 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentAda: Skill-Adaptive Data Analytics for Tailored Insight Discovery
Apr 10, 2025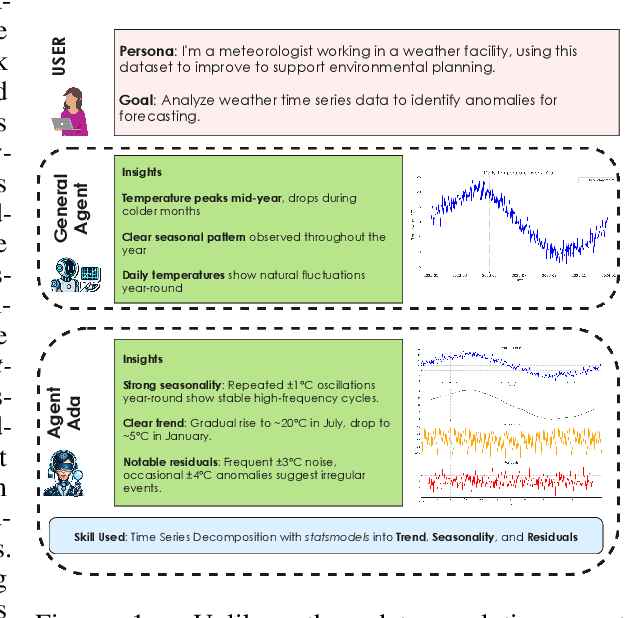

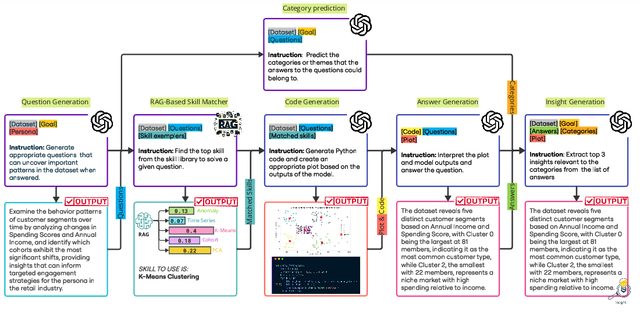
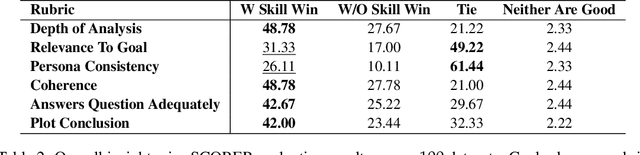
We introduce AgentAda, the first LLM-powered analytics agent that can learn and use new analytics skills to extract more specialized insights. Unlike existing methods that require users to manually decide which data analytics method to apply, AgentAda automatically identifies the skill needed from a library of analytical skills to perform the analysis. This also allows AgentAda to use skills that existing LLMs cannot perform out of the box. The library covers a range of methods, including clustering, predictive modeling, and NLP techniques like BERT, which allow AgentAda to handle complex analytics tasks based on what the user needs. AgentAda's dataset-to-insight extraction strategy consists of three key steps: (I) a question generator to generate queries relevant to the user's goal and persona, (II) a hybrid Retrieval-Augmented Generation (RAG)-based skill matcher to choose the best data analytics skill from the skill library, and (III) a code generator that produces executable code based on the retrieved skill's documentation to extract key patterns. We also introduce KaggleBench, a benchmark of curated notebooks across diverse domains, to evaluate AgentAda's performance. We conducted a human evaluation demonstrating that AgentAda provides more insightful analytics than existing tools, with 48.78% of evaluators preferring its analyses, compared to 27.67% for the unskilled agent. We also propose a novel LLM-as-a-judge approach that we show is aligned with human evaluation as a way to automate insight quality evaluation at larger scale.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
LLMs for Literature Review: Are we there yet?
Dec 15, 2024



