 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartGaze: Enhancing Chart Understanding in LVLMs with Eye-Tracking Guided Attention Refinement
Sep 16, 2025Charts are a crucial visual medium for communicating and representing information. While Large Vision-Language Models (LVLMs) have made progress on chart question answering (CQA), the task remains challenging, particularly when models attend to irrelevant regions of the chart. In this work, we present ChartGaze, a new eye-tracking dataset that captures human gaze patterns during chart reasoning tasks. Through a systematic comparison of human and model attention, we find that LVLMs often diverge from human gaze, leading to reduced interpretability and accuracy. To address this, we propose a gaze-guided attention refinement that aligns image-text attention with human fixations. Our approach improves both answer accuracy and attention alignment, yielding gains of up to 2.56 percentage points across multiple models. These results demonstrate the promise of incorporating human gaze to enhance both the reasoning quality and interpretability of chart-focused LVLMs.
AgentAda: Skill-Adaptive Data Analytics for Tailored Insight Discovery
Apr 10, 2025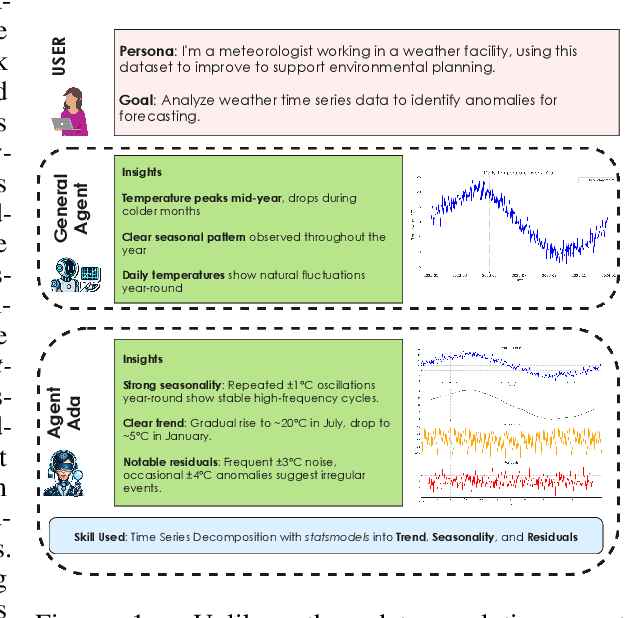

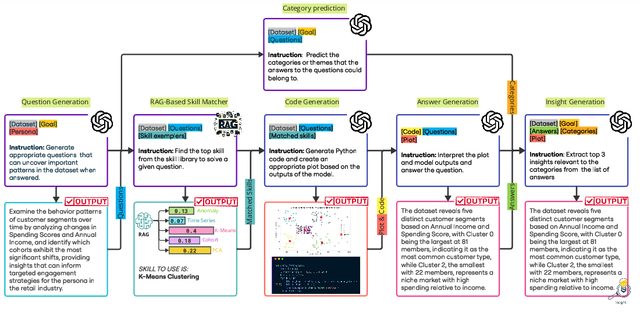
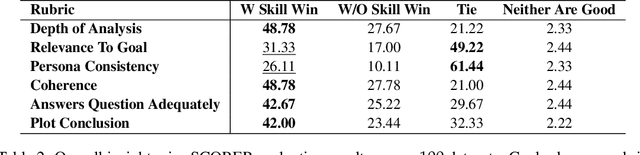
We introduce AgentAda, the first LLM-powered analytics agent that can learn and use new analytics skills to extract more specialized insights. Unlike existing methods that require users to manually decide which data analytics method to apply, AgentAda automatically identifies the skill needed from a library of analytical skills to perform the analysis. This also allows AgentAda to use skills that existing LLMs cannot perform out of the box. The library covers a range of methods, including clustering, predictive modeling, and NLP techniques like BERT, which allow AgentAda to handle complex analytics tasks based on what the user needs. AgentAda's dataset-to-insight extraction strategy consists of three key steps: (I) a question generator to generate queries relevant to the user's goal and persona, (II) a hybrid Retrieval-Augmented Generation (RAG)-based skill matcher to choose the best data analytics skill from the skill library, and (III) a code generator that produces executable code based on the retrieved skill's documentation to extract key patterns. We also introduce KaggleBench, a benchmark of curated notebooks across diverse domains, to evaluate AgentAda's performance. We conducted a human evaluation demonstrating that AgentAda provides more insightful analytics than existing tools, with 48.78% of evaluators preferring its analyses, compared to 27.67% for the unskilled agent. We also propose a novel LLM-as-a-judge approach that we show is aligned with human evaluation as a way to automate insight quality evaluation at larger scale.
StarFlow: Generating Structured Workflow Outputs From Sketch Images
Mar 27, 2025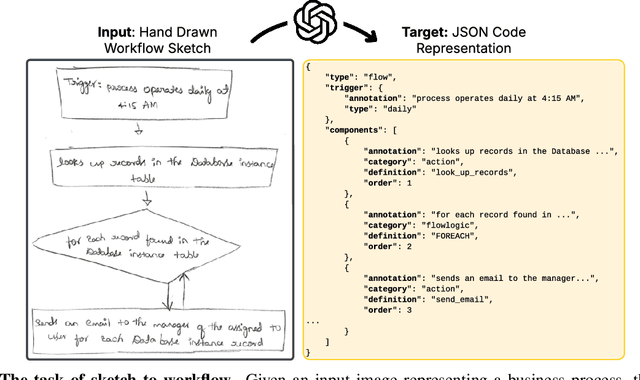


