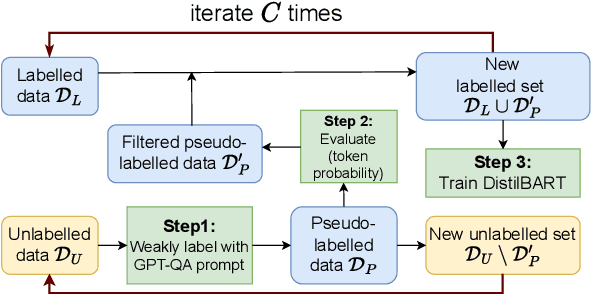
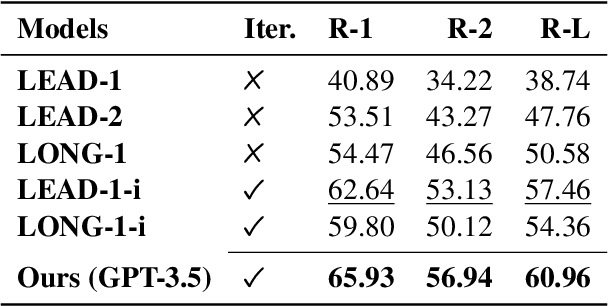
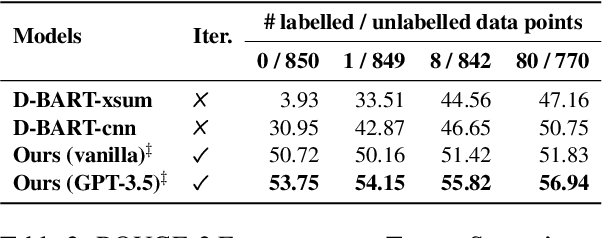

Generating high-quality summaries for chat dialogs often requires large labeled datasets. We propose a method to efficiently use unlabeled data for extractive summarization of customer-agent dialogs. In our method, we frame summarization as a question-answering problem and use state-of-the-art large language models (LLMs) to generate pseudo-labels for a dialog. We then use these pseudo-labels to fine-tune a chat summarization model, effectively transferring knowledge from the large LLM into a smaller specialized model. We demonstrate our method on the \tweetsumm dataset, and show that using 10% of the original labelled data set we can achieve 65.9/57.0/61.0 ROUGE-1/-2/-L, whereas the current state-of-the-art trained on the entire training data set obtains 65.16/55.81/64.37 ROUGE-1/-2/-L. In other words, in the worst case (i.e., ROUGE-L) we still effectively retain 94.7% of the performance while using only 10% of the data.
Fixing confirmation bias in feature attribution methods via semantic match
Jul 03, 2023
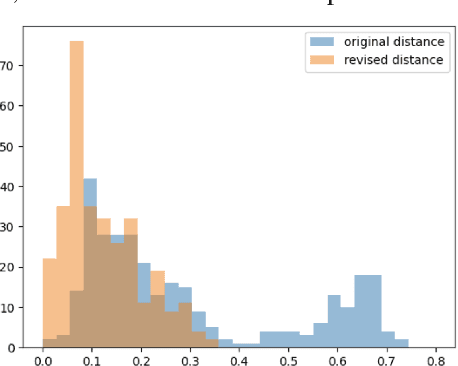
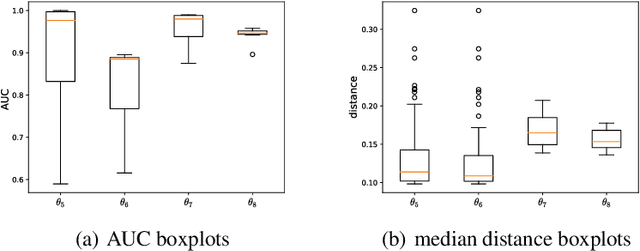
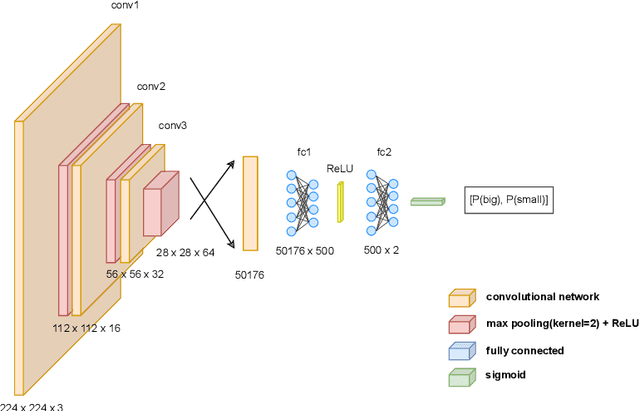
Feature attribution methods have become a staple method to disentangle the complex behavior of black box models. Despite their success, some scholars have argued that such methods suffer from a serious flaw: they do not allow a reliable interpretation in terms of human concepts. Simply put, visualizing an array of feature contributions is not enough for humans to conclude something about a model's internal representations, and confirmation bias can trick users into false beliefs about model behavior. We argue that a structured approach is required to test whether our hypotheses on the model are confirmed by the feature attributions. This is what we call the "semantic match" between human concepts and (sub-symbolic) explanations. Building on the conceptual framework put forward in Cin\`a et al. [2023], we propose a structured approach to evaluate semantic match in practice. We showcase the procedure in a suite of experiments spanning tabular and image data, and show how the assessment of semantic match can give insight into both desirable (e.g., focusing on an object relevant for prediction) and undesirable model behaviors (e.g., focusing on a spurious correlation). We couple our experimental results with an analysis on the metrics to measure semantic match, and argue that this approach constitutes the first step towards resolving the issue of confirmation bias in XAI.