Literature reviews are an essential component of scientific research, but they remain time-intensive and challenging to write, especially due to the recent influx of research papers. This paper explores the zero-shot abilities of recent Large Language Models (LLMs) in assisting with the writing of literature reviews based on an abstract. We decompose the task into two components: 1. Retrieving related works given a query abstract, and 2. Writing a literature review based on the retrieved results. We analyze how effective LLMs are for both components. For retrieval, we introduce a novel two-step search strategy that first uses an LLM to extract meaningful keywords from the abstract of a paper and then retrieves potentially relevant papers by querying an external knowledge base. Additionally, we study a prompting-based re-ranking mechanism with attribution and show that re-ranking doubles the normalized recall compared to naive search methods, while providing insights into the LLM's decision-making process. In the generation phase, we propose a two-step approach that first outlines a plan for the review and then executes steps in the plan to generate the actual review. To evaluate different LLM-based literature review methods, we create test sets from arXiv papers using a protocol designed for rolling use with newly released LLMs to avoid test set contamination in zero-shot evaluations. We release this evaluation protocol to promote additional research and development in this regard. Our empirical results suggest that LLMs show promising potential for writing literature reviews when the task is decomposed into smaller components of retrieval and planning. Further, we demonstrate that our planning-based approach achieves higher-quality reviews by minimizing hallucinated references in the generated review by 18-26% compared to existing simpler LLM-based generation methods.
FM2DS: Few-Shot Multimodal Multihop Data Synthesis with Knowledge Distillation for Question Answering
Dec 09, 2024



Multimodal multihop question answering is a complex task that requires reasoning over multiple sources of information, such as images and text, to answer questions. While there has been significant progress in visual question answering, the multihop setting remains unexplored due to the lack of high-quality datasets. Current methods focus on single-hop question answering or a single modality, which makes them unsuitable for real-world scenarios such as analyzing multimodal educational materials, summarizing lengthy academic articles, or interpreting scientific studies that combine charts, images, and text. To address this gap, we propose a novel methodology, introducing the first framework for creating a high-quality dataset that enables training models for multimodal multihop question answering. Our approach consists of a 5-stage pipeline that involves acquiring relevant multimodal documents from Wikipedia, synthetically generating high-level questions and answers, and validating them through rigorous criteria to ensure quality data. We evaluate our methodology by training models on our synthesized dataset and testing on two benchmarks, our results demonstrate that, with an equal sample size, models trained on our synthesized data outperform those trained on human-collected data by 1.9 in exact match (EM) on average. We believe our data synthesis method will serve as a strong foundation for training and evaluating multimodal multihop question answering models.
MixSumm: Topic-based Data Augmentation using LLMs for Low-resource Extractive Text Summarization
Jul 10, 2024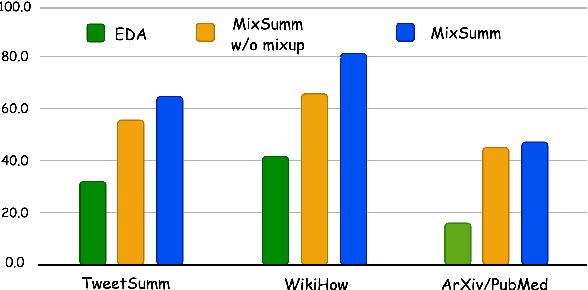
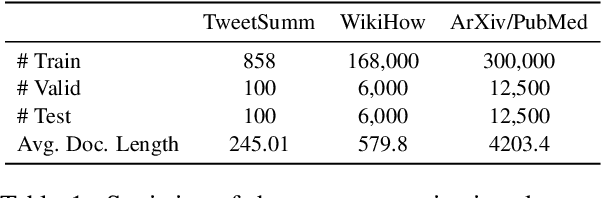