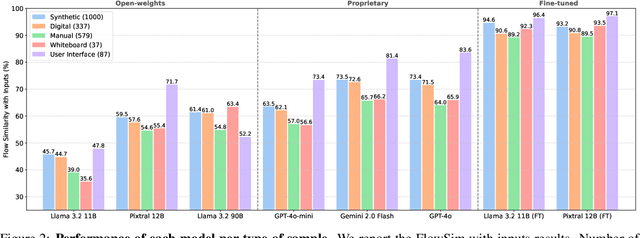
Workflows are a fundamental component of automation in enterprise platforms, enabling the orchestration of tasks, data processing, and system integrations. Despite being widely used, building workflows can be complex, often requiring manual configuration through low-code platforms or visual programming tools. To simplify this process, we explore the use of generative foundation models, particularly vision-language models (VLMs), to automatically generate structured workflows from visual inputs. Translating hand-drawn sketches or computer-generated diagrams into executable workflows is challenging due to the ambiguity of free-form drawings, variations in diagram styles, and the difficulty of inferring execution logic from visual elements. To address this, we introduce StarFlow, a framework for generating structured workflow outputs from sketches using vision-language models. We curate a diverse dataset of workflow diagrams -- including synthetic, manually annotated, and real-world samples -- to enable robust training and evaluation. We finetune and benchmark multiple vision-language models, conducting a series of ablation studies to analyze the strengths and limitations of our approach. Our results show that finetuning significantly enhances structured workflow generation, outperforming large vision-language models on this task.
FM2DS: Few-Shot Multimodal Multihop Data Synthesis with Knowledge Distillation for Question Answering
Dec 09, 2024



Multimodal multihop question answering is a complex task that requires reasoning over multiple sources of information, such as images and text, to answer questions. While there has been significant progress in visual question answering, the multihop setting remains unexplored due to the lack of high-quality datasets. Current methods focus on single-hop question answering or a single modality, which makes them unsuitable for real-world scenarios such as analyzing multimodal educational materials, summarizing lengthy academic articles, or interpreting scientific studies that combine charts, images, and text. To address this gap, we propose a novel methodology, introducing the first framework for creating a high-quality dataset that enables training models for multimodal multihop question answering. Our approach consists of a 5-stage pipeline that involves acquiring relevant multimodal documents from Wikipedia, synthetically generating high-level questions and answers, and validating them through rigorous criteria to ensure quality data. We evaluate our methodology by training models on our synthesized dataset and testing on two benchmarks, our results demonstrate that, with an equal sample size, models trained on our synthesized data outperform those trained on human-collected data by 1.9 in exact match (EM) on average. We believe our data synthesis method will serve as a strong foundation for training and evaluating multimodal multihop question answering models.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
BCAmirs at SemEval-2024 Task 4: Beyond Words: A Multimodal and Multilingual Exploration of Persuasion in Memes
Apr 03, 2024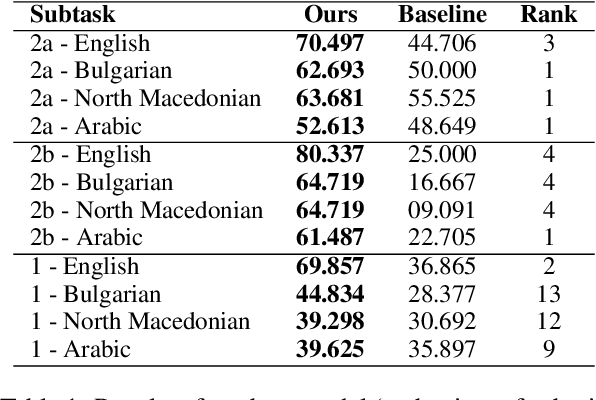