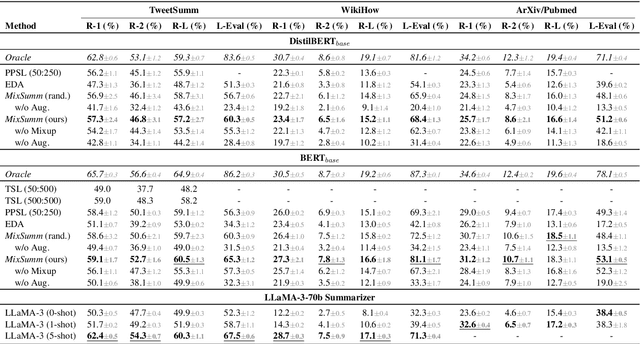
Low-resource extractive text summarization is a vital but heavily underexplored area of research. Prior literature either focuses on abstractive text summarization or prompts a large language model (LLM) like GPT-3 directly to generate summaries. In this work, we propose MixSumm for low-resource extractive text summarization. Specifically, MixSumm prompts an open-source LLM, LLaMA-3-70b, to generate documents that mix information from multiple topics as opposed to generating documents without mixup, and then trains a summarization model on the generated dataset. We use ROUGE scores and L-Eval, a reference-free LLaMA-3-based evaluation method to measure the quality of generated summaries. We conduct extensive experiments on a challenging text summarization benchmark comprising the TweetSumm, WikiHow, and ArXiv/PubMed datasets and show that our LLM-based data augmentation framework outperforms recent prompt-based approaches for low-resource extractive summarization. Additionally, our results also demonstrate effective knowledge distillation from LLaMA-3-70b to a small BERT-based extractive summarizer.
BlockLLM: Memory-Efficient Adaptation of LLMs by Selecting and Optimizing the Right Coordinate Blocks
Jun 25, 2024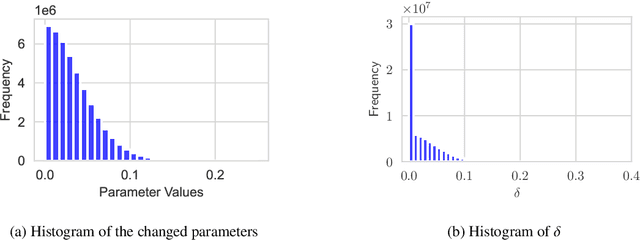
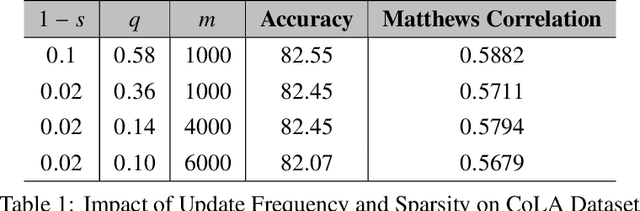

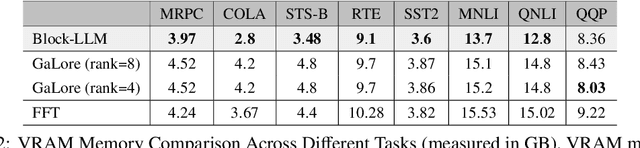
Training large language models (LLMs) for pretraining or adapting to new tasks and domains has become increasingly critical as their applications expand. However, as the model and the data sizes grow, the training process presents significant memory challenges, often requiring a prohibitive amount of GPU memory that may not be readily available. Existing methods such as low-rank adaptation (LoRA) add trainable low-rank matrix factorizations, altering the training dynamics and limiting the model's parameter search to a low-rank subspace. GaLore, a more recent method, employs Gradient Low-Rank Projection to reduce the memory footprint, in the full parameter training setting. However GaLore can only be applied to a subset of the LLM layers that satisfy the "reversibility" property, thus limiting their applicability. In response to these challenges, we introduce BlockLLM, an approach inspired by block coordinate descent. Our method carefully selects and updates a very small subset of the trainable parameters without altering any part of its architecture and training procedure. BlockLLM achieves state-of-the-art performance in both finetuning and pretraining tasks, while reducing the memory footprint of the underlying optimization process. Our experiments demonstrate that fine-tuning with only less than 5% of the parameters, BlockLLM achieves state-of-the-art perplexity scores on the GLUE benchmarks. On Llama model pretrained on C4 dataset, BlockLLM is able to train with significantly less memory than the state-of-the-art, while still maintaining competitive performance.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Mar 12, 2024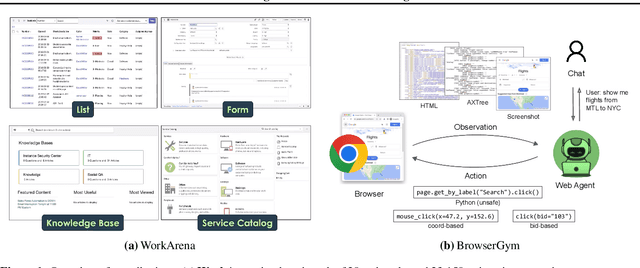
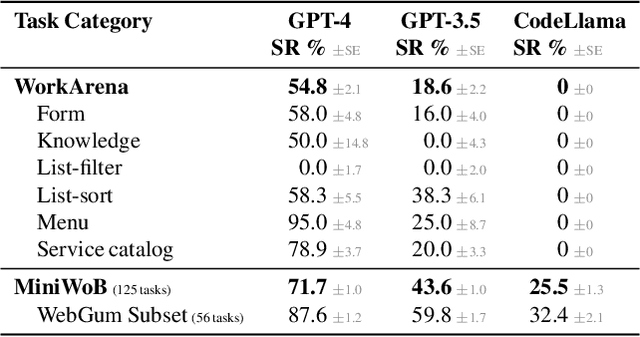