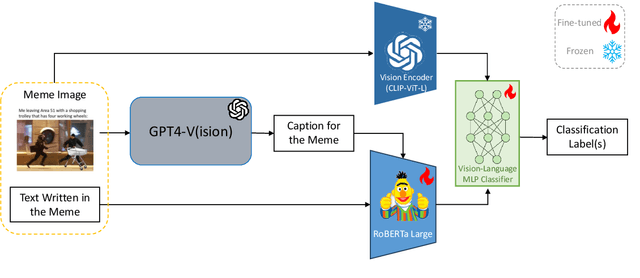
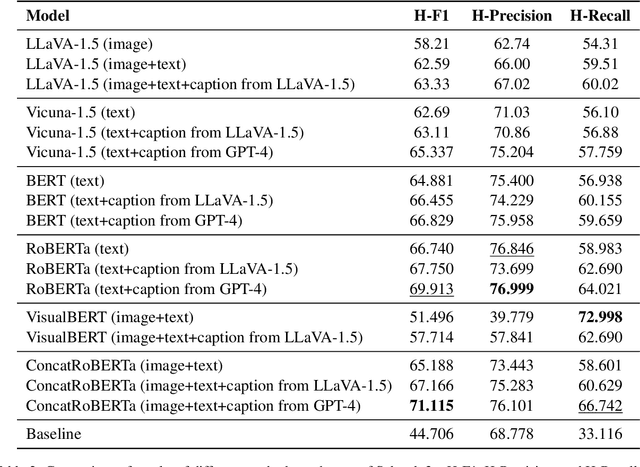
Memes, combining text and images, frequently use metaphors to convey persuasive messages, shaping public opinion. Motivated by this, our team engaged in SemEval-2024 Task 4, a hierarchical multi-label classification task designed to identify rhetorical and psychological persuasion techniques embedded within memes. To tackle this problem, we introduced a caption generation step to assess the modality gap and the impact of additional semantic information from images, which improved our result. Our best model utilizes GPT-4 generated captions alongside meme text to fine-tune RoBERTa as the text encoder and CLIP as the image encoder. It outperforms the baseline by a large margin in all 12 subtasks. In particular, it ranked in top-3 across all languages in Subtask 2a, and top-4 in Subtask 2b, demonstrating quantitatively strong performance. The improvement achieved by the introduced intermediate step is likely attributable to the metaphorical essence of images that challenges visual encoders. This highlights the potential for improving abstract visual semantics encoding.
Benchmarking Large Language Models for Persian: A Preliminary Study Focusing on ChatGPT
Apr 03, 2024



This paper explores the efficacy of large language models (LLMs) for Persian. While ChatGPT and consequent LLMs have shown remarkable performance in English, their efficiency for more low-resource languages remains an open question. We present the first comprehensive benchmarking study of LLMs across diverse Persian language tasks. Our primary focus is on GPT-3.5-turbo, but we also include GPT-4 and OpenChat-3.5 to provide a more holistic evaluation. Our assessment encompasses a diverse set of tasks categorized into classic, reasoning, and knowledge-based domains. To enable a thorough comparison, we evaluate LLMs against existing task-specific fine-tuned models. Given the limited availability of Persian datasets for reasoning tasks, we introduce two new benchmarks: one based on elementary school math questions and another derived from the entrance exams for 7th and 10th grades. Our findings reveal that while LLMs, especially GPT-4, excel in tasks requiring reasoning abilities and a broad understanding of general knowledge, they often lag behind smaller pre-trained models fine-tuned specifically for particular tasks. Additionally, we observe improved performance when test sets are translated to English before inputting them into GPT-3.5. These results highlight the significant potential for enhancing LLM performance in the Persian language. This is particularly noteworthy due to the unique attributes of Persian, including its distinct alphabet and writing styles.
uTeBC-NLP at SemEval-2024 Task 9: Can LLMs be Lateral Thinkers?
Apr 03, 2024