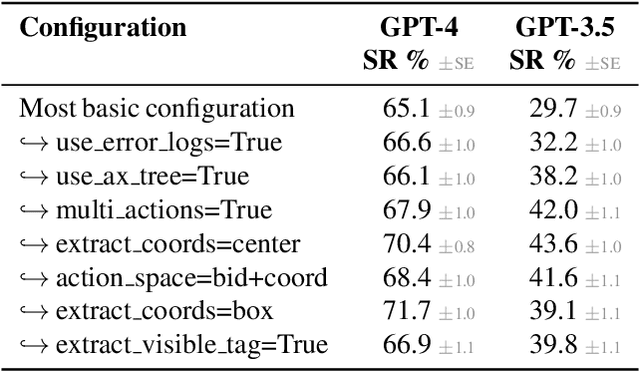
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 29 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
LitLLM: A Toolkit for Scientific Literature Review
Feb 02, 2024



Conducting literature reviews for scientific papers is essential for understanding research, its limitations, and building on existing work. It is a tedious task which makes an automatic literature review generator appealing. Unfortunately, many existing works that generate such reviews using Large Language Models (LLMs) have significant limitations. They tend to hallucinate-generate non-actual information-and ignore the latest research they have not been trained on. To address these limitations, we propose a toolkit that operates on Retrieval Augmented Generation (RAG) principles, specialized prompting and instructing techniques with the help of LLMs. Our system first initiates a web search to retrieve relevant papers by summarizing user-provided abstracts into keywords using an off-the-shelf LLM. Authors can enhance the search by supplementing it with relevant papers or keywords, contributing to a tailored retrieval process. Second, the system re-ranks the retrieved papers based on the user-provided abstract. Finally, the related work section is generated based on the re-ranked results and the abstract. There is a substantial reduction in time and effort for literature review compared to traditional methods, establishing our toolkit as an efficient alternative. Our open-source toolkit is accessible at https://github.com/shubhamagarwal92/LitLLM and Huggingface space (https://huggingface.co/spaces/shubhamagarwal92/LitLLM) with the video demo at https://youtu.be/E2ggOZBAFw0.
StarVector: Generating Scalable Vector Graphics Code from Images
Dec 17, 2023


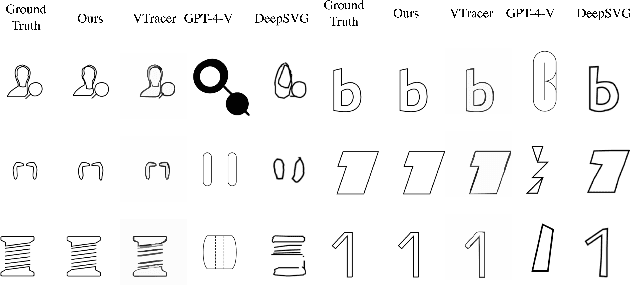
Scalable Vector Graphics (SVGs) have become integral in modern image rendering applications due to their infinite scalability in resolution, versatile usability, and editing capabilities. SVGs are particularly popular in the fields of web development and graphic design. Existing approaches for SVG modeling using deep learning often struggle with generating complex SVGs and are restricted to simpler ones that require extensive processing and simplification. This paper introduces StarVector, a multimodal SVG generation model that effectively integrates Code Generation Large Language Models (CodeLLMs) and vision models. Our approach utilizes a CLIP image encoder to extract visual representations from pixel-based images, which are then transformed into visual tokens via an adapter module. These visual tokens are pre-pended to the SVG token embeddings, and the sequence is modeled by the StarCoder model using next-token prediction, effectively learning to align the visual and code tokens. This enables StarVector to generate unrestricted SVGs that accurately represent pixel images. To evaluate StarVector's performance, we present SVG-Bench, a comprehensive benchmark for evaluating SVG methods across multiple datasets and relevant metrics. Within this benchmark, we introduce novel datasets including SVG-Stack, a large-scale dataset of real-world SVG examples, and use it to pre-train StarVector as a large foundation model for SVGs. Our results demonstrate significant enhancements in visual quality and complexity handling over current methods, marking a notable advancement in SVG generation technology. Code and models: https://github.com/joanrod/star-vector
LLM aided semi-supervision for Extractive Dialog Summarization
Nov 23, 2023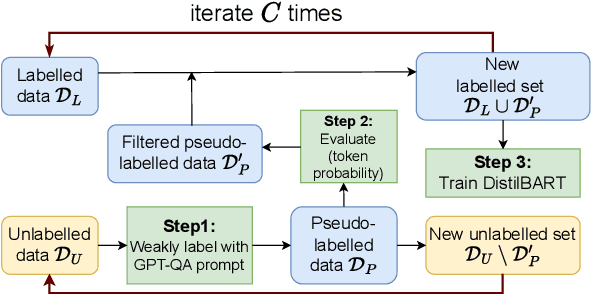
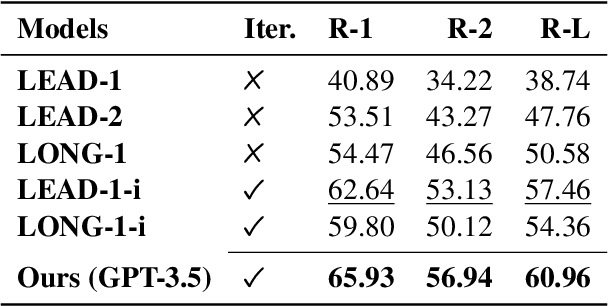
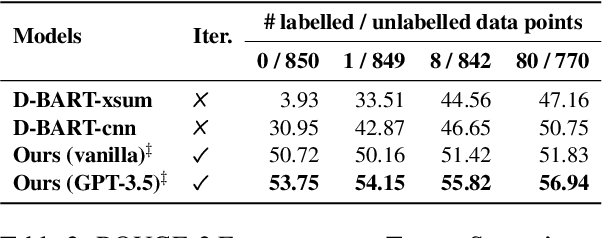

Generating high-quality summaries for chat dialogs often requires large labeled datasets. We propose a method to efficiently use unlabeled data for extractive summarization of customer-agent dialogs. In our method, we frame summarization as a question-answering problem and use state-of-the-art large language models (LLMs) to generate pseudo-labels for a dialog. We then use these pseudo-labels to fine-tune a chat summarization model, effectively transferring knowledge from the large LLM into a smaller specialized model. We demonstrate our method on the \tweetsumm dataset, and show that using 10% of the original labelled data set we can achieve 65.9/57.0/61.0 ROUGE-1/-2/-L, whereas the current state-of-the-art trained on the entire training data set obtains 65.16/55.81/64.37 ROUGE-1/-2/-L. In other words, in the worst case (i.e., ROUGE-L) we still effectively retain 94.7% of the performance while using only 10% of the data.