Inspired by human cognition, Jiang et al.(2023c) create a benchmark for assessing LLMs' lateral thinking-thinking outside the box. Building upon this benchmark, we investigate how different prompting methods enhance LLMs' performance on this task to reveal their inherent power for outside-the-box thinking ability. Through participating in SemEval-2024, task 9, Sentence Puzzle sub-task, we explore prompt engineering methods: chain of thoughts (CoT) and direct prompting, enhancing with informative descriptions, and employing contextualizing prompts using a retrieval augmented generation (RAG) pipeline. Our experiments involve three LLMs including GPT-3.5, GPT-4, and Zephyr-7B-beta. We generate a dataset of thinking paths between riddles and options using GPT-4, validated by humans for quality. Findings indicate that compressed informative prompts enhance performance. Dynamic in-context learning enhances model performance significantly. Furthermore, fine-tuning Zephyr on our dataset enhances performance across other commonsense datasets, underscoring the value of innovative thinking.
LM-CPPF: Paraphrasing-Guided Data Augmentation for Contrastive Prompt-Based Few-Shot Fine-Tuning
Jun 13, 2023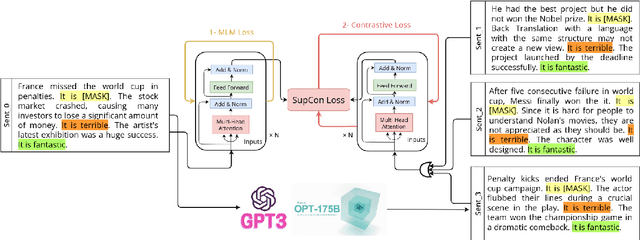
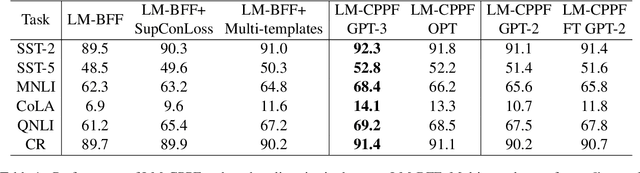

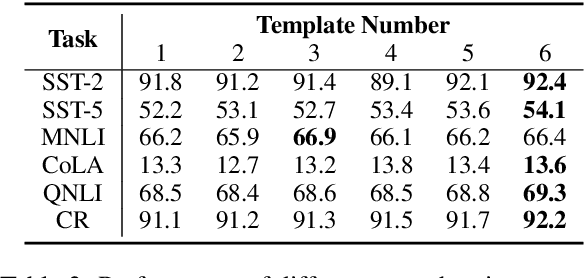
In recent years, there has been significant progress in developing pre-trained language models for NLP. However, these models often struggle when fine-tuned on small datasets. To address this issue, researchers have proposed various adaptation approaches. Prompt-based tuning is arguably the most common way, especially for larger models. Previous research shows that adding contrastive learning to prompt-based fine-tuning is effective as it helps the model generate embeddings that are more distinguishable between classes, and it can also be more sample-efficient as the model learns from positive and negative examples simultaneously. One of the most important components of contrastive learning is data augmentation, but unlike computer vision, effective data augmentation for NLP is still challenging. This paper proposes LM-CPPF, Contrastive Paraphrasing-guided Prompt-based Fine-tuning of Language Models, which leverages prompt-based few-shot paraphrasing using generative language models, especially large language models such as GPT-3 and OPT-175B, for data augmentation. Our experiments on multiple text classification benchmarks show that this augmentation method outperforms other methods, such as easy data augmentation, back translation, and multiple templates.
PEACH: Pre-Training Sequence-to-Sequence Multilingual Models for Translation with Semi-Supervised Pseudo-Parallel Document Generation
Apr 14, 2023Multilingual pre-training significantly improves many multilingual NLP tasks, including machine translation. Most existing methods are based on some variants of masked language modeling and text-denoising objectives on monolingual data. Multilingual pre-training on monolingual data ignores the availability of parallel data in many language pairs. Also, some other works integrate the available human-generated parallel translation data in their pre-training. This kind of parallel data is definitely helpful, but it is limited even in high-resource language pairs. This paper introduces a novel semi-supervised method, SPDG, that generates high-quality pseudo-parallel data for multilingual pre-training. First, a denoising model is pre-trained on monolingual data to reorder, add, remove, and substitute words, enhancing the pre-training documents' quality. Then, we generate different pseudo-translations for each pre-training document using dictionaries for word-by-word translation and applying the pre-trained denoising model. The resulting pseudo-parallel data is then used to pre-train our multilingual sequence-to-sequence model, PEACH. Our experiments show that PEACH outperforms existing approaches used in training mT5 and mBART on various translation tasks, including supervised, zero- and few-shot scenarios. Moreover, PEACH's ability to transfer knowledge between similar languages makes it particularly useful for low-resource languages. Our results demonstrate that with high-quality dictionaries for generating accurate pseudo-parallel, PEACH can be valuable for low-resource languages.